一种免疫球蛋白结合蛋白突变体及其用途的制作方法
本发明涉及生物技术领域,更具体地本发明涉及一种免疫球蛋白结合蛋白突变体及其应用。本发明涉及的一种免疫球蛋白结合蛋白突变体,通过对天然葡萄球菌蛋白A(SpA)的E结构域氨基酸进行定点突变而获得,与免疫球蛋白分子的除互补决定区(CDR)之外的其他区域结合,并将其制备成用于免疫球蛋白亲和层析的层析介质,用于免疫球蛋白的分离、纯化。
背景技术:
葡萄球菌蛋白A(Staphylococal Protein A,SpA)是一种从金黄色葡萄球菌细胞壁分离的蛋白质。1947年,Vevwey发现在某些金黄色葡萄球菌中,含有一种物质,在双向扩散试验中,能与正常人血清形成沉淀。Jensen(1959)也发现了类似现象,将其命名为A抗原。1963年Lofkvist等分离了A抗原,并证明它是一种蛋白质,且与糖有区别。Grov (1960)将其命名为葡萄球菌蛋白A,简称SpA蛋白A (ProteinA)。编码SpA的基因于1983年被克隆并在大肠杆菌中表达。对SPA结构和功能的研究发现,SpA分子包含A,B,C,D,E五个同源结构域,每个结构域都有能与IgG自主结合的能力。在中性pH条件下,蛋白A捕获免疫球蛋白分子,在低pH条件下将其释放出来。因此,以SpA作为配体的亲和层析已经成为目前分离、纯化治疗性单克隆抗体重要手段之一。
蛋白A亲和层析是治疗性单克隆抗体下游纯化的第一步,待纯化的培养上清中含有大量生物大分子杂质,每次或数次纯化循环后,必须经过在位清洗,否则层析介质的性能将显著下降。为了延长层析柱的寿命和确保纯化质量,必须定期对层析柱进行在位清洗(CIP),最理想的CIP条件是使用0.5M的氢氧化钠溶液,以较低的流速清洗15-20分钟。但天然或重组的SpA配基对NaOH非常敏感,强碱性条件下易变性或脱落,如果选用高浓度的盐酸胍或尿素进行清洗,清洗的效果远远不如NaOH清洗效果好,而且清洗成本非常高,不适用于单克隆抗体的产业化生产。
层析介质中蛋白A变性及脱落,是由于蛋白A在碱性条件下,天冬酰胺(Asn)和谷氨酰胺(Gln)发生脱氨基反应,造成肽链断裂。易发生脱氨基的氨基酸中,天冬酰胺(Asn)比Gln对碱性条件更敏感。脱氨基反应速率最快的是当肽链中含有天冬酰胺(Asn)与甘氨酸(Gly)结合或天冬酰胺(Asn)和丝氨酸(Ser)结合的序列。由于“天冬酰胺-甘氨酸”序列对于碱性是最敏感的,SpA结构域中E含有“天冬酰胺-甘氨酸”序列(N28-G29),因此推测其耐碱性最差。目前的耐碱性SpA序列的突变主要集中在B、C结构域,如目前应用较广泛的耐碱性SpA亲和介质Mabselect SuRe,采用的是SpA结构域B进行天冬酰胺的定点突变,将第23位的天冬酰胺突变为苏氨酸(N23T)。
此外,发明专利(申请号CN03806793.5)公开了,利用对SpA的结构域B 序列使用附近突变技术(“by pass”)进行定点突变(N23T,N43E),以提高其耐碱性。发明专利(申请号201310097553.9)公开了,利用SpA结构域B序列进行定点突变(N23T,F30A)以提高其耐碱性。此外,发明专利(申请号CN200780036281.4)公开了对结构域C序列野生型(Cwt)及缺失了“Asn-Lys-Phe-Asn”突变体(Cdel)获得了与MabselectSure相当的耐碱性。
在单克隆抗体分离纯化过程中,目前使用的ProteinA介质存在着耐碱性差的问题。Protein A介质经过多次碱性清洗后,动态吸附载量下降、纯化效率降低。本发明通过对天然Protein A的E结构域进行定点突变E(N23T,N28D,G29A),该突变体与现有技术相比,其耐碱性、动态吸附载量及纯化效果等均显著提高。
技术实现要素:
本发明涉及的一种免疫球蛋白结合蛋白突变体,其氨基酸序列来源于天然葡萄球菌蛋白A(SpA)的E结构域。通过对其氨基酸序列中“碱敏感”的天冬酰胺进行定点突变,使其突变体较亲本分子相比具有更高的耐碱性,且该突变体对免疫球蛋白的亲和力显著提高。
本发明所述的一种免疫球蛋白结合蛋白突变体,利用天然葡萄球菌蛋白A的E结构域,将其E结构域中部分氨基酸进行突变,如N11S,N21A,N23T,N28D,N28A,G29A,N43E,N52A;及突变点的组合突变,如E(N23T,N28D),E(N23T,N28A),E(N23T,N43E),E(N28D,N43E),E(N32T,N28D,G29A)等。经过活性测试、耐碱性测试及亲和力测试等大量实验验证,其中优选实施例为将其第23位天冬酰胺突变为苏氨酸,第28位天冬酰胺突变为天冬氨酸,第29位甘氨酸突变为丙氨酸(N23T,N28D,G29A)。
将优选的免疫球蛋白结合蛋白突变体利用基因工程技术发酵培养、分离纯化,获得具有较高免疫球蛋白亲和力、耐碱性强的免疫球蛋白结合蛋白分子,将该结合蛋白分子利用亲和层析介质制备方法制备成用于免疫球蛋白亲和层析的层析介质,该层析介质与现有市场化的层析介质相比,其耐碱性、动态吸附载量机纯化效果均显著提高。
附图说明
图1、BL21/pET32a上清液SDS-PAGE电泳图。
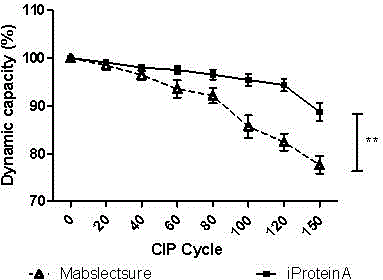
图2、i Protein A与MabslectSure 性能比较图。
具体实施方式
实施例1、天然SpA的耐碱性突变点选择
天然SpAD 耐碱性取决于其氨基酸序列,一般认为,在碱性条件下,发生在天冬酰胺(Asn)和谷氨酰胺(Gln)的脱氨基反应是造成肽链断裂的重要原因。而且脱氨基反应速率最快的是当肽链中含有天冬酰胺(Asn)与甘氨酸(Gly)结合或天冬酰胺(Asn)和丝氨酸(Ser)结合的序列。而SpA与IgG的亲和力取决于多肽和蛋白质的构象。
SpA不同结构域的氨基酸序列分析见下表1。
表1、SpA不同结构域的氨基酸序列分析
选取含天冬酰胺残基较少的E结构域作为突变模板,与以往SpA突变常用的“by pass”策略不同,对E结构域直接进行定点突变。突变目标氨基酸首选其他结构域相应位点的天然氨基酸(如Ser,Glu),若此位点不含天然氨基酸则选用丙氨酸(Ala)。 对于此前报道不适合定点突变的N28,使用与之结构类似的天冬氨酸进行代替。针对SpA结构域E的定点突变见下表2。
表2、SpA结构域E的定点突变
实施例2、含结构域E突变体的制备
(1)含结构域E突变体的载体构建
人工合成表1中的各种突变体基因序列。与经NcoI及BamHI酶切的载体pET32a连接,转化大肠杆菌(BL21/DE3),筛选具有氨苄青霉素抗性的转化子,经质粒提取,酶切鉴定后证明结构域E突变体基因克隆至pET32a中。
(2)含结构E突变体的菌种构建与发酵
用CaCl2法将pET32a-P转化大肠杆菌BL21 /DE3,在含有氨苄青霉素的LB平板上筛选转化子,经质粒检测和酶切分析获得含有pET32a的重组转化子(BL21/pET32a)。挑取大肠杆菌工程菌BL21 /pET32a,接种于LB培养基中,接种量1~2%V/V,于30℃培养过夜,次日在无菌条件下将上述培养好的种子培养基按l: 10-1: 5接种于发酵培养基上,30℃发酵至OD600达到0.4~0.8,升温至42℃诱导,5小时后收离心收菌。
取少量细胞加2X上样缓冲液,按标准做SDS-PAGE凝胶电泳,图1显示,经诱导的BL21/pET32a的碎菌后的上清在20kD的位置出现一条新的蛋白带(左二),转化PET32空载体的BL21 /DE3菌和经诱导的BL21/pET32a碎菌后的沉淀中不出现次带,证明重组蛋白ProteinA已在BL21/pET32a中诱导表达。(图1各泳道分别为:marker,诱导后上清液,诱导前上清液)。
(3)结构域E突变体纯化
将上述收集菌体用NaCl十磷酸盐缓冲液(pH7. 0~8. 0)悬浮,超声破碎,4 ℃离心,收集上清得粗提液。经Ni Sepharose 6FF纯化带有his标签的突变体蛋白。再使用EK酶酶切除去突变体蛋白的His纯化标签。
实验例1、结构域E突变体的结合活性
为验证定点突变后的SpA结构域E突变体仍具有与人IgG结合能力。采用表面等离子技术测定使用上述突变体与人IgG抗体的结合活性。利用Biacore 2000(Uppsala, Sweden),将人的多克隆IgG和HAS(阴性参照)偶联在CMS传感器芯片(Biacore)。以10种不同的浓度(100-550nM)在HBS (10 mM HEPES,0. 15M NaCl,3. 4 mM EDTA,0. 005%表面活性剂P20,pH 7. 4)中制备重组蛋白A突变体溶液。以随机顺序和30 ul/min的流速将样品注射到表面作为复制本,使用10 mM的HCl再生表面。利用BIA 3. 0. 2 b软件分析数据。利用兰格谬尔模型并计算表观动力学常数和亲和性常数(如表3 所示)。与其他突变体相比,E(N23T,N28D,G29A)与IgG有较高的亲和力,E(N23T,N28D,G29A)具有SEQ ID NO:1所示的氨基酸序列,SEQ ID NO:2 所示的核苷酸序列。
表3、利用Biacore对SpA结构域E突变体进行结合活性测定
实验例2、结构域E突变体耐碱性研究
为了考察不同E结构域突变体的耐碱性,按照下列步骤,制备不同E突变体琼脂糖凝胶,并填充至亲和层析柱中,按照标准的IgG纯化程序考察其动态载量变化。结果(表4)显示,E(N23T,N28D,G29A)经过7次CIP (7hour)后,其动态载量仍维持在95%,远优于其他E结构域的突变体。
1、E结构域突变体琼脂糖凝胶的制备:
1)用环氧氯丙烷、氢氧化钠与琼脂糖凝胶在水介质中进行反应,在30-60℃的温度下反应2-3小时,反应结束后用蒸馏水清洗至中性后抽干溶剂
2)将上述产物与本发明的重组蛋白A在5-25 ℃温度下反应15-20小时,反应烷后清洗再抽干溶剂,即得到重组蛋白A琼脂糖凝胶
3)将上述装填至20mL(XK/16/20)10cm高柱中,用于后续实验。
2、标准化的IgG纯化色谱洗脱程序:
1)结合液清洗平衡亲和层析色谱柱
2)0.2ml/min上样,样品为10mg/ml人多克隆IgG,上样量为20CV(柱体积)
3)结合缓冲液清洗未结合的免疫球蛋白,用量为6CV
4)洗脱缓冲液1.0ml/min进行洗脱,用量为6 CV
5)结合缓冲液对色谱柱进行平衡,用量为6 CV
6)使用CIP碱液进行在位清洗,柱基质与0.5M NaOH之间接触时间为30分钟。
3、所使用的缓冲液:
结合缓冲液配方:20mMPBS加150mM NaCl(0.92g NaH2PO4·2H2O,5.04g Na2HPO4·12H2O,8.77g NaCl,SuperQ水溶至1L,pH调至7.0);
洗脱液配方:柠檬酸3.8g,柠檬酸二钠0.82g,SuperQ水溶至1L,pH调至3.0。
CIP溶液:0.5M NaOH。
表4、不同结构域E突变体的碱稳定性研究
实验例3、新型耐碱性亲和介质(i Protein A)的性能研究
(1)E(N23T,N28D,G29A)四聚体琼脂糖凝胶(i Protein A)的制备
通过化学合成的方法,设计合成E(N23T,N28D,G29A)基因的四聚体重复片段的序列,按实施例1所述方法,表达、纯化上述E(N23T,N28D,G29A)四聚体蛋白。
按照上述实施例的制备方法制备E突变体(N23T,N28D,G29A)四聚体的琼脂糖凝胶。
(2)i Protein A亲和介质与MabselcetSure亲和介质的耐碱性比较
为进一步考察E(N23T,N28D,G29A)四聚体的耐碱性,使用MabselectSure预装柱(5ml)和iProteinA柱(XK165,装填量5ml),按下述方法进行IgG纯化,经过不同CIP循环测定色谱柱的动态载量。结果(表5)显示,i Protein A亲和介质与市售耐碱性亲和介质(MabselctSure)相比,具有更好的耐碱稳定性。结果见表5及图2。
标准化的IgG纯化层析色谱洗脱程序:
1)结合缓冲液平衡层析色谱柱
2)0.2ml/min上样,样品为10mg/ml人多克隆IgG,上样量为20CV(柱体积)
3)结合缓冲液清洗未结合蛋白,用量为6 CV
4)洗脱缓冲液1.0ml/min进行洗脱,用量为6 CV
5)结合缓冲液对色谱柱进行平衡,用量为6 CV
6)使用CIP碱液进行在位清洗,柱基质与0.5M NaOH之间接触时间为60min。
表5、i Protein A亲和介质与MabselctSure亲和介质的耐碱性比较
(3)i Protein A亲和介质与MabselcetSure动态载量和纯化效果性比较
根据实施例4.1中,利用第四十次CIP循环洗脱的IgG收液计算iProtein A和MabselctSure的动态载量。同时,对两种介质洗脱液中IgG纯度和聚体含量使用HPLC方法(TSKgel G3000SW色谱柱)进行分析,计算IgG单体纯度和聚体含量。结果(附表6)表明,iProteinA与MabselctSure相比,具有更好的动态载量和纯化效果。
此外,专利CN10152278(A)记载,结构域C序列野生型(Cwt)及缺失了“Asn-Lys-Phe-Asn”突变体(Cdel),仅仅获得与MabselectSure相当的耐碱性,且多次CIP后其动态载量低于MabselectSure。因此,本发明公开的i Protein A耐碱性及纯化效果同样优于Cwt与Cdel。
表6、i Protein A亲和介质与MabselectSure纯化效果性比较
SEQUENCE LISTING
<110> 上海张江生物技术有限公司
<120> 一种免疫球蛋白结合蛋白突变体及其用途
<130> 20150506
<160> 2
<170> PatentIn version 3.5
<210> 1
<211> 58
<212> PRT
<213> 人工序列
<400> 1
Asn Ala Ala Gln His Asp Glu Ala Gln Gln Asn Ala Phe Tyr Gln Val
1 5 10 15
Leu Asn Met Pro Asn Leu Thr Ala Asp Gln Arg Asp Ala Phe Ile Gln
20 25 30
Ser Leu Lys Asp Asp Pro Ser Gln Ser Ala Asn Val Leu Gly Glu Ala
35 40 45
Gln Lys Leu Asn Asp Ser Gln Ala Pro Lys
50 55
<210> 2
<211> 174
<212> DNA
<213> 人工序列
<400> 2
aacgcggcgc agcatgatga agcgcagcag aacgcgtttt atcaggtgct gaacatgccg 60
aacctgaccg cggatcagcg cgatgccttt attcagagcc tgaaagatga tccgagccag 120
agcgcgaacg tgctgggcga agcgcagaaa ctgaacgata gccaggcgcc gaaa 174
- 还没有人留言评论。精彩留言会获得点赞!