用以制备虾红素的重组多核苷酸序列及其应用的制作方法
本发明涉及生物合成虾红素(astaxanthin)。更具体来说,本发明涉及以生物方法合成虾红素或其前驱物或衍生物。
背景技术:
类胡萝卜素(carotenoids)是一种捕光色素(light harvesting pigments),可用以保护光合系统,避免过量光照所引起的光氧化伤害。在人体中,类胡萝卜素是可作为抗氧化剂的维生素A前驱物,已知可刺激免疫系统,保护个体抵抗诸如癌症等各式疾病。自然界存在着多种类胡萝卜素,包含虾红素、茄红素(lycopene)、β-胡萝卜素(β-carotene)、海胆酮(echinenone)、斑螯黄质(又名角黄素,canthaxanthin)和玉米黄质(zeaxanthin)。相较于其它种类的类胡萝卜素而言,虾红素具有更显著的抗氧化功效;因此,虾红素更具经济价值。可广泛应用于水产养殖、医疗保健产品、化妆品和食品工业等不同领域。
虾红素(又名虾青素,3,3'-二羟基-β-胡萝卜素-4,4'-二酮,3,3'-dihydroxy-β-carotene-4,4'-dione,图1)是一种类胡萝卜色素,赋予某些鸟类、甲壳类动物和鲑鱼独特的显色。虾红素的抗氧化力是维生素E的500倍以上,且是其它类胡萝卜素的10倍以上。已知氧化压力会导致风湿性关节炎、帕金森氏症、阿兹海默症、癌症和中风。许多研究指出,虾红素具有促进保健功效,不仅可用于预防且可治疗各式疾病,例如癌症、慢性发炎疾病、代谢症候群、糖尿病、糖尿病肾病变、心血管疾病、胃肠道疾病、肝脏疾病、神经退化性疾病、眼部疾病、皮肤疾病、运动性疲劳、雄性不孕症和氯化汞引发的急性肾衰竭,增强免疫力并减少罹患动脉粥状硬化的风险。
在各式类胡萝卜素产品中,虾红素是价格最高的产品。巿售虾红素多由化学方法合成(亦即,石化合成法),其商业用途主要是作为养殖鲑鱼和鳟鱼用的饲料添加剂。化学合成和天然合成的虾红素,虽具有大致相同的化学式,但二者的分子特性却截然不同;该不同之处赋予了天然虾红素较佳的安全性及抗氧化功效。此外,化学合成的虾红素在医药巿场上接受度很低,原因如下:
第一,几何异构物的形式会影响合成虾红素的吸收。化学合成的虾红素具有Z形式的构型(顺式异构型,cis-isomeric),该结构的虾红素无法被动物体吸收,因此,美国食品药物管理局(U.S.Food and Drug Administration,FDA)已禁止其贩卖使用(表1)。相较之下,98%的天然虾红素系为E形式的构型(反式异构型,trans-isomer)(表1)。
表1.不同来源的虾红素的几何异构物和立体异构物
GEM:遗传工程微生物
第二,虾红素具有三种构型异构体,其构型是利用分子结构中的二个氢氧基来区分,包含二种镜像异构物(enantiomer,即3R,3’R及3S,3’S)和一种内消旋型异构物(mesoform,即3R,3’S,图1),各异构物皆具有位于C-3和C-3’的二个手性中心。相较于3R,3’R立体异构物,3S,3’S立体异构物的抗氧化功效更为显著;3R,3’S内消旋型异构物则不具有任何抗氧化功效。化学合成虾红素通常是一种同时包含3S,3’S、3R,3’S及3R,3’R的混合物(比例约为1:2:1);相较之下,源自藻类的天然虾红素则主要为3S,3’S形式的立体异构物(表1)。
第三,游离形式(或称自由形式,free form)的合成虾红素非常容易进行氧化反应。天然虾红素常与蛋白质接合,或与一或二种脂肪酸产生酯化反应而形成单酯体(monoester)或双酯体(diester);酯化虾红素相较于游离形式更易被人体吸收。此外,源自藻类(例如雨生红球藻,Haematococcus pluvialis)的天然虾红素较于合成虾红素更适于作为自由基清除剂(free radical scavenger)和抗氧化剂。
虾红素为具有应用潜力的功能性食物和医药成分,并可做为水产养殖业的食用色素添加剂等。由于天然虾红素(特别是3S,3’S型的酯化虾红素)无法由化学合成所取代,科学和工业领域亟欲发展生物合成法,在一适当的生物反应器内建立一套类胡萝卜素的生合成方法,据以生产相关产品。本发明即是利用已知的类胡萝卜素生物合成路径(图2a及2b)来建立一可生产高价值虾红素(例如3S,3’S型的酯化虾红素)的生物细胞工厂。已知多种包含鲑鱼、虾、藻类、植物、红发夫酵母(Phaffia rhodozyma;Xanthophyllomyces dendrorhous)和基因工程微生物,皆可用以制备不同形式的虾红素及其衍生物。然而,该些生物工厂往往受限于宿主本身的生产条件,例如饲养于冷水的鱼和虾仅能产生低浓度的虾红素、植物系统则会进行非预期的酮化反应(ketolation)、红发夫酵母生产的最终产物抗氧化活性过低,以及饲养藻类时需要大土地面积和很长时间。
有鉴于此,相关领域亟需一种可用以稳定生物合成虾红素的新颖方法。
技术实现要素:
发明内容旨在提供本公开内容的简化摘要,以使阅读者对本公开内容具备基本的理解。此发明内容并非本公开内容的完整概述,且其用意并非在指出本发明实施例的重要/关键组件或界定本发明的范围。
本公开内容旨在提供一用以生物合成虾红素、虾红素前驱物或虾红素衍生物的重组多核苷酸序列、载体、宿主细胞及方法。基于虾红素和/或其前驱物或衍生物的抗氧化功效,本公开内容亦提供一种用以改善宿主细胞对压力的耐受性的方法,以及一种用以增加宿主细胞制备乙醇或浆果赤霉素III(baccatin III)的产量的方法。
本公开内容的第一方面是关于一种用以在宿主细胞中,制备虾红素或其前驱物或衍生物的重组多核苷酸序列。该重组多核苷酸序列包含四组基因组:(1)第一基因组,其系包含第一启动子及可操作式地连结至该第一启动子的第一核酸序列,其中该第一核酸序列系用以编码一焦磷酸香叶香叶酯合成酶(geranylgeranyl pyrophosphate synthase,GGPP synthase);(2)第二基因组,其系包含第二启动子及可操作式地连结至该第二启动子的第二核酸序列,其中该第二核酸序列系用以编码3-羟基-3-甲基戊二酰-辅酶A还原酶(3-hydroxy-3-methylglutaryl–coenzyme A reductase,HMG-CoA reductase,以下简称HMG-CoA还原酶);(3)第三基因组,其系包含第三启动子及可操作式地连结至该第三启动子的第三核酸序列,其中该第三核酸序列系用以编码八氢茄红素去饱合酶(phytoene desaturase);以及(4)第四基因组,其系包含第四启动子及可操作式地连结至该第四启动子的第四核酸序列,其中该第四核酸序列系用以编码具有八氢茄红素合成酶(phytoene synthase)和茄红素环化酶(lycopene cyclase)个别功能的双功能酶。所述重组多核苷酸序列中各基因组的3’端序列与位于其下游的下一组基因组的5’端序列彼此为相互同源序列,其顺序皆可调动。
依据本公开内容一实施方式,第一核酸序列为一包含序列编号:1的序列的crtE基因,第二核酸序列为包含序列编号:2的序列的HMG1基因,第三核酸序列为包含序列编号:3的序列的crtI基因,而第四核酸序列则为包含序列编号:4的序列的crtYB基因。
依据本公开内容某些实施方式,生物制成的虾红素是3S,3S’-虾红素。依据本公开内容其它实施方式,生物制成的虾红素是3R,3R’-虾红素。
依据本公开内容一实施方式,虾红素的前驱物可以是焦磷酸香叶香叶酯(geranylgeranyl-pyrophosphate,GGPP)、尼基叶黄素(phenicoxanthin)、茄红素(lycopene)、海胆酮(echinenone)、斑螯黄质(又名角黄素,canthaxanthin)、八氢西红柿红素(phytoene)、玉米黄质(zeaxanthin)、β-隐黄素(β-cryptoxanthin)或β-胡萝卜素(β-carotene)。依据本公开内容另一实施方式,虾红素的衍生物可以是虾红素单酯体(monoester)或虾红素双酯体(diester)。
在本公开内容某些实施方式中,重组多核苷酸序列进一步包含第五基因组和第六基因组。第五基因组包含第五启动子及可操作式地连结至该第五启动子的第五核酸序列,其中该第五核酸序列系用以编码β-胡萝卜素羟化酶(β-carotene hydroxylase)。第六基因组则包含第六启动子及一可操作式地连结至该第六启动子的第六核酸序列,其中该第六核酸序列系用以编码β-胡萝卜素酮醇酶(β-carotene ketolase)。
依据本公开内容一实施方式,第五核酸序列为包含序列编号:5、6或7的序列的chYb基因;而第六核酸序列则为包含序列编号:8的序列的bkt基因。
依据本公开内容的实施方式,第一至第六启动子系分别选自由ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子所组成的群组。较佳情况是,第一至第六启动子系为不同的启动子,其顺序皆可调动。
在本公开内容其它实施方式中,除了第一、第二、第三和第四基因组外,重组多核苷酸序列进一步包含第七基因组和第八基因组。第七基因组包含第七启动子及可操作式地连结至该第七启动子的第七核酸序列,其中该第七核酸序列系用以编码P450还原酶(P450reductase)。第八基因组包含第八启动子及可操作式地连结至该第八启动子的第八核酸序列,其中该第八核酸序列系用以编码β-胡萝卜素氧化酶(β-carotene oxygenase)。
依据本公开内容一实施方式,第七核酸序列为包含序列编号:9的序列的crtR基因;而第八核酸序列则为包含序列编号:10的序列的crtS基因。
依据本公开内容另一实施方式,第一、第二、第三、第四、第七和第八启动子系分别选自由ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子所组成的群组。较佳的情况是,第一、第二、第三、第四、第七和第八启动子系为不同的启动子,其顺序皆可调动。
在本公开内容某些实施方式中,重组多核苷酸序列进一步包含一筛选标记基因组,其系包含筛选标记启动子及可操作式地连结至该筛选标记启动子的筛选标记基因。
本公开内容的第二方面是关于一种用以在宿主细胞中,制备虾红素或其前驱物或衍生物的重组载体。该重组载体包含上述任一种重组多核苷酸序列,以及可操作式地连结至该重组多核苷酸序列的控制序列(control sequence),据以表达本发明重组多核苷酸序列。
本公开内容的第三方面是关于一种用以制备虾红素或其前驱物或衍生物的宿主细胞,其中该宿主细胞包含本公开内容所述的任一种重组多核苷酸序列或重组载体。因应不同的重组多核苷酸序列或重组载体,生物制成的虾红素可以是3S,3S’-虾红素或3R,3R’-虾红素。虾红素的前驱物可以是焦磷酸香叶香叶酯、尼基叶黄素、茄红素、海胆酮、斑螯黄质、八氢西红柿红素、玉米黄质、β-隐黄素或β-胡萝卜素。虾红素的衍生物可以是虾红素单酯体或虾红素双酯体。
在任选的实施方式中,宿主细胞可以是真核细胞或原核细胞。
本公开内容的第四方面是关于一种用以制备虾红素或其前驱物或衍生物的方法。依据更多的实施方式,本发明方法包含将上述宿主细胞培养于培养液中,其中该培养液包含一种选自由葡萄糖、半乳糖、甘油和脂肪酸所组成的群组的成分,藉以制备虾红素或其前驱物或衍生物。在一特定实施方式中,该培养液包含0.5-40%甘油(glycerol)。在另一特定实施方式中,该培养液包含0.001-5%脂肪酸,例如辛酸(octanoic acid)。
本公开内容的第五方面是关于一种用以改善宿主细胞对压力的耐受性的方法。该方法包含将本公开内容的重组多核苷酸序列和/或重组载体引入宿主细胞中。依据一实施方式,压力可以是来自于宿主细胞被暴露在乙醇、异丁醇(butanol)、紫外光照射、糠醛(furfural)或药物前驱物下所造成。依据一实施方式,该药物前驱物可以是10-去乙酰浆果赤霉素III(10-deacetyl baccatin III,10DB)。
本公开内容的第六方面则是关于一种用以增加宿主细胞制备乙醇或浆果赤霉素III的产量的方法。该方法包含将本公开内容的重组多核苷酸序列和/或重组载体引入宿主细胞中。
在参阅下文实施方式后,本发明所属技术领域中具有通常知识者当可轻易了解本发明的基本精神和其它发明目的,以及本发明所采用的技术手段与实施方式。
附图说明
为让本发明的上述与其它目的、特征、优点与实施例能更明显易懂,所附图说明如下:
图1是分别用以绘示3S,3’S-虾红素(上图)、3R,3’R-虾红素(中图)及3R,3’S-虾红素(下图)的化学结构示意图;
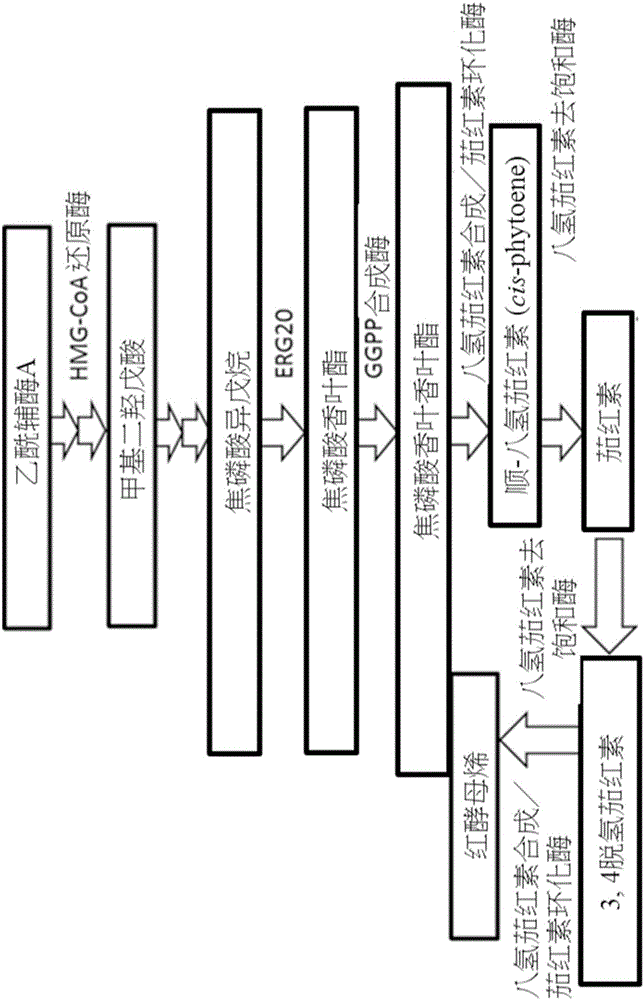
图2a和2b是用以绘示类胡萝卜素生物合成路径的示意图;
图3是关于本发明用以生物合成3S,3’S-虾红素的示意图;
图4a是依据本公开内容一实施例所绘示的序列比对数据,其系关于HMG-CoA还原酶(HMG-CoA reductase)的保留性区域(conserved region),并以底线标注其催化域(catalytic domain)1-6;其中,在图中7208代表由马克斯克鲁维酵母(Kluyveromyces marxianus)分离的HMG-CoA还原酶,P12683代表由啤酒酵母菌(Saccharomyces cerevisiae)分离的HMG-CoA还原酶,ACN40476代表由史特卡云杉(Picea sitchensis)分离的HMG-CoA还原酶,XP_001211323代表由土曲霉(Aspergillus terreus)分离的HMG-CoA还原酶,而ABY84848则代表由灵芝(Ganoderma lucidum)分离的HMG-CoA还原酶;
图4b是依据本公开内容一实施例所绘示的示意图,其系关于HMG-CoA还原酶的催化域1-6中的保留性残基,并以底线标注该些保留性残基;
图5a是依据本公开内容另一实施例所绘示的序列比对数据,其系关于焦磷酸香叶香叶酯合成酶(geranylgeranyl pyrophosphate synthase,GGPP synthase)的保留性区域,并以底线标注其催化域1-3;其中,AAY33921代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的焦磷酸香叶香叶酯合成酶,NP_624521代表由天蓝色链霉菌(Streptomyces coelicolor)分离的焦磷酸香叶香叶酯合成酶,BAB99565代表由谷氨酸棒状杆菌(Corynebacterium glutamicum)分离的焦磷酸香叶香叶酯合成酶,ZP_00056752代表由嗜高温放线菌(Thermobifida fusca)分离的焦磷酸香叶香叶酯合成酶,而NP_696587则代表由双歧杆菌(Bifidobacterium longum)分离的焦磷酸香叶香叶酯合成酶;
图5b是依据本公开内容另一实施例所绘示的示意图,其系关于焦磷酸香叶香叶酯合成酶的催化域1-2中的保留性残基,并以底线标注该些保留性残基;
图6是依据本公开内容一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Xd3.0,其中该重组多核苷酸序列包含3组基因组(即crtE-Kan-tHMG1);
图7a是依据本公开内容一实施例所绘示的序列比对数据,其系关于茄红素环化酶(lycopene cyclase)的保留性区域,并以底线标注其催化域1-2;其中,CAB51949代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的茄红素环化酶,XP_762434代表由玉米黑穗菌521(Ustilago maydis 521)分离的茄红素环化酶,NP_344223代表由硫化叶菌P2(Sulfolobus solfataricus P2)分离的茄红素环化酶,而YP_024312则代表由嗜苦古菌(Picrophilus torridus)分离的茄红素环化酶;
图7b是依据本公开内容一实施例所绘示的示意图,其系关于茄红素环化酶的催化域1-2中的保留性残基,并以底线标注该些保留性残基;
图7c是依据本公开内容一实施例所绘示的序列比对数据,其系关于反-异戊烯焦磷酸合成酶合成酶(trans-isoprenyl diphosphate synthase)的保留性区域,并以底线标注其催化域1-2;其中,CAB51949代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的反-异戊烯焦磷酸合成酶合成酶,NP_279693代表由嗜盐菌NRC-1(Halobacterium sp.NRC-1)分离的反-异戊烯焦磷酸合成酶合成酶,NP_681887代表由嗜热藻BP-1(Thermosynechococcus elongatus BP-1)分离的反-异戊烯焦磷酸合成酶合成酶,而ZP_00089878则代表由棕色固氮菌(Azotobacter vinelandii)分离的反-异戊烯焦磷酸合成酶合成酶;
图7d是依据本公开内容一实施例所绘示的示意图,其系关于反-异戊烯焦磷酸合成酶合成酶的催化域1-2中的保留性残基,并以底线标注该些保留性残基;
图8a是依据本公开内容另一实施例所绘示的序列比对数据,其系关于八氢茄红素去饱合酶(phytoene desaturase)的保留性区域,并以底线标注其NAD(P)-结合罗斯曼相似区域(NAD(P)-binding Rossmann-like domain);其中,AAO53257代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的八氢茄红素去饱合酶,CAE07416代表由聚球藻WH 8102(Synechococcus sp.WH 8102)分离的八氢茄红素去饱合酶,BAA10798代表由集胞藻PCC 6803(Synechocystis sp.PCC 6803)分离的八氢茄红素去饱合酶,BAB73763代表由念珠藻PCC 7120(Nostoc sp.PCC 7120)分离的八氢茄红素去饱合酶,而AAL91366则代表由西红柿(Solanum lycopersicum)分离的八氢茄红素去饱合酶;
图8b是依据本公开内容另一实施例所绘示的示意图,其系关于八氢茄红素去饱合酶的NAD(P)-结合罗斯曼相似区域中的保留性残基,并以底线标注该些保留性残基;
图9是依据本公开内容一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Xd5.0,其中该重组多核苷酸序列包含5组基因组(即crtI-crtE-Kan-crtYB-tHMG1);
图10a和10b是依据本公开内容另一实施例所绘示的序列比对数据,其系关于β-胡萝卜素加氧酶(β-carotene oxygenase)的保留性区域,并以底线标注其催化域1-3;其中,AAY33921代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的β-胡萝卜素加氧酶,Q08477代表由智人(Homo sapiens)分离的β-胡萝卜素加氧酶,P33274代表由褐家鼠(Rattus norvegicus)分离的β-胡萝卜素加氧酶,P11707代表由家兔(Oryctolagus cuniculus)分离的β-胡萝卜素加氧酶,而P33270则代表由果蝇(Drosophila melanogaster)分离的β-胡萝卜素加氧酶;
图10c是依据本公开内容另一实施例所绘示的示意图,其系关于β-胡萝卜素加氧酶的催化域1-3中的保留性残基,并以底线标注该些保留性残基;
图11a和11b是依据本公开内容一实施例所绘示的序列比对数据,其系关于P450还原酶(P450reductase)的保留性区域,并以底线分别标注其黄素氧化还原蛋白域(flavodoxin domain)和NADPH细胞色素p450还原酶域(NADPH cytochrome p450reductase domain);其中,ACI43097代表由红发夫酵母(Xanthophyllomyces dendrorhous)分离的P450还原酶,Q00141代表由黑曲菌(Aspergillus niger)分离的P450还原酶,NP_596046代表由粟酒裂殖酵母(Schizosaccharomyces pombe)分离的P450还原酶,XP_001731494代表由球形马拉色菌CBS 7966(Malassezia globosa CBS 7966)分离的P450还原酶,而XP_762420则代表由玉米黑穗菌521(Ustilago maydis 521)分离的P450还原酶;
图11c是依据本公开内容一实施例所绘示的示意图,其系关于P450还原酶的黄素氧化还原蛋白区域1-4中的保留性残基,并以底线标注该些保留性残基;
图11d依据本公开内容一实施例所绘示的示意图,其系关于NADPH细胞色素p450还原酶域1-5中的保留性残基,并以底线标注该些保留性残基;
图12是依据本公开内容一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Xd7-3,其中该重组多核苷酸序列包含 7组基因组(即crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1);
图13a是依据本公开内容另一实施例的照片,其系关于特定菌株于琼脂培养基(agar plate)培养10代后的表型(phenotype);
图13b是依据本公开内容另一实施例所绘示的用以建构重组多核苷酸序列的示意图;
图13c是依据本公开内容一实施例的凝胶电泳(gel electrophoresis)照片,其该凝胶电泳中的DNA片段是由特定菌株萃出后,利用菌落聚合酶连锁反应(colony polymerase chain reaction,colony PCR)扩增(amplify)后的DNA产物;
图14a是依据本公开内容另一实施例所绘示的序列比对数据,其系关于β-胡萝卜素酮醇酶(β-carotene ketolase)的保留性区域,并以底线标注其催化域1-4;其中,XP_001698699代表由莱茵衣藻(Chlamydomonas reinhardtii)分离的β-胡萝卜素酮醇酶,BAB74888代表由珠藻PCC 7120(Nostoc sp.PCC 7120)分离的β-胡萝卜素酮醇酶,NP_924674代表由无类囊体蓝藻PCC 7421(Gloeobacter violaceus PCC 7421)分离的β-胡萝卜素酮醇酶,ABB25938代表由聚球藻CC9902(Synechococcus sp.CC9902)分离的β-胡萝卜素酮醇酶,而CAE07883则代表由聚球藻WH 8102(Synechococcus sp.WH 8102)分离的β-胡萝卜素酮醇酶;
图14b是依据本公开内容另一实施例所绘示的示意图,其系关于β-胡萝卜素酮醇酶的催化域1-4中的保留性残基,并以底线标注该些保留性残基;
图15a是依据本公开内容一实施例所绘示的序列比对数据,其系关于β-胡萝卜素羟化酶(β-carotene hydroxylase)的保留性区域,并以底线标注其催化域1-2;其中,XP_001698698代表由莱茵衣藻(Chlamydomonas reinhardtii)分离的β-胡萝卜素羟化酶,ABS50237代表由小球藻(Chromochloris zofingiensis)分离的β-胡萝卜素羟化酶,而Q9SPK6则代表由雨生红球藻(Haematococcus pluvialis)分离的β-胡萝卜素羟化酶;
图15b是依据本公开内容一实施例所绘示的示意图,其系关于β-胡萝卜素羟化酶的催化域1-2中的保留性残基,并以底线标注该些保留性残基;
图16a是依据本公开内容一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Cr1,其中该重组多核苷酸序列包含 7组基因组(即crtI-crtE-CrChYb-Kan-CrBKT-crtYB-tHMG1);
图16b是依据本公开内容另一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Hp9,其中该重组多核苷酸序列包含 7组基因组(即crtI-crtE-HpChYb-Kan-CrBKT-crtYB-tHMG1);
图16c是依据本公开内容再另一实施例所绘示的示意图,其系关于包含本发明重组多核苷酸序列的基因工程菌株Cz5,其中该重组多核苷酸序列包含 7组基因组(即crtI-crtE-CzChYb-Kan-CrBKT-crtYB-tHMG1);
图17a是依据本公开内容一实施例所提供的包含特定菌株的培养液照片;
图17b是依据本公开内容另一实施例所提供的包含特定菌株的培养液照片;
图17c是依据本公开内容一实施例所绘示的特定菌株的生长曲线图;
图17d是依据本公开内容另一实施例所绘示的曲线图,其系利用光谱分析试验来测量类胡萝卜素的紫外光/可见光(UV/V)全光谱;
图18a和18b是依据本公开内容另一实施例所绘示的高效液相色谱(high performance liquid chromatography,HPLC)结果,该结果是利用HPLC光谱分析试验、于UV450纳米波段来测量特定菌株;其中1代表游离形式的斑螯黄质,6代表游离形式的β-胡萝卜素,而2、3、4、5、7和8则代表未知高峰;
图19a是依据本公开内容另一实施例所提供的特定菌株的照片;
图19b是依据本公开内容另一实施例所提供的在不同温度下培养特定菌株的培养液照片;
图19c是依据本公开内容一实施例所绘示的基因表达柱状图;
图20a和20b是依据本公开内容一实施例所绘示的特定菌株于UV450纳米波段的HPLC结果;
图21a是依据本公开内容另一实施例所提供的包含特定菌株和成分的培养液照片;
图21b是依据本公开内容另一实施例所提供的包含CA6-ITS菌株和成分的培养液照片;
图22是依据本公开内容一实施例所绘示的液相层析法-质谱法(liquid chromatography–mass spectrometry,LC/MS)分析结果,其系将化合物皂化(saponification)后,利用LC/MS于UV460纳米波段来进行分析;
图23a是依据本公开内容一实施例所绘示的柱状图,其系关于特定菌株的自由基清除比例,其中该比例是利用抗氧化能力试验,并以2,2'-二氮-双(3-乙基苯并噻唑-6-磺酸(2,2'-azino-bis(3-ethylbenzothiazoline-6-sulphonic acid),ABTS)作为受质来定量;
图23b是依据本公开内容一实施例所绘示的柱状图,其系关于水溶性维生素E相似物等量抗氧化能力(Trolox equivalent antioxidant capacity,TEAC)试验结果;
图24a是依据本公开另一实施例所绘示的包含8组基因组的重组多核苷酸序列示意图;
图24b是依据本公开内容一实施例所绘示的CA6-ITS菌株的内转录间隔区(internal transcribed spacer,ITS)示意图,其中该CA6-ITS菌株包含7组基因组;
图24c是依据本公开内容一实施例所绘示的相对基因表达柱状图,其中萃取特定菌株的各基因的RNA,利用反转录聚合酶连锁反应(Reverse Transcription-Polymerase Chain Reaction,RT-PCR)放大分析;
图24d是依据本公开另一实施例所绘示的载体RS426示意图,其中该RS426载体为多拷贝数(high copy number)载体,且包含本发明重组多核苷酸序列;
图24e是依据本公开内容一实施例所提供的电泳图照片;
图24f是依据本公开内容一实施例所绘示的利用HPLC分析由CA6-ITS菌株制备的虾红素的分析结果;
图25a和25b是依据本公开内容另一实施例所提供的包含特定菌株和成分的培养液照片;
图26a是依据本公开内容一实施例所绘示的利用液相层析法-质谱法于UV460纳米波段所分析的超高效液相层析(Ultra Performance Liquid Chromatography,UPLC)结果;
图26b是依据本公开内容另一实施例所绘示的利用液相层析法-质谱法于UV460纳米波段所分析的质谱分析结果;
图27是依据本公开内容一实施例所提供的野生型或Cz30菌株的照片,其中该些菌株是分别以(a)紫外光照射,(b)糠醛,(c)乙醇和(d)丁醇进行处理;
图28a是依据本公开内容另一实施例所绘示的野生型和Cz30菌株的细胞密度柱状图,其中该些菌株是分别以不同浓度的乙醇进行处理;
图28b是依据本公开内容另一实施例所绘示的野生型和Cz30菌株的细胞密度及乙醇产量图,其中该些菌株是分别培养于包含20%半乳糖的YPG培养液中;左侧y轴代表细胞密度,右侧y轴代表乙醇产量,x轴则代表时间;
图29a是依据本公开内容一实施例所提供的野生型或Cz30菌株的照片,其中该些菌株是分别以溶于特定浓度的乙醇的10-去乙酰浆果赤霉素III来进行处理;
图29b是依据本公开内容一实施例所绘示的野生型或Cz30菌株的细胞密度柱状图,其中该些菌株是分别以溶于特定浓度的乙醇的10-去乙酰浆果赤霉素III来进行处理;
图30是依据本公开内容一实施例所绘示的野生型或Cz30菌株的生长曲线图,其中该些菌株是分别以(a)0.8mM的溶于4%乙醇的10-去乙酰浆果赤霉素III,和(b)1.2mM的溶于6%乙醇的10-去乙酰浆果赤霉素III进行处理;以及
图31是关于浆果赤霉素III于特定菌株中的生物转换(bio-conversion)。
根据惯常的作业方式,图中各种特征与组件并未依比例绘制,其绘制方式是为了以最佳的方式呈现与本发明相关的具体特征与组件。
实施方式
为了使本公开内容的叙述更加详尽与完备,下文针对本发明的实施方式与具体实施例提出说明性的描述;但这并非实施或运用本发明具体实施例的唯一形式。实施方式中涵盖了多个具体实施例的特征以及用以建构与操作这些具体实施例的方法步骤与其顺序。然而,亦可利用其它具体实施例来达成相同或均等的功能与步骤顺序。
除非本说明书另有定义,此处所用的科学与技术词汇的含义与本发明所属技术领域中具有通常知识者所理解与惯用的意义相同。
在不和上下文冲突的情形下,本说明书所用的单数名词涵盖该名词的复数型;而所用的复数名词时亦涵盖该名词的单数型。
虽然用以界定本发明较广范围的数值范围与参数皆是约略的数值,此处已尽可能精确地呈现具体实施例中的相关数值。然而,任何数值本质上不可避免地含有因个别测试方法所致的标准偏差。在此处,「约」通常系指实际数值在一特定数值或范围的正负10%、5%、1%或0.5%之内。或者是,「约」一词代表实际数值落在平均值的可接受标准误差之内,视本发明所属技术领域中具有通常知识者的考虑而定。除了实验例之外,或除非另有明确的说明,当可理解此处所用的所有范围、数量、数值与百分比(例如用以描述材料用量、时间长短、温度、操作条件、数量比例和其它相似者)均经过「约」的修饰。因此,除非另有相反的说明,本说明书与附随申请专利范围所公开的数值参数皆为约略的数值,且可视需求而更动。至少应将这些数值参数理解为所指出的有效位数与套用一般进位法所得到的数值。在此处,将数值范围表示成由一端点至另一段点或介于二端点之间;除非另有说明,此处所述的数值范围皆包含端点。
在本说明书中,「控制序列」(control sequence)一词系指可调控编码序列(coding sequence)的多核苷酸序列,其中该编码序列系可操作式地连接至该控制序列。控制序列的特性会依宿主生物体的差异而有所不同。在原核生物体中,控制序列通常包含启动子(promoter)、核醣体结合位置(ribosomal binding site)和终止子(terminator)。在真核生物体中,控制序列通常包含启动子、终止子和促进子(enhancer)或缄默子(silencer)。「控制序列」(control sequence)一词包含最少量的可调控编码序列表达的所有组件,亦包含其它可增加或控制特定基因的表达时间、表达量和表达位置的附加组件。在某些实施方式中,「控制序列」(control sequence)包含特定启动子以外的调控组件。
「启动子」(promoter)一词在本说明书系指一合成或融合的分子或其衍生物,可据以活化或增加细胞、组织或器官的核酸序列的表达。
「核酸序列」(nucleic acid sequence)、「多核苷酸」(polynucleotide)或「核酸」(nucleic acid)在本说明书中可交替使用,可指双股脱氧核糖核酸(deoxyribonuclic acid,DNA)、单股DNA或所述DNA的转录产物(例如核糖核酸分子,ribonucleic acid,RNA)。需知本公开内容无关乎自然界或自然状态下的基因多核苷酸序列。能用以分离或纯化(或部份纯化)本发明的核酸、多核苷酸或核苷酸序列的方法包含,但不限于离子交换色层分析(ion-exchange chromatography)、分子筛选色层分析(molecular size exclusion chromatography)或是可用于基因工程技术诸如扩增(amplification)、扣除杂交法(subtractive hybridization)、克隆(cloning)、亚克隆(sub-cloning)、化学合成(chemical synthesis)或其组合等基因工程技术。
「序列相同性」(sequence identity)一词在此是指二条或多条序列或次序列在进行比较或比对时的最大对应值,其中该些序列或次序列系相同或具有一特定比例的相同的氨基酸残基或核苷酸。为取得相同百分比,该些序列是以最佳化的比对方式进行比对(例如,可在第一氨基酸序列中插入或删去间隙,使其与第二氨基酸序列比对时可达最大序列相同性)。再比对位于对应位置的氨基酸残基或核苷酸。当第一序列中的位置与第二序列中相对应的位置具有相同的氨基酸残基或核苷酸时,则该位置的二个分子系为相同。二条序列的相同百分比是序列间相同位置的数量函数(即,相同百分比=相同位置的数量/位置的总数量(例如,两两排列的位置数量)×100)。在某些实施方式中,二条序列具有相同的长度。用来比对序列的方法是相关领域人士所熟知的,例如GAP、BESTFIT、BLAST、FASTA和TFASTA。
如上所述,目前以生物方式合成虾红素仍有诸多限制,利用生物合成虾红素的成本明显高出化学合成许多。然而,化学合成往往会导致环境污染,且合成产物不易保存,亦不易被人体所吸收。有鉴于此,本发明旨在提供一种策略(图3),能有效且大量地于宿主细胞中制备虾红素或其前驱物或衍生物。相较于传统方法(例如基因工程微生物)或化学合成,本发明策略具有4项优势:(1)可合成较高量的前驱物,(2)较短的代谢路径,(3)最终产物的立体结构具有生物活性,以及(4)酯化形式易于吸收。
具体来说,本公开内容提供重组多核苷酸序列,其系用以编码数种调控生物合成虾红素的多条胜肽;包含本发明重组多核苷酸序列的载体;包含本发明重组多核苷酸序列和/或载体的宿主细胞;以及一种利用本发明宿主细胞来生物合成虾红素或其前驱物或衍生物的方法。基于虾红素和/或其前驱物或衍生物的抗氧化功效,本公开内容亦提供一种用以改善宿主细胞对压力的耐受度的方法,以及一种用以增加宿主细胞制备乙醇或浆果赤霉素III的产量的方法。
本发明制备出的虾红素可以是3S,3S’-虾红素或3R,3R’-虾红素。虾红素的前驱物可以是焦磷酸香叶香叶酯(geranylgeranyl-pyrophosphate)、尼基叶黄素(phenicoxanthin)、茄红素(lycopene)、海胆酮(echinenone)、斑螯黄质(canthaxanthin)、八氢西红柿红素(phytoene)、玉米黄质(zeaxanthin)、β-隐黄素(β-cryptoxanthin)或β-胡萝卜素(β-carotene)。虾红素的衍生物可以是虾红素单酯体(monoester)或虾红素双酯体(diester)。
1.重组多核苷酸序列
本公开内容的第一方面是关于一重组多核苷酸序列,其中重组多核苷酸序列是依据以启动子为基础的基因组合及同步表达(Promoter-based Gene Assembly and Simultaneous Overexpression,PGASO)方法(Chang et al.,2012)来建构完成。PGASO方法是一种利用具有重迭区域的多核苷酸序列来重组带有不同启动子的基因组的克隆方法;利用该方法可将多个基因组依特定顺序插入宿主细胞的基因体(genome)中。简单来说,各基因组包含二部份:(1)一段连接于启动子的5’端的基因序列,以及(2)一段位于基因组的3’端且与其邻近基因组的5’端相同的基因序列。第一基因组启动子的5’端序列与第二基因组的3’端序列系与宿主基因体的特定位置相互同源的基因序列,故可利用同源重组(homologous recombination)的机制将二基因组插入宿主基因体的特定位置。各基因组中启动子的序列应为不同的序列。而基因组的3’端序列则应与邻近下游基因组的部份启动子序列相互同源。当将各基因组克隆至宿主细胞内后,各基因组会藉由启动子与对应序列间的重迭序列进行同源重组,重组后的重组多核苷酸序列会再利用第一基因组中的启动子序列与基因体中预设的同源序列和最后一组基因组中的3’端序列与基因体中预设的同源序列,以预先设定的顺序插入宿主细胞的基因体中。
以下所有重组多核苷酸序列皆是利用PGASO的技术建构而成。
1.1包含二基因组的重组多核苷酸序列
依据本公开内容一实施方式,本发明重组多核苷酸序列包含二组基因组。第一基因组包含以第一启动子驱动的第一核酸序列,其中该第一核酸序列系用以编码焦磷酸香叶香叶酯合成酶(geranylgeranyl pyrophosphate synthase,GGPP synthase);已知焦磷酸香叶香叶酯合成酶可催化焦磷酸香叶(geranyl pyrophosphate,FPP)形成焦磷酸香叶香叶酯(geranylgeranyl pyrophosphate,GGPP)。第二基因组包含由第二启动子驱动的第二核酸序列,其中该第二核酸序列系用以编码3-羟基-3-甲基戊二酰-辅酶A还原酶(3-hydroxy-3-methylglutaryl–coenzyme A reductase,HMG-CoA reductase,以下简称HMG-CoA还原酶);已知HMG-CoA还原酶可催化甲基二羟戊酸(mevalonic acid)形成乙酰辅酶A(Acetyl-CoA)。基于PGASO的建构策略,一基因组的3’端会与位于该基因组下游的另一基因组的5’端相互同源。据此,当二基因组同时克隆至宿主细胞后,其会进行同源重组形成重组多核苷酸序列。
举例来说,依据本公开内容一实施方式,第一基因组的3’端序列系与第二启动子的部份序列相互同源。经同源重组后,重组多核苷酸序列会包含二基因组;其由5’端至3’端分别为第一基因组和第二基因组。
可选择性地,本发明重组多核苷酸序列可更包含标记基因组,该标记基因组包含标记启动子及可操作式地连结至该标记启动子的标记基因。依据本公开内容另一实施方式,第一基因组的3’端序列与标记启动子的部份序列相互同源,而标记基因组的3’端序列则与第二启动子的部份序列相互同源。据此,经同源重组后,标记基因组会位于第一和第二基因组之间。
为制备焦磷酸香叶香叶酯合成酶,第一核酸序列为一crtE基因或其片段;其中该crtE基因或其片段可以源自红发夫酵母(Xanthophyllomyces dendrorhous)、天蓝色链霉菌(Streptomyces coelicolor)、谷氨酸棒状杆菌(Corynebacterium glutamicum)、嗜高温放线菌(Thermobifida fusca)或双歧杆菌(Bifidobacterium longum)的crtE基因。在一特定实施方式中,第一核酸序列系源自红发夫酵母的crtE基因的催化域,且包含序列编号:1的序列。
为制备HMG-CoA还原酶,第二核酸序列为HMG1基因或其片段,其中该HMG1基因或其片段可以源自马克斯克鲁维酵母(Kluyveromyces marxianus)、啤酒酵母菌(Saccharomyces cerevisiae)、史特卡云杉(Picea sitchensis)、土曲霉(Aspergillus terreus)或灵芝(Ganoderma lucidum)的HMG1基因。在一实施方式中,第二核酸序列系源自马克斯克鲁维酵母的HMG1基因的催化域。已知截断型HMG-CoA还原酶(truncated HMG-CoA reductase,tHMG1)会减少反馈抑制(feedback inhibition),进而增加焦磷酸香叶香叶酯的产量。据此,在一特定实施方式中,第二核酸序列为tHMG1基因,且包含序列编号:2的序列。
标记基因可以是荧光基因、β-葡萄醣醛酸酶(β-glucuronidase)基因和LacZ基因等筛分(screening)标记基因,亦可以是抗生素抗药性基因等筛选(selection)标记基因。依据本公开内容一实施方式,本发明标记基因是一种抗生素抗药性基因,例如可对康霉素(Kanamycin)/建那霉素(geneticin,G418)/新霉素(neomycin)产生抗性的KanMX标记基因,或是可对金黄担子素A(aureobasidin A,AbA)产生抗性的AUR1-C基因。
适用于驱动第一、第二及标记核酸序列/基因表达的启动子包含,但不限于,ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子。较佳的情况是,利用不同的启动子来驱动重组多核苷酸序列中各核酸序列或基因组的表达。在一实施方式中,第一启动子是KlLac4启动子,第二启动子是ScADHI启动子,而标记启动子则为KlGapDH启动子。
1.2包含四基因组的重组多核苷酸序列
依据本公开内容另一实施方式,本发明重组多核苷酸序列包含四组基因组。具体来说,除了本公开内容1.1所述的用以编码焦磷酸香叶香叶酯合成酶和HMG-CoA还原酶的第一及第二基因组外,本发明重组多核苷酸序列进一步包含第三和第四基因组。第三基因组包含以第三启动子驱动的第三核酸序列,其中该第三核酸序列系用以编码八氢茄红素去饱合酶(phytoene desaturase);已知八氢茄红素去饱合酶可催化顺-八氢茄红素(cis-phytoene)形成茄红素(lycopene)。第四基因组包含以第四启动子驱动的第四核酸序列,其中该第四核酸序列系用以编码一具有八氢茄红素合成酶(phytoene synthase)和茄红素环化酶(lycopene cyclase)个别功能的双功能酶(以下简称八氢茄红素合成酶/茄红素环化酶);已知八氢茄红素合成酶和茄红素环化酶皆可催化茄红素形成β-胡萝卜素(β-carotene)。
利用PGASO的建构策略来重组该四组基因组。亦即,各基因组的3’端会与位于其下游的下一基因组的5’端相互同源。举例来说,在本公开内容一实施方式中,第三基因组的3’端序列系与第一启动子的部份序列相互同源;第一基因组的3’端序列系与第四启动子的部份序列相互同源;而第四基因组的3’端序列系与第二启动子的部份序列相互同源。据此,该四组基因组将会于活体内自发性地重组形成重组多核苷酸序列,其由5’端至3’端依序包含第三基因组、第一基因组、第四基因组和第二基因组。
可选择性地,本发明重组多核苷酸序列可包含标记基因组,该标记基因组包含标记启动子和可操作式地连结至该标记启动子的标记基因。包含标记基因组的重组多核苷酸序列系利用PGASO方法建构而成;因此,为简洁起见在此省略其详细描述。依据本公开内容一实施方式,标记基因组是位于第一和第四基因组之间。
为制备八氢茄红素去饱合酶,第三核酸序列为crtI基因或其片段;其中该crtI基因或其片段可以源自红发夫酵母(Xanthophyllomyces dendrorhous)、聚球藻WH 8102(Synechococcus sp.WH 8102)、集胞藻PCC 6803(Synechocystis sp.PCC 6803)、念珠藻PCC 7120(Nostoc sp.PCC 7120)或西红柿(Solanum lycopersicum)的crtI基因。在一特定实施方式中,第三核酸序列系源自红发夫酵母的crtI基因的催化域,且包含序列编号:3的序列。
为制备具有八氢茄红素合成酶和茄红素环化酶个别功能的双功能酶,第四核酸序列包含crtYB基因或其片段;其中该crtYB基因或其片段可以源自红发夫酵母(Xanthophyllomyces dendrorhous)、玉米黑穗菌521(Ustilago maydis 521)、硫化叶菌(Sulfolobus solfataricus)或嗜苦古菌(Picrophilus torridus)的crtYB基因。在一特定实施方式中,第四核酸序列系源自红发夫酵母的crtYB基因的催化域,且包含序列编号:4的序列。
标记基因可以是筛分标记基因或筛选标记基因。依据本公开内容一实施方式,标记基因为抗生素抗药性基因KanMX。
适用于驱动第一、第二、第三、第四及标记核酸序列/基因表达的启动子包含,但不限于,ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子。较佳的情况是,利用不同的启动子来驱动重组多核苷酸序列中各核酸序列或基因组的表达。在一实施方式中,第一启动子是ScPGK启动子,第二启动子是ScADHI启动子,第三启动子是KlLac4启动子,第四启动子是KlADHI启动子,而标记启动子则是KlGapDH启动子。
1.3用以表达3S,3S’-虾红素的包含六基因组的重组多核苷酸序列
依据本公开内容另一实施方式,本发明重组多核苷酸序列包含用以制备3S,3S’-虾红素的六组基因组。具体来说,除了本公开内容1.2所述的用以编码焦磷酸香叶香叶酯合成酶、HMG-CoA还原酶、八氢茄红素去饱合酶和八氢茄红素合成酶/茄红素环化酶的第一至第四基因组外,本发明重组多核苷酸序列进一步包含二基因组,其系分别用以表达β-胡萝卜素羟化酶(β-carotene hydroxylase)和β-胡萝卜素酮醇酶(β-carotene ketolase);已知β-胡萝卜素羟化酶和β-胡萝卜素酮醇酶系为将β-胡萝卜素转换为3S,3S’-虾红素的必要性酶。更具体来说,第五基因组包含以第五启动子驱动的第五核酸序列,其中该第五核酸序列系用以编码β-胡萝卜素羟化酶。第六基因组包含以第六启动子驱动的第六核酸序列,其中该第六核酸序列系用以编码β-胡萝卜素酮醇酶。
相似地,包含六组基因组的重组多核苷酸序列亦是利用PGASO的建构策略重组而成;其中,各基因组的3’端会与位于其下游的下一基因组的5’端相互同源。举例来说,在一特定实施例中,第三基因组的3’端序列系与第一启动子的部份序列相互同源,第一基因组的3’端序列系与第五启动子的部份序列相互同源,第五基因组的3’端序列系与第六启动子的部份序列相互同源,第六基因组的3’端序列系与第四启动子的部份序列相互同源,而第四基因组的3’端序列则系与第二启动子的部份序列相互同源。一旦克隆至宿主细胞内后,该六组基因组会自发性地重组形成一重组多核苷酸序列,其由5’端至3’端依序包含第三基因组、第一基因组、第五基因组、第六基因红、第四基因组和第二组基因。
可选择性地,本发明重组多核苷酸序列可包含一标记基因组,该标记基因组包含一标记启动子及一可操作式地连结至该标记启动子的标记基因。在一实施例中,建构的标记基因组是位于第五和第六基因组之间。
为制备β-胡萝卜素羟化酶,第五核酸序列包含一ChYb基因或其片段,其中该ChYb基因或其片段可以源自莱茵衣藻(Chlamydomonas reinhardtii)、小球藻(Chlorella zofingiensis)或雨生红球藻(Haematococcus pluvialis)的ChYb基因。在一实施方式中,第五核酸序列是源自莱茵衣藻的ChYb基因的催化域,且包含序列编号:5的序列。在另一实施方式中,第五核酸序列是源自小球藻的ChYb基因的催化域,且包含序列编号:6的序列。在再另一实施方式中,第五核酸序列是源自雨生红球藻的ChYb基因的催化域,且包含序列编号:7的序列。
为制备β-胡萝卜素酮醇酶,第六核酸序列包含一bkt基因或其片段,其中该bkt基因或其片段可以源自莱茵衣藻(Chlamydomonas reinhardtii)、念珠藻PCC 7120(Nostoc sp.PCC 7120)、无类囊体蓝藻PCC 7421(Gloeobacter violaceus PCC 7421)、聚球藻CC9902(Synechococcus sp.CC9902)或聚球藻WH 8102(Synechococcus sp.WH 8102)的bkt基因。在一特定实施方式中,第六核酸序列系源自莱茵衣藻的bkt基因的催化域,且包含序列编号:8的序列。
标记基因可以是筛分标记基因或筛选标记基因。依据本公开内容一实施方式,标记基因为抗生素抗药性基因KanMX。
适用于驱动第一至第六核酸序列及标记基因表达的启动子包含,但不限于,ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子。较佳情况是,利用不同的启动子来驱动重组多核苷酸序列中各核酸序列或基因组的表达。在一实施方式中,第一启动子是ScGapDH启动子,第二启动子是ScADHI启动子,第三启动子是KlLac4启动子,第四启动子是KlADHI启动子,第五启动子是ScPGK启动子,第六启动子是KlPGK启动子,而标记启动子则是KlGapDH启动子。
1.4用以表达3R,3R’-虾红素的包含六基因组的重组多核苷酸序列
本公开内容亦提供一用以于宿主细胞中制备3R,3R’-虾红素的重组多核苷酸序列。依据本公开内容的实施方式,本发明用以制备3R,3R’-虾红素的重组多核苷酸序列包含六组基因组,其中前四组基因组为本公开内容1.2所述的基因组,其系分别用以表达焦磷酸香叶香叶酯合成酶、HMG-CoA还原酶、八氢茄红素去饱合酶和八氢茄红素合成酶/茄红素环化酶;另外二组基因组(即第七基因组和第八基因组)则分别用以表达P450还原酶(P450reductase)和β-胡萝卜素加氧酶(β-carotene oxygenase);已知P450还原酶和β-胡萝卜素加氧酶在催化β-胡萝卜素形成3R,3R’-虾红素的生物合成路径中扮演着重要的角色。具体来说,第七基因组包含以第七启动子驱动的第七核酸序列,其中该第七核酸序列系用以编码P450还原酶。第八基因组包含以第八启动子驱动的第八核酸序列,其中该第八核酸序列系用以编码β-胡萝卜素加氧酶。
同样地,用以制备3R,3R’-虾红素的重组多核苷酸序列也是利用PGASO策略建构而成,其中,各基因组的3’端会与位于其下游的下一基因组的5’端相互同源。举例来说,依据本公开内容一实施方式,第三基因组的3’端序列系与第七启动子的部份序列相互同源;第七基因组的3’端序列系与第一启动子的部份序列相互同源;第一基因组的3’端序列系与第八启动子的部份序列相互同源;第八基因组的3’端序列系与第四启动子的部份序列相互同源;而第四基因组的3’端序列则系与第二启动子的部份序列相互同源。利用基因组间的同源序列,该七组基因组可于活体内进行同源重组,以形成一重组多核苷酸序列,其由5’端至3’端依序包含第三基因组、第七基因组、第一基因组、第八基因组、第四基因组和第二基因组。
可选择性地,本发明用以制备3R,3R’-虾红素的重组多核苷酸序列可进一步包含一标记基因组,该标记基因组包含一由标记启动子驱动的标记基因。在一较佳的实施方式中,标记基因组是位于第一和第八基因组之间。
为制备P450还原酶,第七核酸序列包含一crtR基因或其片段,其中该crtR基因或其片段可以源自红发夫酵母(Xanthophyllomyces dendrorhous)、黑曲菌(Aspergillus niger)、粟酒裂殖酵母(Schizosaccharomyces pombe)、形马拉色菌CBS 7966(Malassezia globosa CBS 7966)或玉米黑穗菌521(Ustilago maydis 521)的crtR基因。在一特定实施方式中,第七核酸序列系源自红发夫酵母的crtR基因,且包含序列编号:9的序列。
为制备β-胡萝卜素加氧酶,第八核酸序列包含一crtS基因或其片段,其中该crtS基因或其片段可以源自红发夫酵母(Xanthophyllomyces dendrorhous)、智人(Homo sapiens)、褐家鼠(Rattus norvegicus)、家兔(Oryctolagus cuniculus)或果蝇(Drosophila melanogaster)的crtS基因。在一实施方式中,第八核酸序列系源自红发夫酵母的crtS基因,且包含序列编号:10的序列。
标记基因可以是筛分标记基因或筛选标记基因。依据本公开内容一实施方式,所述标记基因为一抗生素抗药性基因KanMX。
适用于驱动第一、第二、第三、第四、第七、第八和标记核酸序列/基因表达的启动子包含,但不限于,ScGapDH启动子、KlGapDH启动子、ScPGK启动子、KlPGK启动子、KlADHI启动子、ScADHI启动子、KlADH4启动子、ScADH4启动子、KlLac4启动子和ICL启动子。较佳的情况是,利用不同的启动子来驱动重组多核苷酸序列中各核酸序列或基因组的表达。在一实施方式中,第一启动子是ScPGK启动子,第二启动子是ScADHI启动子,第三启动子是KlLac4启动子,第四启动子是KlADHI启动子,第七启动子是ScGapDH启动子,第八启动子是KlPGK启动子,而标记启动子则是KlGapDH启动子。所有上述启动子皆为酵母菌组成型启动子(constitutive promoter),不论在何种环境下皆具有活性且可有效驱动酵母菌细胞中基因的表达。
依据某些实施方式,本公开内容1.1至1.4所述的各启动子(即第一、第二、第三、第四、第五、第六、第七、第八和标记启动子)包含特定的核苷酸序列。在一特定实施方式中,KlLac4启动子包含序列编号:63的核苷酸序列;ScGapDH启动子包含序列编号:64的核苷酸序列;ScPGK启动子包含序列编号:65的核苷酸序列;KlGapDH启动子包含序列编号:66的核苷酸序列;KlPGK启动子包含序列编号:67的核苷酸序列;KlADHI启动子包含序列编号:68的核苷酸序列;而ScADHI启动子则包含序列编号:69的核苷酸序列。
当可想见,也可以以其它组成型启动子来取代本公开内容1.1至1.4所述的各启动子(即第一、第二、第三、第四、第五、第六、第七、第八和标记启动子),其中该些组成型启动子可在酵母菌以外的物种中驱动下游基因的表达;据此,本发明基因组可于原核宿主细胞(例如细菌宿主细胞)或其它真核宿主细胞(例如真菌、植物、哺乳动物细胞)中有效进行表达。适用于在原核宿主细胞中驱动基因表达的启动子包含,但不限于,T3启动子、T5启动子、T7启动子、trp启动子、lac启动子、tac启动子(为trp和lac启动子的杂合体)、lac衍生的启动子、araBAD启动子、recA启动子、proU启动子、cst-1启动子、tatA启动子、cadA启动子、nar启动子、cspA启动子、SP6启动子、Rhamnose启动子和phoA启动子。适用于在哺乳动物细胞中驱动基因表达的启动子可选择自,但不限于,由SV40早期启动子(SV40early promoter)、劳斯肉瘤病毒启动子(Rous sarcoma virus promoter)、腺病毒主要晚期启动子(adenovirus major late promoter)、人类巨细胞病毒实时早期启动子(human cytomegalovirus(CMV)immediate early promoter)、小鼠干细胞病毒启动子(murine stem cell virus(MSCV)promoter)、病毒内部启动子(virus's internal promoter)、泛素启动子(Ubiquitin C(UbC)promoter)、延长因子-1α启动子(elongation factor-1α(EF-1α)promoter)、磷酸甘油酸激酶启动子(phosphoglycerate kinase(PGK)promoter)或CMV早期启动子(CMV early enhancer)/鸡只β肌动蛋白启动子(chickenβactin(CAG)promoter)所组成的群组。
除了PGASO建构方法外,亦可采用所属领域具有通常知识者所熟知的任何方法,来重组建构本公开内容1.1至1.4所述的基因组(即第一、第二、第三、第四、第五、第六、第七、第八和标记基因组),例如适当的限制酶和克隆系统,前提是只要能制备出欲求的特定产物(3S,3S’-虾红素或3R,3R’-虾红素)即可。
当使用不同方法来建构本发明基因组时,本公开内容1.1至1.4所述的基因组(即第一、第二、第三、第四、第五、第六、第七、第八和标记基因组)可能会以不同的顺序进行重组。举例来说,在使用不同的重迭/同源序列时,所建构重组的产物可能会与本发明重组多核苷酸序列具有不同的基因组排列顺序。或者是,可依据特定的排列顺序来使用不同的限制酶,藉以产生不一样的基因产物。因此,包含本发明基因组且具有不同排列顺序的重组多核苷酸序列亦属本公开内容的范畴。
可利用任何实验室或临床研究常用的方法来确认及分析重组多核苷酸序列的组成顺序。举例来说,可藉由基因定序、限制酶酶切或长聚合酶连锁反应(long-PCR)试验来进行分析。依据本公开内容一实施方式,是利用长聚合酶连锁反应来分析重组多核苷酸序列的组成顺序。一般来说,长聚合酶连锁反应是一种用以放大极长PCR产物(长达40kb DNA)的技术,可由巿售的商业套组,并参阅其所附的操作手册来进行试验。
2.包含本发明重组多核苷酸序列的载体
本公开内容的第二方面是关于一包含本发明重组多核苷酸序列和控制序列的载体,其中该控制序列是可操作式地连结至该重组多核苷酸序列。
控制序列是用以辅助重组多核苷酸序列于不同类型的宿主细胞中进行表达。因此,控制序列可包含不同的成分(例如启动子、核醣体结合位置、促进子/缄默子及终止子)。举例来说,于酵母菌中表达的控制序列通常包含一自主复制序列(autonomously replicating sequence,ARS),其系包含酵母菌基因体中的复制起始序列(replication origin,ori);自主复制序列通常包含四个区域(A、B 1、B2及B3),其系以于质体表达的稳定度来依序命名。A区域为高度保留性区域,任何的突变皆会使复制起始序列的功能丧失。相较的下,B 1、B2和B3区域的突变则仅会影响、而不会抑制复制起始序列的功能。一般来说,为了起始载体于酵母菌的复制,控制序列中的复制起始序列是由一可与复制蛋白结合的必要性DNA序列(即ARS保守序列,ARS consensus sequence,ACS)所组成。
在原核宿主细胞表达的控制序列可包含一复制起始序列和一操纵子(operon)。一般而言,复制起始序列可以是一源自大肠杆菌(Escherichia coli,E.coli)基因体的oriC,或是一源自pBR322(一种大肠杆菌的质体)且包含二突变的pUC。操纵子通常可用以调控启动子的表达;适用的操纵子包含,但不限于lac操纵子、trp操纵子或源自Tn10的抗四环素操纵子(Tn10-derived tetracycline resistance(Tet)operon)。
在哺乳动物细胞表达的控制序列则可包含复制起始序列及促进子/缄默子。用以起始载体于哺乳动物细胞表达的复制起始序列可以是源自SV40病毒基因体的SV40起始序列,或是一源自哺乳动物细胞基因体的oriC。促进子为位于调控基因上游或下游的短片段DNA(50-1500bp),通常为顺式作用(cis-acting),可与蛋白质(活化子)结合来活化基因的转录;缄默子则为位于调控基因上游或下游的DNA序列,可与转录因子(抑制子)结合来抑制基因的转录。
可利用习知技艺人士所熟知的任一方法,将本发明重组多核苷酸序列以可操作方式连结至控制序列。举例来说,可利用适当的限制酶、克隆系统或同源重组进行分子克隆。依据本公开内容一实施方式,系以同源重组的方式将本发明重组多核苷酸序列可操作式地连结至控制序列。具体来说,本发明重组多核苷酸序列是与控制序列共转化至酵母菌中,其中重组多核苷酸序列的5’端和3’端是分别与控制序列中的标记基因的3’端和5’端相互同源。据此,包含于重组多核苷酸序列的基因组可于活体内自发性地与控制序列进行重组。在一特定实施方式中,控制序列是质体pRS426,而标记基因为URA3基因。
依据本公开内容一实施方式,控制序列是高拷贝数(high-copy-number)质体。因此,在进行同源重组后,本发明重组多核苷酸序列可于酵母菌中高度表达。
3.用以表达本发明重组多核苷酸列的宿主细胞
本公开内容的第三方面是关于一种用以制备虾红素、虾红素前驱物及/或虾红素衍生物的宿主细胞。在某些实施方式中,是将本公开内容2所述的包含1.1、1.2、1.3或1.4的重组多核苷酸序列的载体克隆至宿主细胞中。
所制备而成的虾红素可以是3S,3S’-虾红素或3R,3R’-虾红素。虾红素的前驱物可以是焦磷酸香叶香叶酯、尼基叶黄素、茄红素、海胆酮、斑螯黄质、八氢西红柿红素、玉米黄质、β-隐黄素或β-胡萝卜素。虾红素的衍生物可以是虾红素单酯体或虾红素双酯体。
可利用任何习知技艺人士所熟知的方法将本发明重组多核苷酸序列及/或载体克隆至宿主细胞中。具体来说,用以将外源性DNA及/或载体克隆至原核宿主细胞(例如细菌宿主细胞)的方法包含化学处理(例如将宿主细胞培养于包含二价阳离子的溶液中,再以热进行处理),以及电穿孔(electroporation,例如以电场刺激宿主细胞,使其于细胞膜上产生孔洞)。
用以将外源性DNA及/或载体克隆至一酵母菌的方法包含,但不限于,酶处理(以酶降解酵母菌的细胞壁)、化学处理(以碱性阳离子处理酵母菌)、电穿孔及玻璃珠搅拌。依据本公开内容一实施方式,是利用电穿孔将本发明重组多核苷酸序列及/或载体克隆至酵母菌细胞中。
用以将外源性DNA及/或载体克隆至一真核宿主细胞(例如哺乳动物细胞)的方法包含以化学(例如磷酸钙、高分支有机化合物/树枝状聚合物(dendrimer)、脂质体及阳离子聚合物)处理宿主细胞、电穿孔、细胞挤压(cell squeezing,轻压细胞膜)、超音波穿孔(sonoporation,包含利用高强度超音波于细胞膜形成孔洞)、光转染(optical transfection,利用高聚焦电射于细胞膜制造一微小孔洞)、基因交付(impalefection,将DNA连接至一可穿透细胞的纳米纤维的表面)、基因枪(gene gun,将DNA连接至一纳米粒子后,直接注入标的细胞核内)、磁转染(magnetofection)/磁辅助转染(magnet assisted transfection,利用磁力将DNA送至标的细胞内),以及病毒法/病毒转染(利用病毒作为转体,将DNA送至标的细胞内)。
因此,适用以表达虾红素、虾红素前驱物及/或虾红素衍生物的宿主细胞可以是原核细胞(例如细菌细胞)或真核细胞(例如酵母菌细胞及哺乳动物细胞)。依据本公开内容一较佳实施方式,适用的宿主细胞为一酵母菌细胞。
依据某些实施方式,宿主细胞可以是马克斯克鲁维酵母(Kluyveromyces marxianus)、土曲霉(Aspergillus terreus)、博伊丁假丝酵母(Candida boidinii)、毕赤酵母(Pichia pastoris)、汉逊氏酵母(Hansenula polymorpha)、乳酸克鲁维酵母(Klyveromyces lactis)、耶氏解脂酵母(Yarrowia lipolytica)、粟酒裂殖酵母(Schizosaccharomyces pombe)、啤酒酵母菌(Saccharomyces cerevisiae)、蜡蚧轮枝菌属(Lecanicillium)、覆膜酵母属(Galactomyces)、地丝菌属(Geotrichum)、帚样霉菌属(Scopulariopsis)、镰孢菌属(Fusarium)、德巴利酵母(Debaryomyces,Dekkera)、孢汉逊酵母属(Hanseniaspora)、瑟氏哈萨克酵母属(Kazachstania)、郎香菌属(Lachancea)、美极梅奇酵母(Metschnikowia)、毕赤酵母属(Pichia)、圆酵母属(Torulopsis)、许旺酵母属(Schwanniomyces)、斯塔摩酵母属(Starmerella)、三角酵母属(Trigonopsis)、威克汉逊酵母属(Wickerhamomyces)、结合酵母属(Zygosaccharomyces)、接合囊孢菌(Zygotorulaspora)、孢圆酵母属(Torulaspora)、红霉菌属(Neurospora)、曲霉菌属(Aspergillus)、青霉菌属(Penicillium)、丝胞菌属(Sporendonema)、隐球酵母属(Cystofilobasidium)、耐冷酵母属(Guehomyces)、白霉菌属(Mucor)、黑霉菌属(Rhizopus)、大肠杆菌(Escherichia coli)、双歧杆菌属(Bifidobacterium)、短杆菌属(Brevibacterium)、棒状杆菌属(Corynebacterium)、短状杆菌属(Brachybacterium)、微杆菌属(Microbacterium)、节杆菌属(Arthrobacter)、库克菌属(Kocuria)、细球菌属(Micrococcus)、丙酸杆菌属(Propionibacterium)、链霉菌属(Streptomyces)、芽孢杆菌属(Bacillus)、肉食杆菌属(Carnobacterium)、肠球菌属(Enterococcus)、四联球菌属(TetrAgenococcus)、乳酸杆菌属(Lactobacillus)、小球菌属(Pediococcus)、白念珠球菌属(Leuconostoc)、酒酒球菌属(Oenococcus)、魏斯氏菌属(Weissella)、大型球菌属(Macrococcus)、葡萄球菌属(Staphylococcus)、乳酸球菌属(Lactococcus)、链球菌属(Streptococcus)、醋酸菌属(Acetobacter)、葡糖酸醋杆菌属(Gluconacetobacter)、哈夫尼亚菌属(Hafnia)、盐单胞菌属(Halomonas)或发酵单孢菌属(Zymomonas)细胞。在一特定实施方式中,宿主细胞为马克斯克鲁维酵母(Kluyveromyces marxianus)。
依据一实施方式,宿主细胞可以包含一或多拷贝数的本公开内容1和2所述的本发明基因组/重组多核苷酸序列/载体,藉以有效率地制备虾红素、虾红素前驱物及/或虾红素衍生物。
有鉴于发酵过程中,常伴随产生对宿主细胞具有毒性的中间产物,或是需利用该些中间产物来大量制备最终产物;利用本发明重组多核苷酸序列/载体所产生的虾红素/虾红素前驱物/虾红素衍生物可保护宿主细胞,避免在发酵过程中受到毒性中间产物的伤害。
依据本公开内容的实施方式,产生的虾红素/虾红素前驱物/虾红素衍生物具备抗氧化功效,可改善宿主细胞对压力的耐受性。压力可以来自乙醇、异丁醇、紫外光照射、糠醛及/或抗癌药物的前驱物。在一特定实施例中,宿主细胞系对用以制备抗癌药物紫杉醇(paclitaxel)的前驱物10-去乙酰浆果赤霉素III(10-deacetyl baccatin III,10DB)具有耐受性。可依实验需求使用不同的方法来测量宿主细胞对各式压力的耐受度。举例来说,可藉由测量菌落数、细胞生长、细胞密度或基因表达来了解耐受性。
4.用以制备虾红素、虾红素前驱物或虾红素衍生物的方法
本公开内容的第四方面是关于一种用以制备虾红素、虾红素前趋物及/或虾红素衍生物的方法。该方法包含将本公开内容3所述的宿主细胞培养于培养液(例如,酵母菌萃取物-蛋白胨-甘油培养液,yeast extract-peptone-glycerol medium,YPG medium)中,其中该培养液包含一种选自由葡萄糖、半乳糖、甘油、脂肪酸和/或其组合所组成的群组的成分。在一实施方式中,培养液包含甘油。在另一实施方式中,培养液包含葡萄糖。在另一实施方式中,培养液包含半乳糖。在再另一实施方式中,培养液包含脂肪酸,例如辛酸。
足以诱发本发明宿主细胞表达各基因组的葡萄糖、半乳糖或甘油浓度约为0.5-40%(重量浓度,重量/重量);亦即,浓度可以是0.5%、0.6%、0.7%、0.8%、0.9%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%或40%;而足以诱发本发明宿主细胞表达各基因组的脂肪酸浓度则为0.001%-5%(重量浓度,重量/重量);亦即,浓度可以是0.001%、0.002%、0.003%、0.004%、0.005%、0.006%、0.007%、0.008%、0.009%、0.01%、0.02%、0.03%、0.04%、0.05%、0.06%、0.07%、0.08%、0.09%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1%、2%、3%、4%或5%。
较佳的情况是,用以诱发本发明宿主细胞表达各基因组的葡萄糖、半乳糖或甘油浓度约为5-30%;而用以诱发本发明宿主细胞表达各基因组的脂肪酸浓度则为0.005-0.5%。
依据本公开内容某些实施方式,培养液包含一种选自由葡萄糖、半乳糖、甘油、脂肪酸及/或其组合所组成的群组的成分。在一实施方式中,培养液包含20%葡萄糖。在另一实施方式中,培养液包含20%半乳糖。在再另一实施方式中,培养液包含0.01-0.1%脂肪酸。在一较佳的实施方式中,培养液包含10-20%甘油。
当可想见,培养液可包含至少二种选自由葡萄糖、半乳糖、甘油、脂肪酸及/或其组合所组成的群组的成分,藉以更有效地诱发宿主细胞表达各基因组。
依据本公开内容其它实施方式,适用于培养本发明宿主细胞生产虾红素的温度约为18℃-42℃;举例来说,温度可以是18℃、19℃、20℃、21℃、22℃、23℃、24℃、25℃、26℃、27℃、28℃、29℃、30℃、31℃、32℃、33℃、34℃、35℃、36℃、37℃、38℃、39℃、40℃、41℃或42℃。在一实施方式中,温度为30℃。在另一实施方式中,温度为37℃。依据一较佳的实施方式,温度为25℃。
可利用任何本所属领域习知技艺人士所熟知的方法来测量本发明重组多核苷酸序列/载体的表达。举例来说,可直接目测及/或照像记录菌落及/或培养液的颜色变化。或是,藉由测量细胞生长、细胞浓度、基因表达、高效液相色谱分析或液相层析法-质谱法来分析序列/载体的表达。
依据本公开内容某些实施方式,本发明方法进一步可包含将制备的虾红素、虾红素前驱物及/或虾红素衍生物自宿主细胞或培养液中分离的步骤。在一实施方式中,是直接将虾红素由酵母菌中萃取出来;萃取方法包含,但不限于,自溶作用(autolysis,将酵母菌与甲苯/氢氧化铵均匀混合后,静置于室温24-48小时)、均质化(homogenization,使用均质机或法式压碎机)、玻璃珠振荡(利用玻璃珠搅拌来破坏酵母菌细胞)、酶水解(以消解酶(zymolase)或酶解酶(lyticase)来分解细胞壁)、冷冻及研磨(以液态氮冷冻细胞后,利用研钵和研杵来研磨冷冻的细胞)、超临界萃取,以及化学处理(例如以SDS及/或丙酮处理宿主细胞)。依据本公开内容一实施方式,是利用丙酮将虾红素由酵母菌中萃取出来。依据另一实施方式,是利用冷冻干燥法及甲醇处理将虾红素由酵母菌中萃取出来。
依据本公开内容某些实施方式,制备出的虾红素可以是3S、3S’-虾红素或3R、3R’-虾红素。
依据一实施方式,本发明方法所制备的产物是一虾红素前驱物,其可以是焦磷酸香叶香叶酯、尼基叶黄素、茄红素、海胆酮、斑螯黄质、八氢西红柿红素、玉米黄质、β-隐黄素或β-胡萝卜素。
依据其它实施方式,本发明方法所制备的产物是一虾红素衍生物,其可以是虾红素单酯体或虾红素双酯体。
依据本公开内容的实施方式,本发明方法制备的虾红素及/或其前驱物或衍生物具有抗氧化功效,可作为一种抗氧化剂。可利用习知技艺人士所熟知的任何活体外及/或活体内方法来测量其抗氧化功效。举例来说,活体外的测量方法可以是1、1-二苯基-2-苦基苯肼(1、1-diphenyl-2-picrylhydrazyl,又称α,α-二苯基-β-苦基苯肼,α,α-diphenyl-β-picrylhydrazyl,DPPH)清除活性试验、过氧化氢清除活性试验、一氧化氮清除活性试验、过氧化亚硝酸盐自由基(peroxynitrite radical)清除活性试验、水溶性维生素E相似物等量抗氧化能力(Trolox equivalent antioxidant capacity、TEAC)试验/ABTS自由基阳离子脱色(ABST radical cation decolorization)试验、总自由基捕获抗氧化参数(total radical-trapping antioxidant parameter、TRAP)试验、铁离子减少抗氧化力(ferric reducing-antioxidant power、FRAP)试验、超氧化物自由基清除活性(superoxide radical scavenging activity、SOD)试验、羟基自由基清除活性(hydroxyl radical scavenging activity)试验、羟基自由基趋避能力(hydroxyl radical averting capacity、HORAC)试验、氧自由基吸收能力(oxygen radical absorbance capacity、ORAC)试验、还原力(reducing power、RP)试验、磷钼(phosphomolybdenum)试验、硫氰酸铁(ferric thiocyanate、FTC)试验、硫巴比妥酸(thiobarbituric acid、TBA)试验、N,N-二甲基-对苯二胺二盐酸盐(N,N-dimethyl-p-phenylene diamine dihydrochloride、DMPD)试验、β-胡萝卜素亚油酸(β-carotene linoleic acid)试验/共轭二烯(conjugated diene)试验、黄嘌呤氧化酶(xanthine oxidase)试验、铜离子减少抗氧化能力(cupric ion reducing antioxidant capacity、CUPRAC)试验,或是金属螫合活性(metal chelating activity)试验。活体内测量抗氧化活性的方法则包含,但不限于,血浆铁还原能力(ferric reducing ability of plasma)、评估还原型麸胺基硫(reduced glutathione(GSH)estimation)、评估麸胺基硫过氧化酶(glutathione peroxidase(GSHPx)estimation)、麸胺基硫转移脢(glutathione-S-transferase、GST)、超氧化物歧化酶(superoxide dismutase、SOD)试验、过氧化氢酶(catalase、CAT)、γ-谷氨酸转胜肽酶(γ-glutamyl transpeptidase、GGT)活化试验、麸胺基硫还元酶(glutathione reductase、GR)试验、脂质过氧化(lipid peroxidation、LPO)试验及低密度脂蛋白(low-density lipoprotein、LDL)试验。依据本公开内容一实施方式,是利用水溶性维生素E相似物等量抗氧化能力试验/ABTS自由基阳离子脱色试验来测量虾红素或其前驱物或衍生物的抗氧化活性。
下文举出多种实施例来阐明本发明的部分方面,以使本发明所属技术领域中具有通常知识者能藉以实践本发明。因此不应将这些实施例视为对本发明范围的限制。本发明所属技术领域中具有通常知识者基于此处列举的说明,当可在不需过度推衍的情形下运用本发明。此处提及的所有文献,皆视为已完全引用而成为本说明书的一部份。
实施例
材料及方法
基因合成
分别以基因合成(GENEART,德国)来合成莱茵衣藻的bkt基因、莱茵衣藻的ChYb基因(即Crchyb基因)、小球藻(Chromochloris zofingiensis)的ChYb基因(即Czchyb基因)和雨生红球藻的ChYb基因(即Hpchyb基因)。所有的合成基因序列皆基于宿主红发夫酵母的蛋白质编码,利用处理,取得最佳化的多参数基因。
合成的bkt基因具有序列编号:8的氨基酸序列;合成的Crchyb基因具有序列编号:5的氨基酸序列;合成的Czchyb基因具有序列编号:6的氨基酸序列;而合成的Hpchyb基因具有序列编号:7的氨基酸序列。
基因克隆(gene cloning)
利用PCR分别将crtE基因、截断型HMG1基因(即tHMG1基因)、crtI基因、crtYB基因、crtR基因及crtS基因由红发夫酵母和马克斯克鲁维酵母扩增。表2总结用以扩增各基因的引物和其序列编号。
表2用以克隆的引物及其序列编号
利用序列编号:70、71、72及73的引物以PCR来扩增KlLac4启动子,扩增后的KlLac4启动子具有序列编号:63的核苷酸序列。利用序列编号:74、75、76及77的引物以PCR来扩增ScGapDH启动子,扩增后的ScGapDH启动子具有序列编号:64的核苷酸序列。利用序列编号:82、83、84及85的引物以PCR来扩增ScPGK启动子,扩增后的ScPGK启动子具有序列编号:65的核苷酸序列。利用序列编号:86、87、88及89的引物以PCR来扩增KlGapDH启动子,扩增后的KlGapDH启动子具有序列编号:66的核苷酸序列。利用序列编号:90、91、92及93的引物以PCR来扩增KlPGK启动子,扩增后的KlPGK启动子具有序列编号:67的核苷酸序列。利用序列编号:94、95、96及97的引物以PCR来扩增KlADHI启动子,扩增后的KlADHI启动子具有序列编号:68的核苷酸序列。利用序列编号:78、79、80及81的引物以PCR来扩增ScADHI启动子,扩增后的ScADHI启动子具有序列编号:69的核苷酸序列。
之后,利用限制酶SalI和EcoRI分别将扩增后的启动子克隆至质体pUC18,以方便后续建构重组多核苷酸序列。
基因组重组
利用各基因组中的重迭序列来重组各基因组。以TaKaRa Ex Taq系统进行融合PCR(fusion PCR)以重组各基因组。反应混合液包含0.2mM的特定引物、0.25mM的三磷酸脱氧核苷酸(deoxynucleoside triphosphate)、含有2mM MgCl2的1倍PCR缓冲液、2微升的DNA和2.5U的Ex Taq DNA聚合酶。PCR反应时间及温度为94℃(1分钟)、由58℃至53℃的黏着温度1分钟,以及72℃(最适时间);循环上述步骤10次。
培养酵母菌的最佳条件
为了解用以制备类胡萝卜素的最佳条件,将酵母菌工程株培养于包含1%酵母菌萃取物(Yeast Extract)、2%蛋白胨(Peptone)及2%D(+)-葡萄糖的YPG培养液中,并置于25℃、30℃或37℃的环境中培养3天。为测试细胞生长时碳源的利用,将酵母菌工程株培养于包含20%葡萄糖、20%半乳糖或20%甘油的YPG培养液中。
酵母菌转化(transformation)及菌株筛选
将酵母菌培养于包含1%酵母菌萃取物、2%蛋白胨及2%D(+)-葡萄糖的5毫升的YPG培养液中,并置于30℃、以200rpm的转速培养16小时。将各基因组以乳酸克鲁维酵母蛋白表达套组(K.lactis Protein Expression Kit,New England Biolabs)共转化至乳酸克鲁维酵母中,以表达各外源性基因。以高保真(high fidelity)的酶(PrimeSTAR MAX DNA聚合酶,TaKaRa)进行聚合酶连锁反应(即HiFi-PCR)来扩增各基因组;再将各基因组共同引入酵母菌中,藉由各序列中的重迭序列来进行同源重组,使各基因组以预先设计的顺序排列重组。之后,利用第一基因组的启动子序列和最后一组基因组的3’端序列可将所得重组产物同源重组至宿主细胞的基因体中。以对抗生素G418具有抗性的新霉素磷酸转移酶基因(neomycin phosphotransferase gene,Kan MX)作为标记基因,进行特定菌株的筛选。将10微升(μg)的标的DNA片段以等莫耳比例共转化至40微升的胜任细胞(competent cell)中。以BioRad系统(gene PluserXcellTM,Bio-Rad,Hercules,CA)在2毫米铝制比色管中进行电穿孔(1.0kV,400Ω及25μF电容)。之后,将细胞涂布于包含1%酵母菌萃取物、2%蛋白胨、2%葡萄糖及每毫升200微克(mg)的含有抗生素G418的YPG培养基上。
为确认各片段的位置,以QucikExtractTM DNA萃取溶液(EPICENTRE,Madison,Wisconsin)分解酵母菌细胞壁。之后,以长-PCR法(Long-PCR method,EmeraldAmp MAX PCR Master Mix,TaKaRa),辅以特定引物(序列编号:23-36)及自动电泳分析系统(automatic electrophoresis analysis system,Fragment AnalyzerTM Automated CE System,Advanced Analytical Technologies)来确认各基因组顺序的正确性。
反转录聚合酶连锁反应(Reverse Transcription-Polymerase Chain Reaction、RT-PCR)试验
利用DNA分离套组III(DNA Isolation Kit III,Roche)将基因体DNA由酵母菌中萃取纯化出来。以RNeasy微套组(QiAgen,Chatsworth,CA)将模板mRNA由酵母菌中纯化出来后,藉由反转录套组(SuperScriptTM II kit,Invitrogen)合成cDNA。以实时qPCR(real-time qPCR)来分析确认菌株中各启动子及其于不同培养温度下的驱动表达能力。利用通用探针数据库(Universal Probe Library Set,UPLS,LightCyclerW 480Probes Master,Roche),辅以特定引物对(扩增产物长度约为100至150bp),于LightCycler仪器(LightCycler 480,Roche)来定量各基因的相对表达量。表3总结用以分析各基因表达所使用的引物。
表3.反转录聚合酶连锁反应所使用的引物
抗氧化功效试验
在食品工业及农业相关研究中,常利用2,2'-二氮-双(3-乙基苯并噻唑-6-磺酸(2,2'-azino-bis(3-ethylbenzothiazoline-6-sulphonic acid)、ABTS)来测量食品的抗氧化功效。该试验系藉由添加过硫酸钠使ABTS转换为自由基阳离子后,测量自由基阳离子(蓝色)于吸收波长734纳米时的吸收光谱。ABTS自由基阳离子会与多种抗氧化剂反应。在反应中,蓝色的ABTS自由基阳离子会转换回无色的中性形式。可利用分光光度计来测量反应。由于此试验是以相对于水溶性维生素E相似物(Trolox)的抗氧化反应来计算表示,故亦称为水溶性维生素E相似物等量抗氧化能力(Trolox equivalent antioxidant capacity,TEAC)试验。操作时系先将ABTS受质加入细胞,再将细胞培养于YPG培养液,并置于25℃培养72小时;之后,冷冻干燥细胞,利用甲醇萃取色素以进行后续分析。
高效液相色谱(high performance liquid chromatography、HPLC)试验
收集培养3天的细胞,并以去离子水洗涤的。将细胞沉淀物置于冷冻干燥机中冷冻干燥。利用丙酮萃取干燥细胞中的类胡萝卜素,进行反相高效液相色谱试验。本发明是利用包含一PU-2089四元泵(PU-2089Quaternary Pump)及一870-UV智能型紫外光/可见光侦测器(870-UV intelligent UV-VIS detector)的佳世客(Jasco)HPLC仪器来进行相关分析。在操作时,是以野村化学(Nomura Chemical)制备的Develosil C30-UG管柱(3微米,ID 4.6毫米x L 250毫米-UG17346250W),辅以甲醇/甲基第三丁基醚(methyl tert-butyl ether,MTBE)/水(比例为81:15:4)及甲醇/甲基第三丁基醚/水(比例为7:90:3)作为移动相,来进行HPLC分离及定量。将流速设定为每分钟1毫升,并记录吸收波长460纳米时的色层分析图。
乙醇产量试验
本发明是利用气相分层分析法(Shimazdu,GC-14,日本),辅以一火焰游离侦检器(flame ionization detector,FID)及一不锈钢管柱(80/120Carbopack B/6.6%Carbowax,2米x 2毫米),并以氮气作为移动气体,来分析乙醇的产量。操作步骤包含将管柱以每分钟4℃的加热速度由80℃加热至150℃,柱入温度为180℃,侦测温度则为250℃。各发酵实验及分析皆独立重复三次。
实施例1建构重组多核苷酸序列
1.1 crtE-Kan-tHMG1
在许多生物体中,焦磷酸香叶香叶酯为生物合成诸如类胡萝卜素、吉贝素(gibberellins)、生育醇(tocopherols)、叶绿素(chlorophylls)、萜烯类(terpenes)及类萜(terpenoids)等医药化合物的重要前驱物。HMG-CoA还原酶(由HMG1基因所编码)及焦磷酸香叶香叶酯合成酶(由crtE基因所编码)则是HMG-CoA还原酶路径中的重要中间产物。已知截断型HMG-CoA还原酶(truncated HMG-CoA reductase,tHMG1)会减少反馈抑制,进而增加焦磷酸香叶香叶酯于酵母菌中的产量。因此,本发明首先建构一包含一crtE基因及一HMG1基因的重组多核苷酸序列;并利用对抗生素G418具有抗性的新霉素磷酸转移酶基因(Kan)作为标记基因,以进行后续菌株筛选分析。
利用BLAST来分析源自不同宿主细胞的HMG-CoA还原酶及焦磷酸香叶香叶酯合成酶的胺基因酸序列(图4a和5a)。基于功能区域(functional domain)中预测的氨基酸序列(图4b和5b),将各基因以宿主表达的最佳化密码子克隆或合成后,与适当的启动子连结,以建构出特定的基因组。
在操作上,利用序列编号:11及12的引物以PCR扩增crtE基因,藉由限制酶AgeI及NcoI将其引入载有KlLac4启动子的质体pUC18中,再利用序列编号:23及24的引物以PCR扩增得到KlLac4-crtE基因组。利用序列编号:94及95的引物以PCR扩增Kan基因,藉由限制酶AgeI和NcoI将其引入载有KlGapDH启动子的质体pUC18中,再利用序列编号:25和26的引物以PCR扩增得到KlGapDH-Kan基因组;其中序列编号:25的核苷酸序列部份互补于序列编号:24的核苷酸序列(即AGTATGGTAACGACCGTACAGGCAA与TTGCCTGTACGGTCGTTACCATACT);据此,KlGapDH-Kan基因组的5’端序列系与KlLac4-crtE基因组的3’端序列相互同源。利用序列编号:13及14的引物以PCR扩增tHMG1基因,藉由限制酶AgeI和NcoI将其引入载有ScADHI启动子的质体pUC18中,再利用序列编号:27和28的引物以PCR扩增得到ScADHI-tHMG1基因组;其中序列编号:27的核苷酸序列部份互补于序列编号:26的核苷酸序列(即GTGTACAATATGGACTTCCTCTTTTC与GAAAAGAGGAAGTCCATATTGTACAC);据此,ScADHI-tHMG1基因组的5’端序列系与KlGapDH-Kan基因组的3’端序列相同互源。
基于KlLac4-crtE基因组与KlGapDH-Kan基因组间的同源序列,以及KlGapDH-Kan基因组与ScADHI-tHMG1基因组间的同源序列,当三组基因组共转化至宿主细胞马克斯克鲁维酵母后,三组基因组会自发性地重组形成一重组多核苷酸序列crtE-Kan-tHMG1(总结于图6及表4)。将包含重组多核苷酸序列crtE-Kan-tHMG1的基因工程菌命名为Xd3.0。
表4 crtE-Kan-tHMG1基因组
1.2 crtI-crtE-Kan-crtYB-tHMG1
β-胡萝卜素是一种维生素A原类胡萝卜素(provitamin A carotenoid),已知可用以治疗红血球生成性原紫质病(erythropoietic protoporphyria)等疾病。此外,β-胡萝卜素亦经证实可减少女性更年期后罹患乳癌的机率,以及罹患老年性黄斑部病变(Age-related macular degeneration、AMD)的机率。在制备下游类胡萝卜素的过程中,β-胡萝卜素是一项重要的中游前驱物;而crtY基因(用以编码八氢茄红素合成酶)和crtB基因(用以编码茄红素环化酶)则为β-胡萝卜素生物合成路径中重要的中间产物。据此,实施例1.2系关于建构一包含一crtI基因、一crtE基因、一crtYB基因(用以编码一具备八氢茄红素合成酶和茄红素环化酶活性的双功能酶)、一tHMG1基因及一Kan标记基因的重组多核苷酸序列crtI-crtE-Kan-crtYB-tHMG1。
利用BLAST来分析茄红素环化酶域、反-异戊烯焦磷酸合成酶合成酶及NAD(P)-结合罗斯曼相似区域的氨基酸序列(图7a、7c和8a)。基于功能区域中预测的氨基酸序列(图7b、7d和8b),将各基因以宿主表达的最佳化密码子转殖或合成后,与适当的启动子连结,以建构出特定的基因组。
藉由与实施例1.1相似的建构策略,利用序列编号:15和16的引物以PCR扩增crtI基因,藉由限制酶AgeI和NcoI将其引入载有KlLac4启动子的质体pUC18中,再利用序列编号:23和29的引物以PCR扩增得到KlLac4-crtI基因组。利用序列编号:11及12的引物以PCR扩增crtE基因,藉由限制酶AgeI和NcoI将其引入载有ScPGK启动子的质体pUC18中,再利用序列编号:30和24的引物以PCR扩增得到ScPGK-crtE基因组。利用序列编号:94和95的引物以PCR扩增Kan基因,藉由限制酶AgeI和NcoI将其引入载有KlGapDH启动子的质体pUC18中,再利用序列编号:25及31放大得到KlGapDH-Kan基因组。利用序列编号:17及18的引物以PCR扩增crtYB基因,藉由限制酶AgeI和NcoI将其引入载有KlADHI启动子的质体pUC 18中,再利用序列编号:32和26放大得到KlADHI-crtYB基因组。利用序列编号:13和14的引物以PCR扩增tHMG1基因,藉由限制酶XhoI和NotI将其引入载有ScADHI启动子的质体pUC18中,再利用序列编号:27和28放大得到ScADHI-tHMG1基因组。
藉由各基因组间的同源序列,当五组基因组共转化至宿主细胞马克斯克鲁维酵母后,五组基因组会自发性地重组形成一重组多核苷酸序列crtI-crtE-Kan-crtYB-tHMG1(总结于图9及表5)。将包含该重组多核苷酸序列crtI-crtE-Kan-crtYB-tHMG1的基因工程菌株命名为Xd5.0。
表5 crtI-crtE-Kan-crtYB-tHMG1基因组
1.3crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1
为使β-胡萝卜素有效转换为虾红素,将二下游虾红素合成基因-crtS基因(用以编码β-胡萝卜素加氧酶)和crtR基因(用以编码p450还原酶)共转化至宿主细胞马克斯克鲁维酵母。在实施例1.3中,本发明建构一包含一crtI基因、一crtR基因、一crtE基因、一crtS基因、一crtYB基因(用以编码一具备八氢茄红素合成酶和茄红素环化酶活性的双功能酶)、一tHMG1基因和一Kan标记基因的重组多核苷酸序列crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1。
以催化域来分析β-胡萝卜素加氧酶和p450还原酶的保留区域(图10a和11a)。此外,亦分析各保留性区域中的保留性残基(图10b、11b和11c)。依据分析结果来建构重组多核苷酸序列crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1中的密码子。藉由相似的PGASO建构方法,利用序列编号:15和16的引物以PCR扩增crtI基因,再利用限制酶AgeI和NcoI将其转殖于载有KlLac4启动子的质体pUC18中,之后利用序列编号:23和33的引物以PCR扩增得到KlLac4-crtI基因组。利用序列编号:19和20的引物以PCR扩增crtR基因,再利用限制酶SfiI和NcoI将其转殖于载有ScGapDH启动子的质体pUC18中,之后利用序列编号:34和29的引物以PCR扩增得到ScGapDH-crtRI基因组。利用序列编号:11和12的引物以PCR扩增crtE基因,再利用限制酶AgeI和NcoI将其转殖于载有ScPGK启动子的质体pUC18中,之后利用序列编号:30和24的引物以PCR扩增得到ScPGK-crtE基因组。利用序列编号:98和99的引物以PCR扩增Kan基因,再利用限制酶AgeI和NcoI将其转殖于载有KlGapDH启动子的质体pUC18中,之后利用序列编号:25和35的引物以PCR扩增得到KlGapDH-Kan基因组。利用序列编号:21和22的引物以PCR扩增crtS基因,再利用限制酶AgeI和NcoI将其转殖于载有KlPGK启动子的质体pUC18中,之后利用序列编号:36和31的引物以PCR扩增得到KlPGK-crtS基因组。利用序列编号:17和18的引物以PCR扩增crtYB基因,再利用限制酶AgeI和NotI将其转殖于载有KlADHI启动子的质体pUC18中,之后利用序列编号:32和26的引物以PCR扩增得到KlADHI-crtYB基因组。利用序列编号:13和14的引物以PCR扩增tHMG1基因,再利用限制酶NotI和XhoI将其转殖于载有ScADHI启动子的质体pUC18中,之后利用序列编号:27和28的引物以PCR扩增得到ScADHI-tHMG1基因组。
当将七组基因组共转化至宿主细胞马克斯克鲁维酵母后,七组基因组会藉由基因组间的同源序列而自发性地重组形成一重组多核苷酸序列crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1(总结于图12和表6)。将包含该重组多核苷酸序列crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1的基因工程菌株命名为Xd7-3。
表6 crtI-crtR-crtE-Kan-crtS-crtYB-tHMG1基因组
基因工程菌株Xd7-3应可用以制备红色类胡萝卜素-3R、3’R-虾红素立体异构物。然而,随着黄色类胡萝卜素(β-胡萝卜素和玉米黄质)的表达累积,可发现Xd7-3会呈现的黄色(图13a和表7)。推测可能原因为红发夫酵母的β-胡萝卜素加氧酶和P450还原酶的酶功效不佳,或/和ScPGapDH的启动子强度过低。
表7.基因工程菌株野生型、Xd7-3、Cr1、Cz5和Hp9的类胡萝卜素浓度
a数据为三次独立实验的平均值。类胡萝卜素的增加倍数系相对于具有最低含量的菌株(该菌株的表达量设定为1)。
b-:无法侦测到
1.4crtI-crtE-ChYb-Kan-CrBKT-crtYB-tHMG1
为了制备3S、3’S-虾红素立体异构物,将二虾红素合成基因-bkt基因(用以编码β-胡萝卜素酮醇酶)和ChYb基因(用以编码β-胡萝卜素羟化酶)共转化至宿主细胞马克斯克鲁维酵母中。
为建构重组多核苷酸序列crtI-crtE-ChYb-Kan-CrBKT-crtYB-tHMG1,先分析β-胡萝卜素酮醇酶的保留性区域的氨基酸序列(图14a);图14b则为各保留性区域中的保留性残基。基于分析结果,将各基因以宿主表达的最佳化密码子转殖或合成后,与KlPGK启动子连结,以建构出特定的基因组。
此外,为筛选出其余在虾红素生物合成路径中的重要酶基因,分别由莱茵衣藻、小球藻和雨生红球藻分离ChYb基因(即Crchyb基因、Czchyb基因和Hpchyb基因),第15a和15b为该些基因的保留性区域分析结果。将该些基因分别以宿主表达的最佳化密码子转殖或合成而后,与适当的启动子连结,以建构出特定的基因组。。
利用与建构crtE-Kan-tHMG1或crtI-crtE-Kan-crtYB-tHMG1相似的方法来建构该重组多核苷酸序列crtI-crtE-ChYb-Kan-CrBKT-crtYB-tHMG1,其中ChYb基因可以是Crchyb基因、Czchyb基因或Hpchyb基因。简单来说,以限制酶AgeI和NcoI将crtI基因引入载有KlLac4启动子的质体pUC18后,利用序列编号:23和33的引物以PCR扩增得到KlLac4-crtI基因组。以限制酶AgeI和NcoI将crtE基因引入载有ScGapDH启动子的质体pUC 18后,利用序列编号:34和29的引物以PCR扩增得到ScGapDH-crtE基因组。以限制酶XhoI和NotI将ChYb基因(即Crchyb基因、Czchyb基因或Hpchyb基因)引入载有ScPGK启动子的质体pUC18后,利用序列编号:30和24的引物以PCR扩增得到ScPGK-ChYb基因组。以限制酶AgeI和NcoI将Kan基因引入载有KlGapDH启动子的质体pUC18后,利用序列编号:25和35的引物以PCR扩增得到KlGapDH-Kan基因组。以限制酶XhoI和NotI将BKT基因引入载有KlPGK启动子的质体pUC18后,利用序列编号:36和31的引物以PCR扩增得到KlPGK-BKT基因组。以限制酶AgeI和NotI将crtYB基因引入载有KlADHI启动子的质体pUC18后,利用序列编号:32和26的引物以PCR扩增得到KlADHI-crtYB基因组。以限制酶XhoI和NotI将tHMG1基因引入载有ScADHI启动子的质体pUC18后,利用序列编号:27和28的引物以PCR扩增得到ScADHI-tHMG1基因组。
藉由相似的建构概念,各基因组间的同源序列可使七组基因组在宿主细胞马克斯克鲁维酵母中进行同源重组,进而形成一重组多核苷酸序列crtI-crtE-ChYb-Kan-CrBKT-crtYB-tHMG1,其中该ChYb基因可以是Crchyb基因、Czchyb基因或Hpchyb基因(总结于图16和表8)。
表8 crtI-crtE-ChYb-Kan-CrBKT-crtYB-tHMG1基因组
接着,将建构的重组多核苷酸序列(即crtI-crtE-Crchyb-Kan-CrBKT-crtYB-tHMG1、crtI-crtE-Hpchyb-Kan-CrBKT-crtYB-tHMG1和crtI-crtE-Czchyb-Kan-CrBKT-crtYB-tHMG1)分别引入宿主细胞马克斯克鲁维酵母的基因体中(图16)。将包含重组多核苷酸序列crtI-crtE-Hpchyb-Kan-CrBKT-crtYB-tHMG1的基因工程菌株命名为Hp9;将包含重组多核苷酸序列crtI-crtE-Crchyb-Kan-CrBKT-crtYB-tHMG1的基因工程菌株命名为Cr1;而将包含重组多核苷酸序列crtI-crtE-Czchyb-Kan-CrBKT-crtYB-tHMG1的基因工程菌株命名为Cz5。
实施例2分析包含实施例1.4所述的重组多核苷酸序列的基因工程菌株
实施例2将进一步分析实施例1.4所建构的基因工程菌株-Cr1、Cz5和Hp9。其中,先于实施例2.1中确认各基因组和类胡萝卜素的表达后,再于实施例2.2来决定宿主表达类胡萝卜素的最佳条件。
2.1实施例1.4的重组多核苷酸序列的表达
经过10次继代培养后,筛选出稳定表达菌株Cr1、Cz5和Hp9。如第13a和表7所示,相较于Crchyb和Czchyb,Hpchyb具有较强的β-胡萝卜素羟化酶活性。利用长-PCR方法(EmeraldAmp MAX PCR Master Mix,TaKaRa)进一步检验各菌株的基因组的排列顺序,可发现各稳定表达的菌株皆具有原始设计的基因组排列顺序(图13b和13c)。
接着,利用50毫升的发酵培养液来比较各基因工程菌株的表达。经过3天培养后,观察细胞生长曲线可知,相较于野生型、Cr1和Xd7-3菌株,Hp9和Cz5菌株生长较为快速(图17c)。该些菌株(特别是Hp9)培养液的颜色皆会明显地由对照组的乳白色转变为红或深橘色(图17a和17b)。
利用丙酮萃取各酵母菌中的表达色素,据以评估类胡萝卜素于各菌株中的表达量。以全光谱紫外光/可见光分光光度计来测量类胡萝卜素和游离形式的类胡萝卜素化合物(包含β-胡萝卜素、虾红素、斑螯黄质和玉米黄质)的总量。所有类胡萝卜素化合物的吸收光谱皆介于400纳米到530纳米之间(结果未显示)。除了野生型,由基因工程菌株(即Xd7-3、Cr1、Cz5和Hp9)萃取出的类胡萝卜素的吸收光谱亦介于400纳米至530纳米之间(图17d)。
为分析类胡萝卜素的成分,利用HPLC来检验类胡萝卜素的成分;藉由冲提时间差可分离游离形式的类胡萝卜素化合物,例如虾红素的冲提时间为7.8分钟,玉米黄质的冲提时间为9.7分钟,斑螯黄质的冲提时间为12.8分钟,而β-胡萝卜素的冲提时间则为32分钟。以标准曲线检测各基因工程菌株中β-胡萝卜素表达量;结果显示,Xd7-3菌株的表达量为每公克244.7微克,Cr1菌株的表达量为每公克59.6微克,Cz5菌株的表达量为每公克93.9微克,而Hp9菌株的表达量则为每公克224.4微克;亦即,Hp9菌株的产量是Cr1菌株产量的3.8倍。此外,除了野生型和Xd7-3菌株,所有具有藻类bkt和ChYb基因的基因工程菌株皆可于菌株中表达累积斑螯黄质;其中,Cr1菌株的斑螯黄质表达累积量为每公克18.4微克,Cz5菌株的斑螯黄质表达累积量为每公克12.8微克,而Hp9菌株的斑螯黄质表达累积量为每公克39.8微克(表7);亦即,Hp9菌株生产斑螯黄质的速率是Cz5菌株的3.1倍。
将由莱茵衣藻萃取的藻类β-胡萝卜素羟化酶基因Crchyb,由小球藻萃取的Czchyb基因,或由雨生红球藻萃取的Hpchyb基因和其它6种参与合成类胡萝卜素的基因共转化至一酵母菌宿主的基因体中。相较于由红发夫酵母萃取的真菌基因,三种藻类基因(即Crchyb、Czchyb和Hpchyb)皆可有效地将β-胡萝卜素转换为下游的类胡萝卜素。此外,相较于表达Crchyb和Czchyb的菌株,表达Hpchyb的菌株可生产较高量的类胡萝卜素;亦即,Hpchyb较Crchyb和Czchyb更具合成/转换功效。该些结果指出,β-胡萝卜素羟化酶在类胡萝卜素的生物合成过程中扮演着重要的角色。
由HPLC于UV450纳米的光谱测定结果(图18a和18b)可知,基因工程菌株会表达游离形式的斑螯黄质(高峰1)、游离形式的β-胡萝卜素(高峰6)和某些未知的代谢产物(高峰2、3、4、5、7和8)。据此,基因工程菌株可用以制备类胡萝卜素及其衍生物,例如玉米黄质、3S、3’S-虾红素和/或其酯化衍生物。
2.2实施例1.4的重组多核苷酸序列的最佳表达条件
在本实施例中,将测定用以表达类胡萝卜素及其衍生物的最佳条件;其中,实施例2.2.1为评估表达的最佳温度,而实施例2.2.2则为确认表达的最佳培养溶液。
2.2.1最佳温度
为增加本发明载体的类胡萝卜素产量,将一或多拷贝数的本发明载体整合至Cz5菌株;所得的基因工程菌株为Cz30菌株。相较于Cz5菌株,Cz30菌株更具一明显的红色转变(图19a)。
为评估用以制备类胡萝卜素的最佳条件,分别将Cz5和Cz30培养于YPG培养液中,并置于25℃、30℃和37℃环境中培养3天。之后,可观察到培养于25℃和30℃中的培养液(包含Cz5或Cz30)皆会转变为红色,而培养于37℃中的培养液(包含Cz5或Cz30)则依然为乳白色(图19b)。此外,在培养2天后,仅有培养于25℃的Cz30会转变为红色。结果显示,25℃为用以制备类胡萝卜素的最佳温度,且Cz30的产量高于Cz5的产量。
进一步分析Cz5和Cz30菌株于不同培养温度下的基因表达。将二菌株培养于25℃、30℃或37℃的环境中;48小时后,萃取各菌株的mRNA。如图19c所示,不论在何种培养温度下,Cz30菌株中的转殖基因表达量皆高于Cz5菌株中的转殖基因表达量;此结果与Cz30可产生高量的类胡萝卜素,并显著转换为红色的结果相符。此外,转殖基因于30℃的表达量明显高于25℃和37℃时的表达量。基于菌株培养于25℃时的颜色转变最为明显,25℃系为酶反应的最佳条件(图19c)。
基于八氢茄红素去饱合酶(由crtI基因所编码)和β-胡萝卜素酮醇酶(由BKT基因所编码)在3S、3’S-虾红素的生物合成过程中扮演着极为重要的角色,分别利用二个较强的启动子-pLac4和pKlPGK来驱动该些基因的表达。据此,CrtI和CrBKT为各基因组中表达量最高的二基因(图19c)。
HPLC光谱分析更进一步确认,Cz30基因工程菌株会累积较高量的β-胡萝卜素、斑螯黄质和酯化虾红素衍生物(即虾红素单酯体和虾红素双酯体,图20a和20b)。
上述结果显示,相较于Cz5菌株,Cz30可产生较高量的类胡萝卜素;此外,结果亦指出,25℃为生产胡萝卜素的最佳温度。
2.2.2最佳培养液
为确认菌株生长时所使用的碳源,分别将野生型马克斯克鲁维酵母和基因工程菌株培养于包含20%葡萄糖、20%半乳糖和20%甘油的YPG培养液中。于25℃培养2天后,野生型菌株的培养液依旧呈现乳白色,而Cz30的培养液则会呈现黄色(葡萄糖)、橘色(半乳糖)或红色(甘油)(图21a)。结果指出,依据不同的添加物(即葡萄糖、半乳糖或甘油),Cz30可产生并累积不同成分的类胡萝卜素。不同碳源间颜色的差异有可能是因累积不同浓度的类胡萝卜素所导致。亦或是,因生成不同类型的类胡萝卜素所导致,例如黄色类胡萝卜素(β-胡萝卜素和玉米黄质)和粉红色到红色的类胡萝卜素(斑螯黄质、虾红素和其它酯化虾红素衍生物)(图21a)。然而,培养5天后,仅培养于包含20%甘油的培养液的菌株会持续呈现红色,其余培养于包含葡萄糖或半乳糖的培养液的菌株则皆会转回乳白色。
于包含甘油的培养液中培养48和72小时后,收集基因工程菌株Cz5和Cz30的检体,并利用实时PCR试验来分析各菌株的mRNA的表达量。结果显示,不论是于25℃、30℃或37℃的环境中,48小时后,CzBKT基因的表达量皆会高于HpchyB基因的表达量(表9)。此外,培养72小时后,HpchyB基因的表达量则会高于CzBKT基因的表达量,据以将斑螯黄质转换为虾红素(表9)。
表9培养于包含20%甘油的YPG培养液中,基因工程菌株的基因表达量
(1)RNA表达量倍数系相对于具有最低表达量的菌株(该菌株的表达量设定为1)。
(2)-:无法侦测到
基于LC的光谱分析结果,相较于包含20%半乳糖的培养液,将Cz30培养于含有20%甘油的培养液中,可累积较高量的β-胡萝卜素和斑螯黄质(表10)。经皂化(saponification)处理后,利用LC/MS来分析确认所得化合物,结果显示Cz30生产的类胡萝卜素包含β-胡萝卜素、斑螯黄质和游离形式的虾红素(图22)。
表10.野生型、Cz5和Cz30菌株所生产的类胡萝卜素浓度
a—:无法侦测到
有趣的是,相较于包含其它碳源的培养液,培养于包含甘油的培养液的Cz30所产生的红色转变最为显著;此结果代表Cz30将可用以发展绿色工业。此外,将Cz30培养于包含甘油的培养液5天后,其培养液仍持续呈现红色。
接着,分别萃取类胡萝卜素自野生型和Cz30菌株,并利用ABTS受质反应来分析其抗氧化功效。将菌株培养于25℃的YPG培养液72小时后,冷冻干燥菌株,再利用甲醇将色素萃出。相较于野生型(52.3%),Cz30具有较高的自由基清除功效(72.1%)(图23a)。有鉴于野生型菌株亦具有抗氧化能力,推估在水溶性维生素E相似物等量抗氧化能力(Trolox equivalent antioxidant capacity、TEAC)的试验中,约有20%的去自由基能力是源自于Cz30所产生的类胡萝卜素,而1克菌株(干重)的去自由基能力约等于1.95毫克的水溶性维生素E相似物(Trolox)的去自由基能力(第23b图)。
上述结果指出,包含20%甘油的培养液为制备本发明类胡萝卜素的最佳培养环境,而制备出的类胡萝卜素具有抗氧化功效。
实施例3改善虾红素的产量
基于β-胡萝卜素酮醇酶和β-胡萝卜素羟化酶在虾红素的生物合成过程中极为重要,进一步将虾红素合成基因组(即crtI-crtE-Hpchyb-Kan-Hpchyb-CrBKT-crtYB-tHMG1)与一额外的ChYb基因组共转化至宿主基因体中,藉以制备基因工程菌株CA6(图24a)。转殖后的菌株培养液会呈现红色。
为增加制备虾红素时重要酶的表达量,将虾红素合成酶基因-bkt(用以编码β-胡萝卜素酮醇酶)和ChYb(用以编码β-胡萝卜素羟化酶)整合至CA6菌株的rDNA的内转录间隔区(internal transcribed spacer、ITS);制得的基因工程菌株称为CA6-ITS。该基因组包含aur-Hpchyb-CrBKT及一启动子(图24b)。Hpchyb和CrBKT的基因表达量会随着主要酶拷贝数的增加而增加(图24c)。
为了解细胞生长所使用的碳源,将基因工程菌株CA6-ITS培养于包含或不包含10%甘油的YPG培养液中。于25℃培养2天后,相较于培养在不包含甘油的YPG培养液的菌株,培养于包含10%甘油的YPG培养液的菌株会产生较为显著的红色变化(图21b)。表11进一步指出,10%甘油即可有效引发CA6-ITS菌株制造虾红素。
表11.CA6-ITS菌株所生产的类胡萝卜素浓度
此外,亦将虾红素合成基因组与一高拷贝数表达载体RS426共转化至宿主基因组中,以制得CA6-质体菌株(图24d)。基因组将会于宿主内自动与质体进行重组;转殖株则会呈现橘到红的颜色。该高拷贝数表达载体可大量表达本发明酶,进而更有效率地将前驱物转换为虾红素。
基于HPLC的光谱分析结果,基因工程菌株CA6-ITS可生产游离形式的虾红素、玉米黄质、斑螯黄质和β-胡萝卜素,其冲提时间分别为7.76、9.9、12.25和31.40分(图24e)。虾红素、玉米黄质、斑螯黄质、和β-胡萝卜素的产量则分别为每公克19.48、21.7、4.40和501.57微克(表12)。该些结果显示,增加用以编码β-胡萝卜素羟化酶的ChYb的基因拷贝数/表达量可改善类胡萝卜素的产量。
表12.基因工程菌株的类胡萝卜素浓度
a—:无法侦测到
因此,本实施例提供了二种能有效将虾红素前驱物转换为虾红素的基因工程菌株-CA6和CA6-ITS。结果亦显示,相关基因的高拷贝数对于虾红素的制备极为重要。
实施例4制备单酯或双酯形式的天然类胡萝卜素组合物
相较于非极性的类胡萝卜素,游离形式的虾红素的极性端(polar end)虽较易被生物体所吸收,然亦极易被氧化。自然界中的虾红素多以脂肪酸-酯类的形式存在;例如绿色藻类即具有一或二个脂肪酸,以形成较于稳定的单酯或双酯形式。酯化虾红素经胆固醇酯酶(cholesterol esterase)水解后,可包覆于微胞(micelle)中,藉由小肠细胞的吸收作用进入生物体内。
本实施例将分析基因工程菌株中的类胡萝卜素酯类及其几何异构物。由于克莱布特里阴性酵母菌(Crabtree negative yeast)-马克斯克鲁维酵母具有高生长率和高产量,且可有效将羟基团转换形成诸如辛酸乙酯(octanoic acid-ethyl ester)、乙酸-2-苯基乙基酯(acetic acid-2-phenylethyl ester)和癸酸-乙基酯(decanoic acid-ethyl ester)等具有不同长度碳链的脂肪酸的单酯或双酯结构,因此本实施例系以该酵母菌作为宿主细胞进行相关试验。
由藻类分离的天然虾红素的羟基通常会与脂肪酸键结,藉以形成酯化虾红素。相较于合成或由细菌所产生的非酯化虾红素(即游离/自由形式的虾红素),酯化虾红素具有较高的稳定性及较佳的生物功效。为制备单酯或双酯形式的虾红素,在加入半乳糖至CA6-ITS菌株的同时或之后,加入脂肪酸(0.01%或0.1%的辛酸)。由图25a及25b可知,相较于对照组,加入辛酸会使菌株的颜色转换为较深的红色。
利用质谱分析仪(LC-MS/MS)来分析双酯类中饱和脂肪酸的组合。结果指出,制备出的类胡萝卜素包含非尼基叶黄素、斑螯黄质、海胆酮、β-隐黄素、酯化金盏花红素(esterified adonixanthin)、茄红素、八氢西红柿红素、β-胡萝卜素和酯化虾红素(图26a及26b)。
实施例5分析包含本发明重组多核苷酸序列的基因工程菌株
类胡萝卜素化合物可基于其分别位于或靠近化合物两端的二环结构来中和细胞内或外的单态和三态氧分子。此外,类胡萝卜素化合物亦可辅助Cz30减少因紫外光照射、溶剂压力和氧化自由基(reactive oxygen species、ROS)所造成的伤害。Cz30可藉由减降生长细胞中脂质的过度氧化来抵抗环境压力。据此,本公开内容的基因工程菌株可用以制备具有附加价值的代谢产物,并改善产量。
5.1增加宿主细胞对抗压力的耐受性
图23指出,相较于野生型,Cz30的菌株萃取物具有抗氧化功效。在本实施例中,该分别利用紫外光照、糠醛、乙醇和异丁醇处理来检测Cz30的抗压功效。
分别以紫外光照射野生型和Cz30菌株5、10或20分钟;接着,连续稀释该些菌株,并将其涂覆培养于YPG培养基。48小时后,仅少数经紫外光照射20分钟的Cz30可生长于YPG培养基(图27a)。该结果显示,Cz30所表达的类胡萝卜素可有效减少紫外光的伤害,使其相较于野生型菌株具有较快的生长速度。
在生物炼制的应用领域中,植物生质(plant biomass)是地球上最丰富的可再生资源的一,且被视为发展永续经营使用的重要基石。植物的可再生资源可转换为生物产物,例如生物燃料、生物化学品、生物润滑剂及生物可降解材料等。举例来说,相关业界常使用诸如酸水解(acid hydrolysis)、蒸汽爆裂(steam explosion)、氨纤维膨胀(ammonia fiber expansion)、有机溶剂法(organosolv)、亚硫酸盐预处理(sulfite pretreatment)、碱性湿氧化(alkaline wet oxidation)、臭氧预处理(ozone pretreatment)和酶处理等各式处理技术来破坏木质纤维素(lignocellulose),以取得植物生质中的糖类。然而,在利用酸和蒸气来处理木质纤维素的过程中,往往会产生大量的毒性物质,例如由半纤维素和纤维素所释放的糠醛,由木质素(lignin)所释放的乙醇和醛类,以及由生物反应剂所释放的重金属。因此,本实施例亦检测Cz30菌株对糠醛的抗压功效。如图27b的结果所示,Cz30菌株可容忍浓度为100mM的糠醛,相较的下,野生型菌株仅能忍受约80mM的糠醛。
接着,进一步检测野生型和Cz30菌株对乙醇及异丁醇的耐受性。分别将菌株置于包含0、4、8或12%乙醇的环境中24小时,或是包含0、0.5、1或2%异丁醇的环境中24小时;之后,连续稀释该些菌株,并将其涂覆培养于YPG培养基48小时。结果显示,经12%乙醇(图27c)和2%异丁醇(图27d)处理24小时后,仅少量的Cz30可维持生长。据此,类胡萝卜素可使Cz30具备抗氧化功效,进而有效提升对乙醇及异丁醇的抗性。
上述结果指出,类胡萝卜素的抗氧化活性可保护宿主细胞(即Cz30),有效抵抗紫外光照射、糠醛、乙醇和异丁醇等各式环境压力所造成的伤害。
5.2增加宿主细胞于发酵过程中对乙醇的耐受性和产量
在发酵过程中,诸如乙醇等产物的累积往往会对宿主细胞产生毒性伤害,进而限制影响整体的生产制备。细胞会产生氧化自由基来因应外来压力,该些自由基通常会进一步使脂质过氧化来攻击细胞膜。细胞膜是生物体对外的第一道防线,可调控细胞对外来压力的反应,也极易受到外界有机溶液的影响。
为测试野生型和基因工程菌株Cz30对乙醇的耐受性,分别将二种菌株培养于包含不同浓度的乙醇的YPG培养液中(图28a)。在不含乙醇的情况下,野生型和Cz30菌株具有相似的生长速度。在含有2、4或6%乙醇的培养环境中,可发现野生型菌株的生长会明显地受到乙醇的抑制;相较的下,Cz30仅会受到轻微的影响。亦即,相较于野生型菌株,Cz30菌株在经过24小时的乙醇培养后,具有较高的细胞密度(图28a)。此结果显示,Cz30所表达的类胡萝卜素可减少溶剂对菌株所造成的伤害,因而相较于野生型菌株,Cz30具有较快的生长速度。
为测试乙醇的产量,分别将野生型和Cz30菌株培养于包含20%半乳糖的YPG培养液中。72小时后,可观察到相较于野生型(2.5%),Cz30会产生更高量的乙醇(3.5%)(图28b)。因此,Cz30所表达的类胡萝卜素明显具备抗氧化功效。
上述结果指出,类胡萝卜素可保护宿主细胞,减少发酵过程中乙醇所造成的伤害,进而改善整体的产量。
5.3改善宿主细胞对毒素的耐受性和产量
自然界中,次级代谢物的产量通常会少于其前驱物。为了能得到足量的化合物,半合成(semi-synthesis)提供了一种将中间产物转换为最终产物或相似物的化学方法。然而,化学反应往往需要大量的人力,且会造成有机污染。一般来说,次级代谢物和其前驱物皆会对宿主细胞造成毒性伤害,影响整体的合成制造。
在紫杉醇的半合成医药产业中,浆果赤霉素III(Baccatin III)是一极为重要的前驱物。浆果赤霉素III的前趋化合物-10-去乙酰浆果赤霉素III(10-deacetyl baccatin III,10DB),可由观赏植物红豆杉(Taxus baccata)中大量萃取,是一种较为廉价且较具经济价值的前驱物。在处理该些前驱物和最终产物时,常使用乙醇作为溶剂来进行溶解及萃取。
在本实施例中,是利用预先溶于乙醇的10-去乙酰浆果赤霉素III来分析Cz30的抗毒性功效。分别将野生型和Cz30菌株培养于包含0、0.8、1.6或3.2mM的10-去乙酰浆果赤霉素III的培养液中。24小时后,连续稀释该些菌株,并涂覆培养于YPG培养基,培养48小时。如图29a所示,在经过溶于12%乙醇的3.2mM的10-去乙酰浆果赤霉素III处理后,相较于野生型,Cz30菌株具有较佳的生长状态。此外,亦将菌株培养于包含不同浓度的10-去乙酰浆果赤霉素III和乙醇的YPG培养液中,藉以测试菌株对10-去乙酰浆果赤霉素III的耐受性(图29b)。结果指出,在经过0.4-1.2mM的10-去乙酰浆果赤霉素III处理后,相较于野生型,Cz30菌株具有较佳的生长状态。相较于包含4%乙醇或6%乙醇的培养液,包含0.8mM的10-去乙酰浆果赤霉素III和4%乙醇的培养液,或是包含1.2mM的10-去乙酰浆果赤霉素III和6%乙醇的培养液,会对菌株产生更大的毒性伤害(图29b)。进一步利用生长曲线试验来证实该结果,其系分别将菌株培养于包含0.8mM的10-去乙酰浆果赤霉素III和4%乙醇的培养液(图30a),或是包含1.2mM的10-去乙酰浆果赤霉素III和6%乙醇的培养液(图30b)。
上述结果指出,类胡萝卜素可保护宿主细胞,减少生医药物的前驱物(例如10-去乙酰浆果赤霉素III)对细胞造成的毒性伤害。此外,亦利用基因工程菌株来测试10-去乙酰浆果赤霉素III与浆果赤霉素III(baccatin III)之间的生物转换(图31)。结果指出,相较于其它菌株,包含较高浓度的类胡萝卜素的YD8菌株,可将10-去乙酰浆果赤霉素III转换为更多的浆果赤霉素III(表13)。结果指出,包含类胡萝卜素的菌株可改善其生物转换能力。
表13.基因工程菌株的浆果赤霉素III生物转换
-无法侦测
总结上述,本公开内容提供了不同的重组多核苷酸序列,该些重组多核苷酸序列皆可用于活体中制备类胡萝卜素。基于本发明重组多核苷酸序列具备高产量的特性,本公开内容建立数株分别包含不同重组多核苷酸序列的基因工程菌株。此外,本公开内容亦确认用以表达本发明重组多核苷酸序列/基因工程菌株的最佳条件;该表达条件可大幅提升产量,进而提供科学或产业领域一种生物合成虾红素的新方法。利用本发明重组多核苷酸序列所制备的产物可保护基因转殖细胞,避免受到环境压力、发酵产物或生医药物的前驱物所造成的伤害;藉以提升基因转殖细胞的产业应用性。
虽然上文实施方式中揭露了本发明的具体实施例,然其并非用以限定本发明,本发明所属技术领域中具有通常知识者,在不悖离本发明的原理与精神的情形下,当可对其进行各种更动与修饰,因此本发明的保护范围当以附随申请专利范围所界定者为准。
序列表
<110> 中央研究院
李文雄
<120> 用以制备虾红素的重组多核苷酸序列及其应用
<130> 5454/0147PWO2
<160> 99
<170> PatentIn version 3.5
<210> 1
<211> 1128
<212> DNA
<213> 人工序列
<220>
<223> crtE 基因
<400> 1
atggactacg ccaacatcct caccgccatc cccctcgagt tcacccccca ggacgacatc 60
gtcctcctcg agccctacca ctacctcggc aagaaccccg gcaaggagat ccgctcccag 120
ctcatcgagg ccttcaacta ctggctcgac gtcaagaagg aggacctcga ggtcatccag 180
aacgtcgtcg gcatgctcca caccgcctcc ctcctcatgg acgacgtcga ggactcctcc 240
gtcctccgcc gcggctcccc cgtcgcccac ctcatctacg gcatccccca gaccatcaac 300
accgccaact acgtctactt cctcgcctac caggagatct tcaagctccg ccccaccccc 360
atccccatgc ccgtcatccc cccctcctcc gcctccctcc agtcctccgt ctcctccgcc 420
tcctcctcct cctccgcctc ctccgagaac ggcggcacct ccacccccaa ctcccagatc 480
cccttctcca aggacaccta cctcgacaag gtcatcaccg acgagatgct ctccctccac 540
cgcggccagg gcctcgagct cttctggcgc gactccctca cctgcccctc cgaggaggag 600
tacgtcaaga tggtcctcgg caagaccggc ggcctcttcc gcatcgccgt ccgcctcatg 660
atggccaagt ccgagtgcga catcgacttc gtccagctcg tcaacctcat ctccatctac 720
ttccagatcc gcgacgacta catgaacctc cagtcctccg agtacgccca caacaagaac 780
ttcgccgagg acctcaccga gggcaagttc tccttcccca ccatccactc catccacgcc 840
aacccctcct cccgcctcgt catcaacacc ctccagaaga agtccacctc ccccgagatc 900
ctccaccact gcgtcaacta catgcgcacc gagacccact ccttcgagta cacccaggag 960
gtcctcaaca ccctctccgg cgccctcgag cgcgagctcg gccgcctcca gggcgagttc 1020
gccgaggcca actccaagat cgacctcggc gacgtcgagt ccgagggccg caccggcaag 1080
aacgtcaagc tcgaggccat cctcaagaag ctcgccgaca tccccctc 1128
<210> 2
<211> 1638
<212> DNA
<213> 人工序列
<220>
<223> HMG1 基因
<400> 2
atggagctca ccgccaacga catccagaag aagcgcgccg ccaagctcgt ccccaagccc 60
tactccaacc acaacgagaa gcagtccccc tcctcctccg cctccaacga gaccaaggtc 120
gagaccatca ccgagcgcat gcccgtcgtc gcctccatcc agcacgagat cgacaccgag 180
tccgactccg acaacggccc ctccgaggtc cgccccgtcg aggagctcgt cgaggtcctc 240
aagggcggcg acgtcaagtc cctctccaac cgcgaggtcg tctccctcgt cgtcgccaac 300
aagctccccc tctacgccct cgagaagcag ctcggcgaca ccacccgcgc cgtcgtcgtc 360
cgccgcaagg ccctcgccat cctcgccgac gcccccgtcc tcaccaccga gcgcctcccc 420
tacaagaact acgactacaa ccgcgtcttc ggcgcctgct gcgagaacgt catcggctac 480
atgcccctcc ccgtcggcgt catcggcccc ctcatgatcg acggcgtcta ctaccacatc 540
cccatggcca ccaccgaggg ctgcctcgtc gcctccgcca tgcgcggctg caaggccatc 600
aactccggcg gcggcgtcac caccgtcctc accaaggacg gcatgacccg cggcccctgc 660
gtccgcttcc cctccctcaa gcgcgccggc gcctgcaaga tctggctcga ctccgaggag 720
ggccagaaca agatcaagaa ggccttcaac tccacctccc gcttcgcccg cctccagcac 780
gtccagaccg ccctcgccgg cgacctcctc ttcatccgct tccgcaccac caccggcgac 840
gccatgggca tgaacatgat ctccaagggc gtcgagttct ccctccacca gatggtcgag 900
gagtacggct ggaaggacat ggagatcgtc tccgtctccg gcaactactg catggacaag 960
aagcccgccg ccatcaactg gatcgagggc cgcggcaagt ccgtcgtcgc cgaggccaac 1020
atccccggcg acgtcgtccg caaggtcctc aagtccgacg tcaaggccct cgtcgacctc 1080
aacatctcca agaacctcat cggctccgcc atggccggct ccatcggcgg cttcaacgcc 1140
cacgcctcca acctcgtcac cgccgtctac ctcgccctcg gccaggaccc cgcccagaac 1200
gtcgagtcct ccaactgcat gaccctcatg aaggaggtcg acggcgacct ccgcatctcc 1260
gtctccatgc cctccatcga ggtcggcacc atcggcggcg gcaccatcct cgagccccag 1320
tccgccatgc tcgacctcct cggcgtccgc ggcccccacc ccaccgagcc cggcaagaac 1380
gcccgccagc tcgccaagat cgtcgcctcc gccgtcatgg ccggcgagct ctccctctgc 1440
tccgccctcg ccgccggcca cctcgtccag tcccacatgg tccacaaccg cgccaagcag 1500
cccgtcgcca ccggcgccgg cgcccccgtc tccggccccg gccccgtctc cacccccgcc 1560
atggccacca acggcaagga gctctccgcc gagcagctca agaccctcaa ggagggctcc 1620
gtcatctgca tcaagtcc 1638
<210> 3
<211> 1746
<212> DNA
<213> 人工序列
<220>
<223> crtI 基因
<400> 3
atgggcaagg agcaggacca ggacaagccc accgccatca tcgtcggctg cggcatcggc 60
ggcatcgcca ccgccgcccg cctcgccaag gagggcttcc aggtcaccgt cttcgagaag 120
aacgactact ccggcggccg ctgctccctc atcgagcgcg acggctaccg cttcgaccag 180
ggcccctccc tcctcctcct ccccgacctc ttcaagcaga ccttcgagga cctcggcgag 240
aagatggagg actgggtcga cctcatcaag tgcgagccca actacgtctg ccacttccac 300
gacgaggaga ccttcaccct ctccaccgac atggccctcc tcaagcgcga ggtcgagcgc 360
ttcgagggca aggacggctt cgaccgcttc ctctccttca tccaggaggc ccaccgccac 420
tacgagctcg ccgtcgtcca cgtcctccag aagaacttcc ccggcttcgc cgccttcctc 480
cgcctccagt tcatcggcca gatcctcgcc ctccacccct tcgagtccat ctggacccgc 540
gtctgccgct acttcaagac cgaccgcctc cgccgcgtct tctccttcgc cgtcatgtac 600
atgggccagt ccccctactc cgcccccggc acctactccc tcctccagta caccgagctc 660
accgagggca tctggtaccc ccgcggcggc ttctggcagg tccccaacac cctcctccag 720
atcgtcaagc gcaacaaccc ctccgccaag ttcaacttca acgcccccgt ctcccaggtc 780
ctcctctccc ccgccaagga ccgcgccacc ggcgtccgcc tcgagtccgg cgaggagcac 840
cacgccgacg tcgtcatcgt caacgccgac ctcgtctacg cctccgagca cctcatcccc 900
gacgacgccc gcaacaagat cggccagctc ggcgaggtca agcgctcctg gtgggccgac 960
ctcgtcggcg gcaagaagct caagggctcc tgctcctccc tctccttcta ctggtccatg 1020
gaccgcatcg tcgacggcct cggcggccac aacatcttcc tcgccgagga cttcaagggc 1080
tccttcgaca ccatcttcga ggagctcggc ctccccgccg acccctcctt ctacgtcaac 1140
gtcccctccc gcatcgaccc ctccgccgcc cccgagggca aggacgccat cgtcatcctc 1200
gtcccctgcg gccacatcga cgcctccaac ccccaggact acaacaagct cgtcgcccgc 1260
gcccgcaagt tcgtcatcca caccctctcc gccaagctcg gcctccccga cttcgagaag 1320
atgatcgtcg ccgagaaggt ccacgacgcc ccctcctggg agaaggagtt caacctcaag 1380
gacggctcca tcctcggcct cgcccacaac ttcatgcagg tcctcggctt ccgcccctcc 1440
acccgccacc ccaagtacga caagctcttc ttcgtcggcg cctccaccca ccccggcacc 1500
ggcgtcccca tcgtcctcgc cggcgccaag ctcaccgcca accaggtcct cgagtccttc 1560
gaccgctccc ccgcccccga ccccaacatg tccctctccg tcccctacgg caagcccctc 1620
aagtccaacg gcaccggcat cgactcccag gtccagctca agttcatgga cctcgagcgc 1680
tgggtctacc tcctcgtcct cctcatcggc gccgtcatcg cccgctccgt cggcgtcctc 1740
gccttc 1746
<210> 4
<211> 2019
<212> DNA
<213> 人工序列
<220>
<223> crtYB 基因
<400> 4
atgaccgccc tcgcctacta ccagatccac ctcatctaca ccctccccat cctcggcctc 60
ctcggcctcc tcacctcccc catcctcacc aagttcgaca tctacaagat ctccatcctc 120
gtcttcatcg ccttctccgc caccaccccc tgggactcct ggatcatccg caacggcgcc 180
tggacctacc cctccgccga gtccggccag ggcgtcttcg gcaccttcct cgacgtcccc 240
tacgaggagt acgccttctt cgtcatccag accgtcatca ccggcctcgt ctacgtcctc 300
gccacccgcc acctcctccc ctccctcgcc ctccccaaga cccgctcctc cgccctctcc 360
ctcgccctca aggccctcat ccccctcccc atcatctacc tcttcaccgc ccacccctcc 420
ccctcccccg accccctcgt caccgaccac tacttctaca tgcgcgccct ctccctcctc 480
atcacccccc ccaccatgct cctcgccgcc ctctccggcg agtacgcctt cgactggaag 540
tccggccgcg ccaagtccac catcgccgcc atcatgatcc ccaccgtcta cctcatctgg 600
gtcgactacg tcgccgtcgg ccaggactcc tggtccatca acgacgagaa gatcgtcggc 660
tggcgcctcg gcggcgtcct ccccatcgag gaggccatgt tcttcctcct caccaacctc 720
atgatcgtcc tcggcctctc cgcctgcgac cacacccagg ccctctacct cctccacggc 780
cgcaccatct acggcaacaa gaagatgccc tcctccttcc ccctcatcac cccccccgtc 840
ctctccctct tcttctcctc ccgcccctac tcctcccagc ccaagcgcga cctcgagctc 900
gccgtcaagc tcctcgagaa gaagtcccgc tccttcttcg tcgcctccgc cggcttcccc 960
tccgaggtcc gcgagcgcct cgtcggcctc tacgccttct gccgcgtcac cgacgacctc 1020
atcgactccc ccgaggtctc ctccaacccc cacgccacca tcgacatggt ctccgacttc 1080
ctcaccctcc tcttcggccc ccccctccac ccctcccagc ccgacaagat cctctcctcc 1140
cccctcctcc ccccctccca cccctcccgc cccaccggca tgtaccccct cccccccccc 1200
ccctccctct cccccgccga gctcgtccag ttcctcaccg agcgcgtccc cgtccagtac 1260
cacttcgcct tccgcctcct cgccaagctc cagggcctca tcccccgcta ccccctcgac 1320
gagctcctcc gcggctacac caccgacctc atcttccccc tctccaccga ggccgtccag 1380
gcccgcaaga cccccatcga gaccaccgcc gacctcctcg actacggcct ctgcgtcgcc 1440
ggctccgtcg ccgagctcct cgtctacgtc tcctgggcct ccgccccctc ccaggtcccc 1500
gccaccatcg aggagcgcga ggccgtcctc gtcgcctccc gcgagatggg caccgccctc 1560
cagctcgtca acatcgcccg cgacatcaag ggcgacgcca ccgagggccg cttctacctc 1620
cccctctcct tcttcggcct ccgcgacgag tccaagctcg ccatccccac cgactggacc 1680
gagccccgcc cccaggactt cgacaagctc ctctccctct ccccctcctc caccctcccc 1740
tcctccaacg cctccgagtc cttccgcttc gagtggaaga cctactccct ccccctcgtc 1800
gcctacgccg aggacctcgc caagcactcc tacaagggca tcgaccgcct ccccaccgag 1860
gtccaggccg gcatgcgcgc cgcctgcgcc tcctacctcc tcatcggccg cgagatcaag 1920
gtcgtctgga agggcgacgt cggcgagcgc cgcaccgtcg ccggctggcg ccgcgtccgc 1980
aaggtcctct ccgtcgtcat gtccggctgg gagggccag 2019
<210> 5
<211> 891
<212> DNA
<213> 人工序列
<220>
<223> CrChYb 基因
<400> 5
atgatgctcg cctcccgccc cgccgtcgcc ctcggcgccc gcgcccagcc ccaggtcctc 60
cgccccaccc tcgtcccccg ccccggcatg gtctccaacc tccgcctcca gcccgtcaag 120
gtcgccgacc ccatcgtcgc ctccgagacc tcccaggtca tggaggcccc ccaggagaag 180
aagctctccg agttcgagct caagcgcctc gagcgcaagc agcagcgcgc ccaggaggcc 240
gccacctaca agttctccgc catcgccgcc accgtcctcg tcctctccat cgccgtcgtc 300
gccacctact accgcttcgc ctggcacttc gccgaggacg gcgacctccc cgtcgacgag 360
atggccgcca ccctcctcct cgtcttcggc ggcatgttcg gcatggagat gtacgcccgc 420
ttcgcccaca aggtcctctg gcacgacttc gagcccggct gggccctcca caagtcccac 480
cacgagcccc gcaccggccc cttcgagctc aacgacatct acgccgtcgc caacgccctc 540
cccgccatgg ccctctgcgc ctacggcttc ttcacccccc acgtcatcgg cggcgtctgc 600
ttcggcgccg gcctcggcat caccctcttc ggcatcgcct acatgttctt ccacgacggc 660
ctcgtccacc gccgcttccc cgtcggcccc atcgccaacc tcccctacat gaagcgcatc 720
atggtcgccc accagatcca ccacaccaac aagttcggcg gcgtcccctt cggcatgttc 780
ctcggcgtcc aggagctcga ggccgtcccc ggcggcaagg aggagctcga caagctcatg 840
gccgacctcg aggcccgcga ggccgccgcc gccaaggccg ccggctcctc c 891
<210> 6
<211> 897
<212> DNA
<213> 人工序列
<220>
<223> CzChYb 基因
<400> 6
atgcagaccg tcttccagcc ctcctccgtc tggcacctcc gcaaccgcca cgtcctcggc 60
gaccgcacct gcgtcccctg ccgcacctcc ctctccacct gccgccacgc cgtccgcctc 120
gtccgcgcca acgtcgccga gacccaggcc acccccacca cctcccagat gctcgaggag 180
gtccacgacg agtcccacgc cgcctccgcc tcctcccaga tcttcgagct cgccgtcaag 240
acctccatca agcgccagca gcgcaaccgc cagcagctca cctaccaggg ctccgccatc 300
gccgcctccc tcggcgtcgg cgccctcgcc gtcgccgcca cccactacaa gttctcctac 360
cacatgccct ccgagtcccc cttcccctgg ctcgacatgg ccggcaccct cgccctcgtc 420
atcggcggcg tcttcggcat ggagatgtgg gcccgctacg cccacaaggc cctctggcac 480
gacttccagc ccggctgggc cctccacaag tcccaccacg agccccgcat cggccccttc 540
gaggccaacg acatcttcgc cgtcatcaac gccgtccccg ccttctccct ctgcctctac 600
ggcttcctca cccccaacct cgtcggctcc ctctgcttcg gcgccggcct cggcatcacc 660
ctcttcggca tcatgtacat gttcatccac gacggcctcg tccacaagcg cttccccgtc 720
ggccccatcg cccagatgcc cgccatgaag cgcgtcgcca tcgcccacaa gctccaccac 780
tccgagaagt acggcggcgt cccctggggc atgttcttcg gcccccagga gctcgaggcc 840
atcggcgccg gccccgagct cgaccgcctc tgcgccgagc tcgactccaa gtcctcc 897
<210> 7
<211> 879
<212> DNA
<213> 人工序列
<220>
<223> HpChYb 基因
<400> 7
atgctctcca agctccagtc catctccgtc aaggcccgcc gcgtcgagct cgcccgcgac 60
atcacccgcc ccaaggtctg cctccacgcc cagcgctgct ccctcgtccg cctccgcgtc 120
gccgcccccc agaccgagga ggccctcggc accgtccagg ccgccggcgc cggcgacgag 180
cactccgccg acgtcgccct ccagcagctc gaccgcgcca tcgccgagcg ccgcgcccgc 240
cgcaagcgcg agcagctctc ctaccaggcc gccgccatcg ccgcctccat cggcgtctcc 300
ggcatcgcca tcttcgccac ctacctccgc ttcgccatgc acatgaccgt cggcggcgcc 360
gtcccctggg gcgaggtcgc cggcaccctc ctcctcgtcg tcggcggcgc cctcggcatg 420
gagatgtacg cccgctacgc ccacaaggcc atctggcacg agtcccccct cggctggctc 480
ctccacaagt cccaccacac cccccgcacc ggccccttcg aggccaacga cctcttcgcc 540
atcatcaacg gcctccccgc catgctcctc tgcaccttcg gcttctggct ccccaacgtc 600
ctcggcgccg cctgcttcgg cgccggcctc ggcatcaccc tctacggcat ggcctacatg 660
ttcgtccacg acggcctcgt ccaccgccgc ttccccaccg gccccatcgc cggcctcccc 720
tacatgaagc gcctcaccgt cgcccaccag ctccaccact ccggcaagta cggcggcgcc 780
ccctggggca tgttcctcgg cccccaggag ctccagcaca tccccggcgc cgccgaggag 840
gtcgagcgcc tcgtcctcga gctcgactgg tccaagcgc 879
<210> 8
<211> 1332
<212> DNA
<213> 人工序列
<220>
<223> bkt 基因
<400> 8
atgggccccg gcatccagcc cacctccgcc cgcccctgct cccgcaccaa gcactcccgc 60
ttcgccctcc tcgccgccgc cctcaccgcc cgccgcgtca agcagttcac caagcagttc 120
cgctcccgcc gcatggccga ggacatcctc aagctctggc agcgccagta ccacctcccc 180
cgcgaggact ccgacaagcg caccctccgc gagcgcgtcc acctctaccg ccccccccgc 240
tccgacctcg gcggcatcgc cgtcgccgtc accgtcatcg ccctctgggc caccctcttc 300
gtctacggcc tctggttcgt caagctcccc tgggccctca aggtcggcga gaccgccacc 360
tcctgggcca ccatcgccgc cgtcttcttc tccctcgagt tcctctacac cggcctcttc 420
atcaccaccc acgacgccat gcacggcacc atcgccctcc gcaaccgccg cctcaacgac 480
ttcctcggcc agctcgccat ctccctctac gcctggttcg actactccgt cctccaccgc 540
aagcactggg agcaccacaa ccacaccggc gagccccgcg tcgaccccga cttccaccgc 600
ggcaacccca acctcgccgt ctggttcgcc cagttcatgg tctcctacat gaccctctcc 660
cagttcctca agatcgccgt ctggtccaac ctcctcctcc tcgccggcgc ccccctcgcc 720
aaccagctcc tcttcatgac cgccgccccc atcctctccg ccttccgcct cttctactac 780
ggcacctacg tcccccacca ccccgagaag ggccacaccg gcgccatgcc ctggcaggtc 840
tcccgcacct cctccgcctc ccgcctccag tccttcctca cctgctacca cttcgacctc 900
cactgggagc accaccgctg gccctacgcc ccctggtggg agctccccaa gtgccgccag 960
atcgcccgcg gcgccgccct cgcccccggc cccctccccg tccccgccgc cgccgccgcc 1020
accgccgcca ccgccgccgc cgccgccgcc gccaccggct cccccgcccc cgcctcccgc 1080
gccggctccg cctcctccgc ctccgccgcc gcctccggct tcggctccgg ccactccggc 1140
tccgtcgccg cccagcccct ctcctccctc cccctcctct ccgagggcgt caagggcctc 1200
gtcgagggcg ccatggagct cgtcgccggc ggctcctcct ccggcggcgg cggcgagggc 1260
ggcaagcccg gcgccggcga gcacggcctc ctccagcgcc agcgccagct cgcccccgtc 1320
ggcgtcatgg cc 1332
<210> 9
<211> 2238
<212> DNA
<213> 人工序列
<220>
<223> crtR 基因
<400> 9
atggccaccc tctccgacct cgtcatcctc ctcctcggcg ccctcctcgc cctcggcttc 60
tacaacaagg accgcctcct cggctcctcc tcctcctccg cctccaccac ctccggctcc 120
tccgccgcca ccgccaacgg ctccaagccc acctactcca acggcaacgg caacgccttc 180
aagggcgacc cccgcgactt cgtcgcccgc atgaaggacc agaagaagcg cctcgccgtc 240
ttctacggct cccagaccgg caccgccgag gagtacgcca cccgcatcgc caaggaggcc 300
aagtcccgct tcggcgtctc ctccctcgtc tgcgacatcg aggagtacga cttcgagaag 360
ctcgaccagg tccccgagga ctgcgccatc gtcttctgca tggccaccta cggcgagggc 420
gagcccaccg acaacgccgt ccagttcatc gagatgatct cccaggacga ccccgagttc 480
tccgagggct ccaccctcga cggcctcaag tacgtcgtct tcggcctcgg caacaagacc 540
tacgagcagt acaacgtcgt cggccgccag ctcgacgccc gcctcaccgc cctcggcgcc 600
acccgcgtcg gcgagcgcgg cgagggcgac gacgacaagt ccatggagga ggactacctc 660
gcctggaagg acgacatgtt cgccgccctc gccaccaccc tctccttcga ggagggcgcc 720
tccggcgaga cccccgactt cgtcgtcacc gaggtcccca accaccccat cgagaaggtc 780
ttccagggcg agctctcctc ccgcgccctc ctcggctcca agggcgtcca cgacgccaag 840
aacccctacg cctcccccgt cctcgcctgc cgcgagctct tcaccggcgg cgaccgcaac 900
tgcatccacc tcgagttcga catcaccggc tccggcatca cctaccagac cggcgaccac 960
gtcgccgtct ggccctccaa ccccgacgtc gaggtcgagc gcctcctcgc cgtcctcggc 1020
ctcacctccc ccgagaagcg ccgcatgatc atccaggtcg tctccctcga ccccaccctc 1080
gccaaggtcc ccttccccac ccccaccacc tacgacgccg tcttccgcca ctacctcgac 1140
atctccgccg tcgcctcccg ccagaccctc gccgtcctcg ccaagtacgc cccctccgag 1200
caggccgccg agttcctcac ccgcctcggc accgacaagc aggcctacca caccgaggtc 1260
gtcggcggcc acctccgcct cgccgaggtc ctccagctcg ccgccggcaa cgacatcacc 1320
gtcatgccca ccgccgagaa caccaccgtc tggaacatcc ccttcgacca cgtcgtctcc 1380
gacgtctccc gcctccagcc ccgcttctac tccatctcct cctcccccaa gctccacccc 1440
aactccatcc acgtcaccgc cgtcatcctc aagtacgagt cccaggccac cgaccgccac 1500
cccgcccgct gggtcttcgg cctcggcacc aactacctcc tcaacgtcaa gcaggccgcc 1560
aacaacgaga ccacccccat gatctccgac ggccaggacg acgtccccga gcacgtctcc 1620
gcccccaagt acaccctcga gggcccccgc ggctcctaca agcacgacga ccagctcttc 1680
aaggtcccca tccacgtccg ccgctccacc ttccgcctcc ccacctcccc caagatcccc 1740
gtcatcatga tcggccccgg caccggcgtc gcccccttcc gcggcttcat ccaggagcgc 1800
atcgccctcg cccgccgctc catcgccaag aacggccccg acgccctcgc cgactgggcc 1860
cccatctacc tcttctacgg ctcccgcgac gagcaggact tcctctacgc cgaggagtgg 1920
cccgcctacg aggccgagct ccagggcaag ttcaagatcc acgtcgcctt ctcccgctcc 1980
ggcccccgca agcccgacgg ctccaagatc tacgtccagg acctcctctg ggaccagaag 2040
gaggtcatca agtccgccat cgtcgagaag cgcgcctccg tctacatctg cggcgacggc 2100
cgcaacatgt ccaaggacgt cgagcagaag ctcgccgcca tgctcgccga gtccaagaac 2160
ggctccgccg ccgtcgaggg cgccgccgag gtcaagtccc tcaaggagcg ctcccgcctc 2220
ctcatggacg tctggtcc 2238
<210> 10
<211> 1671
<212> DNA
<213> 人工序列
<220>
<223> crtS 基因
<400> 10
atgttcatcc tcgtcctcct caccggcgcc ctcggcctcg ccgccttctc ctgggcctcc 60
atcgccttct tctccctcta cctcgccccc cgccgctcct ccctctacaa cctccagggc 120
cccaaccaca ccaactactt caccggcaac ttcctcgaca tcctctccgc ccgcaccggc 180
gaggagcacg ccaagtaccg cgagaagtac ggctccaccc tccgcttcgc cggcatcgcc 240
ggcgcccccg tcctcaactc caccgacccc aaggtcttca accacgtcat gaaggaggcc 300
tacgactacc ccaagcccgg catggccgcc cgcgtcctcc gcatcgccac cggcgacggc 360
gtcgtcaccg ccgagggcga ggcccacaag cgccaccgcc gcatcatgat cccctccctc 420
tccgcccagg ccgtcaagtc catggtcccc atcttcctcg agaagggcat ggagctcgtc 480
gacaagatga tggaggacgc cgccgagaag gacatggccg tcggcgagtc cgccggcgag 540
aagaaggcca cccgcctcga gaccgagggc gtcgacgtca aggactgggt cggccgcgcc 600
accctcgacg tcatggccct cgccggcttc gactacaagt ccgactccct ccagaacaag 660
accaacgagc tctacgtcgc cttcgtcggc ctcaccgacg gcttcgcccc caccctcgac 720
tccttcaagg ccatcatgtg ggacttcgtc ccctacttcc gcaccatgaa gcgccgccac 780
gagatccccc tcacccaggg cctcgccgtc tcccgccgcg tcggcatcga gctcatggag 840
cagaagaagc aggccgtcct cggctccgcc tccgaccagg ccgtcgacaa gaaggacgtc 900
cagggccgcg acatcctctc cctcctcgtc cgcgccaaca tcgccgccaa cctccccgag 960
tcccagaagc tctccgacga ggaggtcctc gcccagatct ccaacctcct cttcgccggc 1020
tacgagacct cctccaccgt cctcacctgg atgttccacc gcctctccga ggacaaggcc 1080
gtccaggaca agctccgcga ggagatctgc cagatcgaca ccgacatgcc caccctcgac 1140
gagctcaacg ccctccccta cctcgaggcc ttcgtcaagg agtccctccg cctcgacccc 1200
ccctccccct acgccaaccg cgagtgcctc aaggacgagg acttcatccc cctcgccgag 1260
cccgtcatcg gccgcgacgg ctccgtcatc aacgaggtcc gcatcaccaa gggcaccatg 1320
gtcatgctcc ccctcttcaa catcaaccgc tccaagttca tctacggcga ggacgccgag 1380
gagttccgcc ccgagcgctg gctcgaggac gtcaccgact ccctcaactc catcgaggcc 1440
ccctacggcc accaggcctc cttcatctcc ggcccccgcg cctgcttcgg ctggcgcttc 1500
gccgtcgccg agatgaaggc cttcctcttc gtcaccctcc gccgcgtcca gttcgagccc 1560
atcatctccc accccgagta cgagcacatc accctcatca tctcccgccc ccgcatcgtc 1620
ggccgcgaga aggagggcta ccagatgcgc ctccaggtca agcccgtcga g 1671
<210> 11
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_crtE 基因_AgeI
<400> 11
accggtatgg attacgcgaa catcct 26
<210> 12
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_crtE 基因_NcoI
<400> 12
ccatggtcac agagggatat cggcta 26
<210> 13
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_HMG1 基因_NotI
<400> 13
gcggccgcat ggaactaact gctaatga 28
<210> 14
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_HMG1 基因_XhoI
<400> 14
ctcgagtcac gatttgatgc aaatca 26
<210> 15
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_crtI 基因_AgeI
<400> 15
accggtatgg gaaaagaaca agatca 26
<210> 16
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_crtI 基因_NcoI
<400> 16
ccatggtcag aaagcaagaa caccaa 26
<210> 17
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_crtYB 基因_AgeI
<400> 17
accggtatga cggctctcgc atatta 26
<210> 18
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_crtYB 基因_NotI
<400> 18
gcggccgctt actgcccttc ccatccgc 28
<210> 19
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_crtR 基因_NcoI
<400> 19
ccatggatgg ccacactctc cgatct 26
<210> 20
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_crtR 基因_SfiI
<400> 20
ggcccaacag gccctacgac cagacgtcca tca 33
<210> 21
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_crtS 基因_AgeI
<400> 21
accggtatgt tcatcttggt cttgct 26
<210> 22
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_crtS 基因_NcoI
<400> 22
ccatggtcat tcgaccggct tgacct 26
<210> 23
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-KlPLac4
<400> 23
ccgcggggat cgactcataa aatag 25
<210> 24
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTPGK_KlPGapDH
<400> 24
ggactccagc ttttccattt gccttcgcgc ttgcctgtac ggtcgttacc atactaagct 60
ttttcgaaac gcagaatttt cg 82
<210> 25
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-KlPGapDH
<400> 25
agtatggtaa cgaccgtaca ggcaa 25
<210> 26
<211> 78
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTGap_ScPADHI
<400> 26
ggaatcccga tgtatgggtt tggttgccag aaaagaggaa gtccatattg tacactggcg 60
gaaaaaattc atttgtaa 78
<210> 27
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScPADHI
<400> 27
gtgtacaata tggacttcct cttttc 26
<210> 28
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTADHI_KlPLac4
<400> 28
gaaatttagg aattttaaac ttg 23
<210> 29
<211> 78
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTGap_ScPGK
<400> 29
ggactccagc ttttccattt gccttcgcgc ttgcctgtac ggtcgttacc atacttggcg 60
gaaaaaattc atttgtaa 78
<210> 30
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScPGK
<400> 30
actgtaattg cttttagttg tgtat 25
<210> 31
<211> 80
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTPGK_KlPADHI
<400> 31
aggtaagtat ggtaacgacc gtacaggcaa gcgcgaaggc aaatggaaaa gctggaagct 60
ttttcgaaac gcagaatttt 80
<210> 32
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> 引物-KlPADHI
<400> 32
ccagcttttc catttgcctt cgcgcttgcc 30
<210> 33
<211> 78
<212> DNA
<213> 人工序列
<220>
<223> 引物-KlTTLac4_ScPGapDH
<400> 33
ctactattaa ttatttacgt attctttgaa atggcagtat tgataatgat aaacttatac 60
aacatcgaag aagagtct 78
<210> 34
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScPGapDH
<400> 34
agtttatcat tatcaatact gccat 25
<210> 35
<211> 81
<212> DNA
<213> 人工序列
<220>
<223> 引物-ScTTGap_KlPGK
<400> 35
catatacctt tgataccata aaaacaagca aatattctta cttcaaacac acccgtggcg 60
gaaaaaattc atttgtaaac t 81
<210> 36
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-KlPGK
<400> 36
cgggtgtgtt tgaagtaaga atatt 25
<210> 37
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtE-UPL#1-F
<400> 37
cgagatgctt tccctccata 20
<210> 38
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtE-UPL#1-R
<400> 38
ttcgctagga cacgtcagac t 21
<210> 39
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtI-UPL#155-F
<400> 39
ccgatccttc cttttacgtg 20
<210> 40
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtI-UPL#155-R
<400> 40
cggcacaaga atgacgatag 20
<210> 41
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtR-UPL#41-F
<400> 41
acgtcgtctc tgacgtttcc 20
<210> 42
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtR-UPL#41-R
<400> 42
ttgggtgaag tttcggagaa 20
<210> 43
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtS-UPL#149-F
<400> 43
ggatgttcaa ggtcgggata 20
<210> 44
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtS-UPL#149-R
<400> 44
cggacagctt ttgagattca g 21
<210> 45
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtYB-UPL#34-F
<400> 45
cactgatctt atctttccct tatcg 25
<210> 46
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-crtYB-UPL#34-R
<400> 46
gtggtctcga taggcgtctt 20
<210> 47
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 引物-tHMG-UPL#119-F
<400> 47
ttctgctatg gcgggttc 18
<210> 48
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-tHMG-UPL#119-R
<400> 48
gctgtaacca aattcgaagc a 21
<210> 49
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> 引物-CrBKT-UPL#159-F
<400> 49
gctgctgcaa ctggttcac 19
<210> 50
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-CrBKT-UPL#159-R
<400> 50
gcactagcgg aactagcaga a 21
<210> 51
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-CrChYb-UPL#48-F
<400> 51
ttctttcacg atggattggt c 21
<210> 52
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> 引物-CrChYb-UPL#48-R
<400> 52
tgtatggtaa gttggcgata gg 22
<210> 53
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-CZChYb-UPL#157-F
<400> 53
cgcccacaaa ttacaccatt 20
<210> 54
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-CZChYb-UPL#157-R
<400> 54
tccgaaaaac ataccccaag 20
<210> 55
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> 引物-HpChYb#139-F
<400> 55
aacgacttgt tcgcaatcat ta 22
<210> 56
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 引物-HpChYb#139-R
<400> 56
cccaacacgt ttggcaac 18
<210> 57
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> 引物-Kan-UPL#144-F
<400> 57
agactaaact ggctgacgga at 22
<210> 58
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 引物-Kan-UPL#144-R
<400> 58
catcaggagt acggataaaa tgc 23
<210> 59
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-Actin-UPL #9-F
<400> 59
gcgtagattg gaacaacgtg 20
<210> 60
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 引物-Actin-UPL #9-R
<400> 60
agaactaccg gtattgtgtt gga 23
<210> 61
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 引物-alg9-UPL #132-F
<400> 61
caatcaatgg cccgtatcat 20
<210> 62
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 引物-alg9-UPL #132-R
<400> 62
tgtctcagaa gcacagtttg g 21
<210> 63
<211> 2292
<212> DNA
<213> 人工序列
<220>
<223> KlLac4 启动子
<400> 63
ccgcggggat cgactcataa aatagtaacc ttctaatgcg tatctattga ctaccaacca 60
ttagtgtggt tgcagaaggc ggaattttcc cttcttcgaa tttagcttgc tttttcattt 120
tttattttcc atttttcagt ttttgtttgt gtcgaattta gccagttgct tctccaagat 180
gaaaaaaacc cctgcgcagt ttctgtgctg caagatccta atcgactttt ccacccccca 240
caaaagtaaa tgttcttttg ttacattcgc gtgggtagct agctccccga atcttcaaag 300
gacttaggga ctgcactaca tcagagtgtg ttcacctggt ttgctgcctg gtttgaaaga 360
aaagagcagg gaactcgcgg gttcccggcg aataatcatg cgatagtcct ttggccttcc 420
aagtcgcatg tagagtagac aacagacagg gagggcagga aggatctttc actgagatcc 480
tgtatcttgt tgggtaagtc ggatgaaagg ggaatcgtat gagattggag aggatgcgga 540
agaggtaacg ccttttgtta acttgtttaa ttattatggg gcaggcgaga gggggaggaa 600
tgtatgtgtg tgaggcgggc gagacggagc catccaggcc aggtagaaat agagaaagcc 660
gaatgttaga caatatggca gcgtagtaga gtaggtaggt aggcaagtac tgctagcaaa 720
gaggagaagg gtaagctcac tcttcgcatt ccacaccgtt agtgtgtcag tttgaacaaa 780
aaaacaatca tcataccaat tgatggactg tggactggct tttggaacgg cttttcggac 840
tgcgattatt cgtgaggaat caaggtagga atttggtcat atttacggac aacagtgggt 900
gattcccata tcgagtagga aaacgagatc atggtatcct cagatatgtt gcggaaatct 960
gttcaccgca aagttcaggg tgctctggtg ggtttcggtt ggtctttgct ttgcttctcc 1020
cttgtcttgc atgttaataa tagcctagcc tgtgagccga aacttagggt aggcttagtg 1080
ttggaacgta catatctatc acgttgactt ggtttaacca ggcgacctgg tagccagcca 1140
tacccacaca cgttttttgt atcttcagta tagttgtgaa aagtgtagcg gaaatttgtg 1200
gtccgagcaa cagcgtcttt ttctagtagt gcggtcggtt acttggttga cattggtatt 1260
tggactttgt tgctacacca ttcactactt gaagtcgagt gtgaagggta tgatttctag 1320
tggtgaacac ctttagttac gtaatgtttt cattgctgtt ttacttgaga tttcgattga 1380
gaaaaaggta tttaatagct cgaatcaatg tgagaacaga gagaagatgt tcttccctaa 1440
ctcgaaaggt atatgaggct tgtgtttctt aggagaatta ttattctttt gttatgttgc 1500
gcttgtagtt ggaaaaggtg aagagacaaa agctggaatt gtgagcggat aacaagctca 1560
acacttgaaa tttaggaaag agcagaattt ggcaaaaaaa ataaaaaaaa aataaacaca 1620
catactcatc gagaccggtg gcgcgcccct aggggccggc cacgcgtcca tgggcggccg 1680
cttaattaag gcctgttggg ccctcgagat ttatacttag ataagtatgt acttacaggt 1740
atatttctat gagatactga tgtatacatg catgataata tttaaacggt tattagtgcc 1800
gattgtcttg tgcgataatg acgttcctat caaagcaata cacttaccac ctattacatg 1860
ggccaagaaa atattttcga acttgtttag aatattagca cagagtatat gatgttatcc 1920
gttagattat gcatgattca ttcctacaac tttttcgtag cataaggatt aattacttgg 1980
atgccaataa aaaaaaaaaa catcgagaaa atttcagcat gctcagaaac aattgcagtg 2040
tatcaaagta aaaaaaagat tttcactaca tgttcctttt gaagaaagaa aatcatggaa 2100
cattagattt acaaaaattt aaccaccgct gattaacgat tagaccgtta agcgcacaac 2160
aggttattag tacagagaaa gcattctgtg gtgttgcccc ggactttctt ttgcgacata 2220
ggtaaatcga ataccatcat actatctttt ccaatgactc cctaaagaaa gactcttctt 2280
cgatgttgta ta 2292
<210> 64
<211> 1047
<212> DNA
<213> 人工序列
<220>
<223> ScGapDH 启动子
<400> 64
agtttatcat tatcaatact gccatttcaa agaatacgta aataattaat agtagtgatt 60
ttcctaactt tatttagtca aaaaattagc cttttaattc tgctgtaacc cgtacatgcc 120
caaaataggg ggcgggttac acagaatata taacatcgta ggtgtctggg tgaacagttt 180
attcctggca tccactaaat ataatggagc ccgcttttta agctggcatc cagaaaaaaa 240
aagaatccca gcaccaaaat attgttttct tcaccaacca tcagttcata ggtccattct 300
cttagcgcaa ctacagagaa caggggcaca aacaggcaaa aaacgggcac aacctcaatg 360
gagtgatgca acctgcctgg agtaaatgat gacacaaggc aattgaccca cgcatgtatc 420
tatctcattt tcttacacct tctattacct tctgctctct ctgatttgga aaaagctgaa 480
aaaaaaggtt gaaaccagtt ccctgaaatt attcccctac ttgactaata agtatataaa 540
gacggtaggt attgattgta attctgtaaa tctatttctt aaacttctta aattctactt 600
ttatagttag tctttttttt agttttaaaa caccaagaac ttagtttcga ataaacacac 660
ataaacaaac aaaaaaaccg gtggcgcgcc cctaggggcc ggccacgcgt ccatgggcgg 720
ccgcttaatt aaggcctgtt gggccctcga ggtgaattta ctttaaatct tgcatttaaa 780
taaattttct ttttatagct ttatgactta gtttcaattt atatactatt ttaatgacat 840
tttcgattca ttgattgaaa gctttgtgtt ttttcttgat gcgctattgc attgttcttg 900
tctttttcgc cacatgtaat atctgtagta gatacctgat acattgtgga tgctgagtga 960
aattttagtt aataatggag gcgctcttaa taattttggg gatattggct ttttttttta 1020
aagtttacaa atgaattttt tccgcca 1047
<210> 65
<211> 1239
<212> DNA
<213> 人工序列
<220>
<223> ScPGK 启动子
<400> 65
actgtaattg cttttagttg tgtattttta gtgtgcaagt ttctgtaaat cgattaattt 60
ttttttcttt cctcttttta ttaaccttaa tttttatttt agattcctga cttcaactca 120
agacgcacag atattataac atctgcataa taggcatttg caagaattac tcgtgagtaa 180
ggaaagagtg aggaactatc gcatacctgc atttaaagat gccgatttgg gcgcgaatcc 240
tttattttgg cttcaccctc atactattat cagggccaga aaaaggaagt gtttccctcc 300
ttcttgaatt gatgttaccc tcataaagca cgtggcctct tatcgagaaa gaaattaccg 360
tcgctcgtga tttgtttgca aaaagaacaa aactgaaaaa acccagacac gctcgacttc 420
ctgtcttcct attgattgca gcttccaatt tcgtcacaca acaaggtcct agcgacggct 480
cacaggtttt gtaacaagca atcgaaggtt ctggaatggc gggaaagggt ttagtaccac 540
atgctatgat gcccactgtg atctccagag caaagttcgt tcgatcgtac tgttactctc 600
tctctttcaa acagaattgt ccgaatcgtg tgacaacaac agcctgttct cacacactct 660
tttcttctaa ccaagggggt ggtttagttt agtagaacct cgtgaaactt acatttacat 720
atatataaac ttgcataaat tggtcaatgc aagaaataca tatttggtct tttctaattc 780
gtagtttttc aagttcttag atgctttctt tttctctttt ttacagatca tcaaggaagt 840
aattatctac tttttacaac aaatataaaa caaaaaaaac cggtggcgcg cccctagggg 900
ccggccacgc gtccatgggc ggccgcttaa ttaaggcctg ttgggccctc gagattgaat 960
tgaattgaaa tcgatagatc aatttttttc ttttctcttt ccccatcctt tacgctaaaa 1020
taatagttta ttttattttt tgaatatttt ttatttatat acgtatatat agactattat 1080
ttacttttaa tagattatta agatttttat taaaaaaaaa ttcgtccctc tttttaatgc 1140
cttttatgca gttttttttt cccattcgat atttctatgt tcgggtttca gcgtatttta 1200
agtttaataa ctcgaaaatt ctgcgtttcg aaaaagctt 1239
<210> 66
<211> 1090
<212> DNA
<213> 人工序列
<220>
<223> KlGapDH 启动子
<400> 66
agtatggtaa cgaccgtaca ggcaagcgcg aaggcaaatg gaaaagctgg agtccggaag 60
ataatcattt catcttcttt tgttagaaca gaacagtgga tgtccctcat ctcggtaacg 120
tattgtccat gccctagaac tctctgtccc taaaaagagg acaaaaaccc aatggtttcc 180
ccagcttcca gtggagccac cgatcccact ggaaaccact ggacaggaag agaaaatcac 240
ggacttcctc tattgaagga taattcaaca ctttcaccag atcccaaatg tcccgcccct 300
attcccgtgt tccatcacgt accataactt accatttcat cacgttctct atggcacact 360
ggtactgctt cgactgcttt gcttcatctt ctctatgggc caatgagcta atgagcacaa 420
tgtgctgcga aataaaggga tatctaattt atattattac attataatat gtactagtgt 480
ggttattggt aattgtactt aattttgata tataaagggt ggatcttttt cattttgaat 540
cagaattgga attgcaactt gtctcttgtc actattactt aatagtaatt atatttctta 600
ttaacctttt ttttaagtca aaacaccaag gacaagaact actcttcaaa ggtatttcaa 660
gttatcatac gtctcacaca cgcttcacag tttcaagtaa aaaaaaagaa tattacacaa 720
ccggtggcgc gcccctaggg gccggccacg cgtccatggg cggccgctta attaaggcct 780
gttgggccct cgaggtgaat ttactttaaa tcttgcattt aaataaattt tctttttata 840
gctttatgac ttagtttcaa tttatatact attttaatga cattttcgat tcattgattg 900
aaagctttgt gttttttctt gatgcgctat tgcattgttc ttgtcttttt cgccacatgt 960
aatatctgta gtagatacct gatacattgt ggatgctgag tgaaatttta gttaataatg 1020
gaggcgctct taataatttt ggggatattg gctttttttt ttaaagttta caaatgaatt 1080
ttttccgcca 1090
<210> 67
<211> 1236
<212> DNA
<213> 人工序列
<220>
<223> KlPGK 启动子
<400> 67
cgggtgtgtt tgaagtaaga atatttgctt gtttttatgg tatcaaaggt atatgttgta 60
gaagacaatt tccggtaatc caattgtctg tctgctcagt ttagcacatg tatagtacgt 120
tgcacatagt ctacaatatt cagcattcag cattcagtat acagcatatg gctaaatgat 180
cacaaatgtg attgatgatt tgacacgact agaaaagaga acgaaaaagg gaaattccat 240
gtcacgtgcg ttggcacgtg acatggaata tcgaagaaag aaaaaaaaaa cgatctcgtc 300
ctagtggaag cccagagtct ggtccccccg gagtcttccc aaaacaagaa gctgacacat 360
gttgacacag aacaccccac agcaaatgca ccacgctacg tagatcagga agcttaactc 420
tagcgacctg tcgctcgccc cacagaacct cacccgagaa ccacacatta cacgccgcca 480
gctcccacta tactcatctt gcttccctta agcgttctca cgattcgttc gctgcccttc 540
ttcaagagtc ttctgattct aattctcatt cgaaatcctc tacagttaat gaattgcttg 600
acatgacatt cattgtctca tggttttggc tttttggctt ttgtctttta aagctatatc 660
aactttacat ataaatatac gtcaaaaggg gattcattaa ttagaaaatt ctctttttca 720
atagttgcta ttcattatca atctattcaa ctcaattggt tattattttc atctttttgt 780
catcctaaac catcaacaat atttaaatat atctgttgct acattaagag ttacttcaga 840
aataacaaaa aaatcgatca agaattaata aaaaaaccgg tggcgcgccc ctaggggccg 900
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag attgaattga 960
attgaaatcg atagatcaat ttttttcttt tctctttccc catcctttac gctaaaataa 1020
tagtttattt tattttttga atatttttta tttatatacg tatatataga ctattattta 1080
cttttaatag attattaaga tttttattaa aaaaaaattc gtccctcttt ttaatgcctt 1140
ttatgcagtt tttttttccc attcgatatt tctatgttcg ggtttcagcg tattttaagt 1200
ttaataactc gaaaattctg cgtttcgaaa aagctt 1236
<210> 68
<211> 1246
<212> DNA
<213> 人工序列
<220>
<223> KlADHI 启动子
<400> 68
ccagcttttc catttgcctt cgcgcttgcc tgtacggtcg ttaccatact tacctttctt 60
gcttcttctc aaaatggaat ccaggttttt agcttcgtgt ttcttttttt tttttaccat 120
ttttcaaatt tcagtcttcc attttcagct tcttgttttt tttttttttt ttttttttca 180
tttcagtttt tacagcttcc agtctccctc tttccttcga tttccatctt cttgtttctg 240
tagccatctt cctatcacgt gcaagggaag aaagtggggg cccagcacct tcttttttgt 300
tctttggtgg gggctcgttt tagtttttac gtgcgtaatt gggaatcttc cgaggtagta 360
tgacatgtcc ggtggtgacc tgatactttc tgtttctccg agtaggacag aagaggaaaa 420
aaaaatagcg tgtgatgttc ttctattcta gtagtgtatt gatctattca caatcagatc 480
acaatcatat gagcagatga tgtattttgg gttgcttttc accaacccaa gtattcgatt 540
gatctttata tactgcggtt atttctaggt cttaaacggt taacacctgt tgcagggtgg 600
tatgtatttt tctcaaagtg tgctattttc acaccagcta gaaatcagct gtcttacttg 660
tatacaatta gaccagccat ttggtcttct ggaatatgta tataaacacc cggtcgattc 720
tgacaatcca tccacttttg tagtaggtct ctctatatcc atttgtacaa tgttgtttct 780
gttttgccct acatcatcat caagcaaaaa caatagtttc aattgaaaca taaacaagct 840
ttaaacacac aaactctata ctaaaaaaag ataaaaccgg tggcgcgccc ctaggggccg 900
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag gtgaatttac 960
tttaaatctt gcatttaaat aaattttctt tttatagctt tatgacttag tttcaattta 1020
tatactattt taatgacatt ttcgattcat tgattgaaag ctttgtgttt tttcttgatg 1080
cgctattgca ttgttcttgt ctttttcgcc acatgtaata tctgtagtag atacctgata 1140
cattgtggat gctgagtgaa attttagtta ataatggagg cgctcttaat aattttgggg 1200
atattggctt ttttttttaa agtttacaaa tgaatttttt ccgcca 1246
<210> 69
<211> 2068
<212> DNA
<213> 人工序列
<220>
<223> ScADHI 启动子
<400> 69
gtgtacaata tggacttcct cttttctggc aaccaaaccc atacatcggg attcctataa 60
taccttcgtt ggtctcccta acatgtaggt ggcggagggg agatatacaa tagaacagat 120
accagacaag acataatggg ctaaacaaga ctacaccaat tacactgcct cattgatggt 180
ggtacataac gaactaatac tgtagcccta gacttgatag ccatcatcat atcgaagttt 240
cactaccctt tttccatttg ccatctattg aagtaataat aggcgcatgc aacttctttt 300
cttttttttt cttttctctc tcccccgttg ttgtctcacc atatccgcaa tgacaaaaaa 360
atgatggaag acactaaagg aaaaaattaa cgacaaagac agcaccaaca gatgtcgttg 420
ttccagagct gatgaggggt atctcgaagc acacgaaact ttttccttcc ttcattcacg 480
cacactactc tctaatgagc aacggtatac ggccttcctt ccagttactt gaatttgaaa 540
taaaaaaaag tttgctgtct tgctatcaag tataaataga cctgcaatta ttaatctttt 600
gtttcctcgt cattgttctc gttccctttc ttccttgttt ctttttctgc acaatatttc 660
aagctatacc aagcatacaa tcaagcaatt ccagatctaa aaaaaccggt ggcgcgcccc 720
taggggccgg ccacgcgtcc atgggcggcc gcttaattaa ggcctgttgg gccctcgagc 780
ccgggggggg ctcgatcccc tcgcgagttg gttcagctgc tgcctgaggc tggacgacct 840
cgcggagttc taccggcagt gcaaatccgt cggcatccag gaaaccagca gcggctatcc 900
gcgcatccat gcccccgaac tgcaggagtg gggaggcacg atggccgctt tggtcgatct 960
agattacgtg gaagaaaggt agtaaaagta gtagtataag tagtaaaaag aggtaaaaag 1020
agaaaaccgg ctacatacta gagaagcacg tacacaaaaa ctcataggca cttcatcata 1080
cgacagtttc ttgatgcatt ataatagtgt attagatatt ttcagaaata tgcatagaac 1140
ctcctcttgc ctttactttt tatacataga acattggcag atttacttac actactttgt 1200
ttctacgcca tttcttttgt tttcaacact tagacaagtt gttgagaacc ggactactaa 1260
aaagcaatgt tcccactgaa aatcatgtac ctgcagcata ataaccccct aattctgcat 1320
cgatccagta tgtttttttt tctctactca tttttacctg aagatagagc ttctaaaaca 1380
aaaaaaatca gtgattacat gcatattgtg tgttctagta accaaaggaa aggaacagat 1440
agataaaatt ccgagactgt caaattaggt ttttttcttt ttttttggcg ggagtcagtg 1500
ggccgaaata tgttcttggc ctagaactta atctggtttg atcatgccaa tacttgcctg 1560
agtgcccgac tttttgccca ccctcttgcc ttctgtcatc cttcaaaacc cacctgtttt 1620
ccagccgtat cttcgctcgc atctacacat actgtgccat atcttgtgtg tagccggacg 1680
tgactatgac caaaaacaaa caaggagaac tgttcgccga tttgtaacac tcctgcatcc 1740
atccaagtgg gtatgcgcta tgcaatgtta agctaggtca ggtcagacca ggtccaagga 1800
cagcaacttg actgtatgca acctttacca tctttgcaca gaacatactt gtagctagct 1860
agttacactt atggaccgaa aaggcacccc accatgtctg tccggcttta gagtacggcc 1920
gcagaccgct gatttgcctt gccaagcagt agtcacaatg catcgcatga gcacacgggc 1980
acgggcacgg gcacaggaac cattggcaaa aataccagat acactatacc gacgtatatc 2040
aagcccaagt ttaaaattcc taaatttc 2068
<210> 70
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> KlPLac4-3’_SalI-F
<400> 70
taggtcgacc cgcggggatc gactcata 28
<210> 71
<211> 92
<212> DNA
<213> 人工序列
<220>
<223> KlPLac4-3’-R
<400> 71
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt ctcgatgagt 60
atgtgtgttt attttttttt tatttttttt gc 92
<210> 72
<211> 93
<212> DNA
<213> 人工序列
<220>
<223> KlTTLac4-F
<400> 72
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag atttatactt 60
agataagtat gtacttacag gtatatttct atg 93
<210> 73
<211> 46
<212> DNA
<213> 人工序列
<220>
<223> KlTTLac4_EcoRI-R
<400> 73
taggaattcc tactattaat tatttacgta ttctttgaaa tggcag 46
<210> 74
<211> 46
<212> DNA
<213> 人工序列
<220>
<223> ScPGapDH_SalI-F
<400> 74
taggtcgaca gtttatcatt atcaatactg ccatttcaaa gaatac 46
<210> 75
<211> 90
<212> DNA
<213> 人工序列
<220>
<223> ScPGapDH-R
<400> 75
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt ttttttgttt 60
gtttatgtgt gtttattcga aactaagttc 90
<210> 76
<211> 104
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap-F
<400> 76
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag gtgaatttac 60
tttaaatctt gcatttaaat aaattttctt tttatagctt tatg 104
<210> 77
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap_EcoRI-R
<400> 77
taggaattcg gactccagct tttccatttg 30
<210> 78
<211> 35
<212> DNA
<213> 人工序列
<220>
<223> ScPADHI_SalI-F
<400> 78
taggtcgacg tgtacaatat ggacttcctc ttttc 35
<210> 79
<211> 82
<212> DNA
<213> 人工序列
<220>
<223> ScPADHI -R
<400> 79
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt ttttttagat 60
ctggaattgc ttgattgtat gc 82
<210> 80
<211> 75
<212> DNA
<213> 人工序列
<220>
<223> ScTTADHI_KlPLac4 -5'端-F
<400> 80
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag cccggggggg 60
gctcgatccc ctcgc 75
<210> 81
<211> 44
<212> DNA
<213> 人工序列
<220>
<223> ScTTADHI_KlPLac4-5'端_EcoRI-R
<400> 81
taggaattcg aaatttagga attttaaact tgggcttgat atac 44
<210> 82
<211> 44
<212> DNA
<213> 人工序列
<220>
<223> ScPGK_SalI-F
<400> 82
taggtcgaca ctgtaattgc ttttagttgt gtatttttag tgtg 44
<210> 83
<211> 100
<212> DNA
<213> 人工序列
<220>
<223> ScPGK-R
<400> 83
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt tttttttgtt 60
ttatatttgt tgtaaaaagt agataattac ttccttgatg 100
<210> 84
<211> 94
<212> DNA
<213> 人工序列
<220>
<223> ScTTPGK-F
<400> 84
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag attgaattga 60
attgaaatcg atagatcaat ttttttcttt tctc 94
<210> 85
<211> 46
<212> DNA
<213> 人工序列
<220>
<223> ScTTPGK_EcoRI-R
<400> 85
taggaattcc atataccttt gataccataa aaacaagcaa atattc 46
<210> 86
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> KlPGapDH_SalI-F
<400> 86
taggtcgaca gtatggtaac gaccgtacag 30
<210> 87
<211> 88
<212> DNA
<213> 人工序列
<220>
<223> KlPGapDH-R
<400> 87
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt tgtgtaatat 60
tctttttttt tacttgaaac tgtgaagc 88
<210> 88
<211> 104
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap-F
<400> 88
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag gtgaatttac 60
tttaaatctt gcatttaaat aaattttctt tttatagctt tatg 104
<210> 89
<211> 49
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap_EcoRI-R
<400> 89
taggaattct ggcggaaaaa attcatttgt aaactttaaa aaaaaaagc 49
<210> 90
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> KlPGK_SalI-F
<400> 90
taggtcgacc gggtgtgttt gaagtaagaa tatttg 36
<210> 91
<211> 98
<212> DNA
<213> 人工序列
<220>
<223> KlPGK -R
<400> 91
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt ttttttatta 60
attcttgatc gatttttttg ttatttctga agtaactc 98
<210> 92
<211> 94
<212> DNA
<213> 人工序列
<220>
<223> ScTTPGK -F
<400> 92
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag attgaattga 60
attgaaatcg atagatcaat ttttttcttt tctc 94
<210> 93
<211> 36
<212> DNA
<213> 人工序列
<220>
<223> ScTTPGK_EcoRI-R
<400> 93
taggaattca agctttttcg aaacgcagaa ttttcg 36
<210> 94
<211> 30
<212> DNA
<213> 人工序列
<220>
<223> KlPADHI_SalI-F
<400> 94
taggtcgacc cagcttttcc atttgccttc 30
<210> 95
<211> 91
<212> DNA
<213> 人工序列
<220>
<223> KlPADHI -R
<400> 95
aagcggccgc ccatggacgc gtggccggcc cctaggggcg cgccaccggt tttatctttt 60
tttagtatag agtttgtgtg tttaaagctt g 91
<210> 96
<211> 104
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap-F
<400> 96
gccacgcgtc catgggcggc cgcttaatta aggcctgttg ggccctcgag gtgaatttac 60
tttaaatctt gcatttaaat aaattttctt tttatagctt tatg 104
<210> 97
<211> 28
<212> DNA
<213> 人工序列
<220>
<223> ScTTGap_EcoRI-R
<400> 97
taggaattcg gaatcccgat gtatgggt 28
<210> 98
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 正向引物_kan 基因_AgeI
<400> 98
accggtatgg gtaaggaaaa gactca 26
<210> 99
<211> 26
<212> DNA
<213> 人工序列
<220>
<223> 反向引物_kan 基因_NcoI
<400> 99
ccatggttag aaaaactcat cgagca 26
- 还没有人留言评论。精彩留言会获得点赞!