一种水稻粒型基因DSS及其编码蛋白质和应用的制作方法
本发明属于基因工程领域,具体涉及一种控制水稻粒型的基因DSS,以及其编码蛋白质和应用。
背景技术:
水稻是重要的粮食作物,它提供了世界人口约21%的能量摄入需求。近年来,水稻单产的增加遇到了瓶颈,如何在水稻种植面积基本不变或逐年下降的情况下来提高水稻的总产量,保障粮食安全,是当前面临的一个重要挑战。水稻的产量由有效穗数、每穗粒数及粒重等因素构成,而籽粒大小是水稻粒重的直接决定因素。籽粒大小不仅影响水稻产量,也是一个重要的品质性状。以水稻为食的人群数量众多且分布广泛,人们会根据自己的喜好及风俗习惯来选择食用稻米的类型。比如,美国、中国南方及大多数亚洲国家的人喜好籽粒细长的水稻品种,而韩国、日本和中国北方等地的居民则更喜欢籽粒短而圆的水稻品种。因此阐明籽粒大小的调控机制并在育种中利用有益基因是提高水稻产量和改善水稻品质的一个重要策略。
水稻的粒型性状包括粒长、粒宽、粒厚及它们之间的相互比例。现在一般认为粒长、粒宽及粒厚的遗传都是由多基因控制。粒型相关基因通过调控细胞分裂或伸长,影响颖壳的大小及籽粒的灌浆等过程来决定种子的大小及形状,最终影响作物的产量。大多数水稻粒型基因是通过构建遗传群体检测粒型QTLs,再通过回交群体进行精细定位而发现的,如GS3,GW2,GS5,GW6a等。另外一些参与调控激素含量和信号转导的基因,也参与到水稻粒型的调控,如D1,D2,BRD2,ARF2,GN1a等。
虽然现阶段已有不少粒型相关基因的报道,但真正用到生产实际中的并不多,究其原因主要是水稻粒型是一个非常复杂的性状,受多基因的调控,而现阶段对于其研究主要还是集中在单个基因的克隆,对它们复杂的调控网络还知之甚少。因此对于水稻粒型的研究一方面需要我们研究已克隆基因之间的相互作用及调控网络,另一方面则需要我们克隆更多的粒型基因,以便更加全面地揭示粒型调控的分子机制。
技术实现要素:
本发明的目的在于公开一种水稻粒型相关基因DSS的核苷酸序列。其核苷酸序列如SEQ ID NO.1所示,含7550bp。
本发明的第二个目的还提供所述水稻粒型相关基因DSS编码的蛋白序列,其氨基酸序列如SEQ ID NO.3所示,含有473氨基酸。
所述蛋白质的编码基因优选为如下1)或2)或3)所述的DNA分子:
1)SEQ ID NO.1所示的DNA分子;
2)SEQ ID NO.2所示的DNA分子;
3)在严格条件下与1)或2)限定的DNA序列杂交且编码所述蛋白的DNA分子;
4)与1)或2)或3)限定的DNA序列具有90%以上同源性,且编码植物粒型相关蛋白的DNA分子。
含有以上任一所述基因的重组表达载体也属于本发明的保护范围。
可用现有的植物表达载体构建含有所述基因的重组表达载体。
所述植物表达载体包括双元农杆菌载体和可用于植物微弹轰击的载体等。所述植物表达载体还可包含外源基因的3’端非翻译区域,即包含聚腺苷酸信号和任何其它参与mRNA加工或基因表达的DNA片段。所述聚腺苷酸信号可引导聚腺苷酸加入到mRNA前体的3’端,如农杆菌冠瘿瘤诱导(Ti)质粒基因(如胭脂合成酶Nos基因)、植物基因(如大豆贮存蛋白基因)3’端转录的非翻译区均具有类似功能。
使用所述基因构建重组植物表达载体时,在其转录起始核苷酸前可加上任何一种增强型启动子或组成型启动子,如花椰菜花叶病毒(CAMV)35S启动子、玉米的泛素启动子(Ubiquitin),它们可单独使用或与其它的植物启动子结合使用;此外,使用本发明的基因构建植物表达载体时,还可使用增强子,包括翻译增强子或转录增强子,这些增强子区域可以是ATG起始密码子或邻接区域起始密码子等,但必需与编码序列的阅读框相同,以保证整个序列的正确翻译。所述翻译控制信号和起始密码子的来源是广泛的,可以是天然的,也可以是合成的。翻译起始区域可以来自转录起始区域或结构基因。
为了便于对转基因植物细胞或植物进行鉴定及筛选,可对所用植物表达载体进行加工,如加入可在植物中表达的编码可产生颜色变化的酶或发光化合物的基因(GUS基因、萤光素酶基因等)、具有抗性的抗生素标记物(庆大霉素标记物、卡那霉素标记物等)或是抗化学试剂标记基因(如抗除莠剂基因)等。从转基因植物的安全性考虑,可不加任何选择性标记基因,直接以逆境筛选转化植株。
所述重组表达载体可以为重组过表达载体或重组干扰载体.
重组过表达载体可为在用限制性内切酶KpnI和SpeI双酶切载体pCAMBIA1390的重组位点插入所述基因(DSS)得到的重组质粒。将含有DSS的pCAMBIA1390命名为pCAMBIA1390-DSS。
重组干扰载体可为在LH-FAD2-1390RNAi载体的Kpn I和Sac I重组位点以及Mlu I和BamH I重组位点分别插入所述基因(DSS)的部分片段得到的重组质粒。将含有DSS的LH-FAD2-1390RNAi命名为LH-FAD2-1390RNAi-DSS。
含有以上任一所述基因(DSS)的表达盒及重组菌均属于本发明的保护范围。
扩增所述基因(DSS)全长或任一片段的引物对也属于本发明的保护范围,所述的引物对优选Primer1/Primer2、Primer3/Primer4、Primer5/Primer6和Primer7/Primer8;其中Primer1序列如SEQ ID NO.4所示,Primer2序列如SEQ ID NO.5所示,Primer3序列如SEQ ID NO.6所示,Primer4序列如SEQ ID NO.7所示,Primer5序列如SEQ ID NO.8所示,Primer6序列如SEQ ID NO.9所示,Primer7序列如SEQ ID NO.10所示,Primer8序列如SEQ ID NO.11所示。
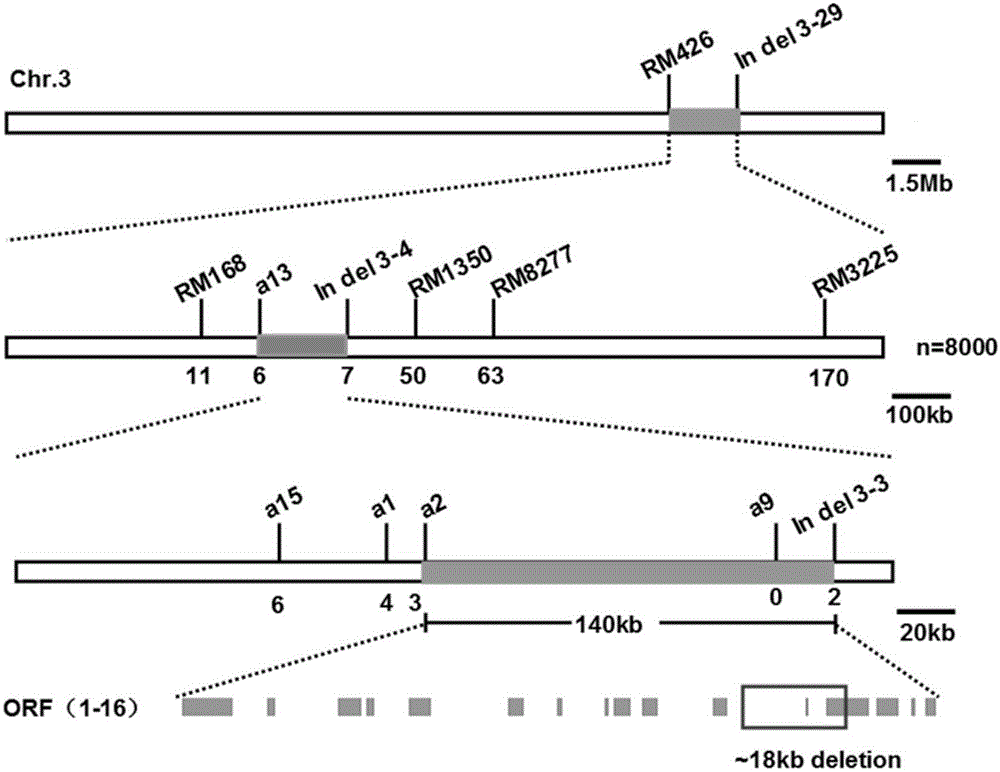
在图位克隆此基因过程中涉及到的定位引物(见表1),除引物Indel3-29、RM426、RM168、RM1350、RM8277和RM3225外,其余引物为本实验需要而自行设计的引物,这些自行设计的引物也属于本发明的保护范围。
有益效果:
本发明的水稻粒型相关基因DSS可影响水稻籽粒的大小。在突变体背景下,过表达该基因可导致水稻粒型变大。在野生型背景下,抑制该位点基因的表达可导致水稻粒型一定程度的变小。所述基因以及突变体可以应用于水稻粒型调控的理论研究和遗传改良,从而使水稻的产量和品质得到进一步改善。
附图说明
图1为野生型WT(Nanjing35)和突变体dss表型分析。
A野生型WT和突变体dss的稻谷对比图;
B野生型WT和突变体dss的糙米对比图;
C野生型WT和突变体dss的平均粒长;
D野生型WT和突变体dss的平均粒宽;
E野生型WT和突变体dss的平均千粒重;
F野生型WT和突变体dss的平均单株产量;
G野生型WT和突变体dss抽穗时期的株型图;
H野生型WT和突变体dss主茎各节间和穗对比图;
I野生型WT和突变体dss的主茎各节间和穗长度统计。
图2为DSS的精细定位。
图3为过表达载体pCAMBIA1390质粒图谱。
图4为李辉改造的干扰载体LH-FAD2-1390RNAi质粒图谱。
图5为转基因过表达植株的粒型观察。
A 对照dss和过表达植株抽穗时期的株型图;
B对照dss和过表达植株中DSS基因的相对表达量;
C野生型WT、突变体dss和过表达株系粒型以及颖壳横截面;
D野生型WT、突变体dss和过表达株系外稃横截面外围厚壁细胞数目。
图6为转基因干扰植株的粒型观察。
A 对照WT和转基因干扰植株抽穗后的株型图;
B对照WT和转基因干扰植株中DSS基因的相对表达量;
C野生型WT、突变体dss和转基因干扰植株粒型以及颖壳横截面;
D野生型WT、突变体dss和转基因干扰植株外稃横截面外围厚壁细胞数目。
具体实施方式
以下的实施例便于更好地理解本发明,但并不限定本发明。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的试验材料,如无特殊说明,均为自常规生化试剂商店购买得到的。
实施例1、编码水稻粒型基因的发现
一、水稻粒型突变体的获得
水稻粒型突变体dss(decreased seed size)是粳稻品种Nanjing 35通过Co60辐射诱变后筛选得到。经过多年,多点种植,dss的表型稳定。调查粒型的方法:抽穗后30天,取主穗上部1/4种子,利用游标卡尺对没粒种子的粒长和粒宽进行测量,野生型和突变体各10重复。调查千粒重方法:野生型和突变体各取1000粒种子,称量重量,各重复5次。调查单株产量方法:抽穗后30天,将野生型和突变体每株所有籽粒收获,进行称重,各重复10次。由图1所示,发现dss的粒长、粒宽和千粒重型较野生型显著变小,单株产量显著降低。另外突变体dss的株高较野生型显著降低,各个节间均有不同程度变短。突变体dss的分蘖数显著增加。
二、水稻粒型相关基因的获得
以籼稻品种9311为母本,突变体dss为父本杂交获得F1,之后自交后的F2分离群体(8000株)。在F2群体中挑选表型和突变体dss极端相似单株,利用其叶片提取DNA。利用覆盖水稻基因组的SSR和InDel标记进行连锁分析,初步发现控制水稻粒型的基因存在于标记RM426和Indel3-29之间。之后在RM426和Indel3-29之间,自行设计SSR和InDel标记并结合单株的表型进一步缩小定位区间,最终将定位区间缩小在a2和Indel3-3之间,并且a9是共分离标记。依据日本晴的序列预测,该区段的物理距离大概为140kb,通过测序发现该区段缺少18kb(图2)
上述SSR标记分析的方法如下所述:
(1)提取上述选取单株的总DNA作为模板,具体方法如下:
①取0.2克左右的水稻幼嫩叶片,置于2.0ml Eppendorf管中,管中放置一粒钢珠,把装好样品的Eppendorf管在液氮中冷冻5min,置于2000型GENO/GRINDER仪器上粉碎样品1min。
②加入660μl提取液(含100mM Tris-Hcl(PH 8.0),20mM EDTA(PH 8.0),1.4M NaCl,0.2g/ml CTAB的溶液),漩涡器上剧烈涡旋混匀,冰浴30min。
③加入40μl 20%SDS,65℃温浴10min,每隔两分钟轻轻上下颠倒混匀。
④加入100μl 5M NaCl,温和混匀。
⑤加入100μl 10×CTAB,65℃温浴10min,间断轻轻上下颠倒混匀。
⑥加入900μl氯仿,充分混匀,12000rpm离心3min。
⑦转移上清液至1.5mL Eppendorf管中,加入600μl异丙醇,混匀,12000rpm离心5min。
⑧弃上清液,沉淀用70%(体积百分含量)乙醇漂洗一次,室温凉干。
⑨加入100μl 1×TE(121克Tris溶于1升水中,用盐酸调PH值至8.0得到的溶液)溶解DNA。
⑩取2μl电泳检测DNA质量,并用DU800分光光度仪测定浓度(Beckman Instrument Inc.U.S.A)。
(2)将上述提取的DNA稀释成约20ng/μl,作为模板进行PCR扩增;
PCR反应体系(10μl):DNA(20ng/ul)1ul,上游引物(2pmol/ul)1ul,下游引物(2pmol/ul)1ul,10xBuffer(MgCl2free)1ul,dNTP(10mM)0.2ul,MgCl2(25mM)0.6ul,rTaq(5u/ul)0.1ul,ddH2O5.1ul,共10ul。
PCR反应程序:94.0℃变性5min;94.0℃变性30s、55℃退火30s、72℃延伸1min,共循环35次;72℃延伸7min;10℃保存。PCR反应在MJ Research PTC-225热循环仪中进行。
上述引物开发过程如下:
(1)SSR标记开发
将公共图谱的SSR标记与水稻基因组序列进行整合,下载突变位点附近的BAC/PAC克隆序列。用SSRHunter(李强等,遗传,2005,27(5):808-810)或SSRIT软件搜索克隆中潜在的SSR序列(重复次数≥6);将这些SSR及其邻近400~500bp的序列在NCBI通过BLAST程序在线与相应的籼稻序列进行比较,如果两者的SSR重复次数有差异,初步推断该SSR引物的PCR产物在籼、粳间存在多态性;再利用Primer Premier 5.0软件设计SSR引物,并由上海英骏生物技术有限公司合成。将自行设计的SSR成对引物等比例混合,检测其在9311和Nanjing35之间的多态性,表现多态者用作精细定位DSS的分子标记。用于定位的分子a1、a2、a13、a15和a19标记见表1。
SSR标记的PCR产物检测:
扩增产物用8%非变性聚丙烯酰胺凝胶电泳分析。以50bp的DNA Ladder为对照比较扩增产物的分子量大小,银染显色。
(2)InDel标记开发
InDel引物设计:对9311和Nanjing35在DSS所在位置附近的部分区段进行测序,并进行比对,发现两者之间存在的SNPs,以这些SNPs为基础用软件设计InDel标记,同时运用Primer Premier 5.0软件设计对应的另一条引物,用于定位的引物Indel3-3和Indel3-4见表1。
InDel标记分析的PCR反应体系:DNA(20ng/ul)2ul,Primer1(10pmol/ul)2ul,Primer2(10pmol/ul)2ul,10xBuffer(MgCl2free)2ul,dNTP(10mM)0.4ul,MgCl2(25mM)1.2ul,rTaq(5u/ul)0.4ul,ddH2O 10ul,总体积20ul。
扩增反应在PTC-200(MJ Research Inc.)PCR仪上进行:94℃3min;94℃30sec,55℃(引物不同,有所调整)45sec,72℃2.5min,35个循环;72℃5min。
PCR产物纯化回收,按试剂盒(北京Tiangen公司)步骤进行。PCR产物酶切消化过夜后,用1-4%的琼脂糖凝胶中电泳分离,经EB染色后于紫外灯下观察拍照。dCAPS用8%的非变性PAGE胶分离,银染。
表1用于基因定位的分子标记
(3)粒型基因的获得
根据定位的位点设计引物,序列如下所述:
primer1:
5'—CGGGAGCGGAAGAGATTA—3'(SEQ ID NO.4)
primer2:
5'—TCGGTAAACCTTTCTGAACTT—3'(SEQ ID NO.5)
以primer1和primer2为引物,以Nanjing35的cDNA为模板,进行PCR扩增获得目的基因。该对引物的扩增产物包含了该基因的全部编码区。
扩增反应用KOD酶扩增(购自TOYOBO公司),在PTC-200(MJ Research Inc.)PCR仪上进行:94℃2min;98℃10sec,60℃30sec,68℃5min,35个循环;68℃20min。将PCR产物回收纯化后连接到载体pMb18T载体上(购自TAKARA公司),转化大肠杆菌DH5α感受态细胞(购自Tiangen公司),挑选阳性克隆,进行测序。
序列测定结果表明,PCR反应获得的片段包含SEQ ID NO.2所示的核苷酸序列,编码473个氨基酸残基组成的蛋白质(见SEQ ID NO.3),将SEQ ID NO.3所示的蛋白命名为DSS。
实施例2、转基因植物的获得和鉴定
一、重组过表达载体和干扰载体构建
以Nanjing35的cDNA为模板,进行PCR扩增获得DSS基因,PCR引物序列如下:
Primer3(下划线所示的序列为Kpn I重组位点):
5'—TTCTGCACTAGGTACCATGCAGCGGCGGCGGGC—3'(SEQ ID NO.6)
Primer4(下划线所示的序列为Spe I重组位点):
5'—GGACTAGTTTAAACATCATATACGGGC—3'(SEQ ID NO.7)
上述引物位于SEQ ID NO.2所示基因的编码区起始位置和编码区终止子位置,扩增产物包含了该基因的完整编码区,将PCR产物回收纯化。采用HD Cloning Kit重组试剂盒(Takara公司)将PCR产物克隆到载体pCAMBIA1390(图3)中。
In-Fusion重组反应体系(10μL):PCR产物10-200ng,经Kpn I和Spe I双酶切回收pCAMBIA1390载体50-200ng,5×In-Fusion HD Enzyme Premix 2μL,Deionized water to 10μL。枪头吹打混匀后将混合体系50℃反应15min后置于冰上,取2μL反应体系用热激法转化大肠杆菌DH5α感受态细胞(Tiangen公司)。将全部转化细胞均匀涂布在含100mg/L卡那霉素的LB固体培养基上。37℃培养12-16h,挑取克隆阳性克隆,进行测序。
干扰载体的构建同样以Nanjing35的cDNA为模板,进行PCR扩增获得DSS基因,PCR引物序列如下:
Primer5(下划线所示的序列为Kpn I重组位点):
5'—TTCTGCACTAGGTACCAGGCCTGGCCGTTGCTTATTGCGTTTG—3'(SEQ ID NO.8)
Primer6(下划线所示的序列为Sac I重组位点):
5'—CTGACGTAGGGGCGATAGAGCTCCGGTATCTAATTGCCGCTGAT—3'(SEQ ID NO.9)
Primer7(下划线所示的序列为BamH I重组位点):
5'—CGGGGATCCGTCGACTACGCCGTTGCTTATTGCGTTTG—3'(SEQ ID NO.10)
Primer8(下划线所示的序列为Mlu I重组位点):
5'—AGGTGGAAGACGCGTTACCGGTATCTAATTGCCGCTGAT—3'(SEQ ID NO.11)
将上述Primer5/6和Primer7/8扩增的产物分别命名为RNAi1和RNAi2,均包含了该基因的部分编码区,将PCR产物回收纯化。采用HD Cloning Kit重组试剂盒(Takara公司)将PCR产物克隆到载体LH-FAD2-1390RNAi(图4)中。
In-Fusion重组反应体系(10μL):RNAi1的PCR产物10-200ng,第一次用Kpn I和Sac I双酶切回收LH-FAD2-1390RNAi载体50-200ng,5×In-Fusion HD Enzyme Premix 2μL,Deionized water to 10μL,枪头吹打混匀后将混合体系50℃反应15min后置于冰上,第二次用RNAi2的PCR产物10-200ng,BamH I和Mlu I双酶切回收连接有RNAi1片段的LH-FAD2-1390RNAi载体50-200ng,5×In-Fusion HD Enzyme Premix 2μL,Deionized water to 10μL。枪头吹打混匀后将混合体系50℃反应15min后置于冰上,取2μL反应体系用热激法转化大肠杆菌DH5α感受态细胞(Tiangen公司)。将全部转化细胞均匀涂布在含100mg/L卡那霉素的LB固体培养基上。37℃培养12-16h,挑取克隆阳性克隆,进行测序。
测序结果表明,得到了含有SEQ ID NO.2所示DSS基因的重组表达载体,将含有DSS的pCAMBIA1390命名为pCAMBIA1390-DSS,含有DSS的LH-FAD2-1390RNAi命名为LH-FAD2-1390RNAi-DSS。
二、重组农杆菌的获得
用热击法将pCAMBIA1390-DSS和LH-FAD2-1390RNAi-DSS分别转化农杆菌EHA105菌株(购自美国英俊公司),得到重组菌株,提取质粒进行PCR及酶切鉴定。将PCR及酶切鉴定正确的重组菌株分别命名为EH-pCAMBIA1390-DSS和EH-LH-FAD2-1390RNAi-DSS。
三、转基因植物的获得
将EH-pCAMBIA1390-DSS转化水稻突变体dss,EH-LH-FAD2-1390RNAi-DSS转化水稻Nanjing35,具体方法为:
(1)28℃培养EH-pCAMBIA1390-DSS和EH-LH-FAD2-1390RNAi-DSS16小时,收集菌体,并稀释到含有100μmol/L的N6液体培养基(Sigma公司,C1416)中至浓度为OD600≈0.5,获得菌液;
(2)将培养至一个月的突变体dss和Nanjing 35水稻成熟胚胚性愈伤组织与步骤(1)的菌液混合侵染30min,滤纸吸干菌液后转入共培养培养基(N6固体共培养培养基,Sigma公司)中,24℃共培养3天;
(3)将步骤(2)的愈伤接种在含有100mg/L巴龙霉素(Phyto Technology Laboratories公司)的N6固体筛选培养基上第一次筛选(16天);
(4)挑取健康愈伤转入含有100mg/L巴龙霉素的N6固体筛选培养基上第二次筛选,每15天继代一次;
(5)挑取健康愈伤转入含有50mg/L巴龙霉素的N6固体筛选培养基上第三次筛选,每15天继代一次;
(6)挑取抗性愈伤转入分化培养基上分化;
得到分化成苗的T0代阳性植株。以突变体dss和Nanjing35为阴性对照。
四、转基因植株的鉴定
1、PCR分子鉴定
将步骤三获得的T0代阳性植株提取基因组DNA,以基因组DNA为模板,利用pCAMBIA1390上SEQ ID NO.2插入位点左边界附近的引物Primer3和SEQ ID NO.2上的引物Primer4作为引物对进行扩增(Primer3:5'—TTCTGCACTAGGTACCATGCAGCGGCGGCGGGC—3'(SEQ ID NO.6)和Primer4:5'—GGACTAGTTTAAACATCATATACGGGC—3'(SEQ ID NO.7)),扩增长度1446bp。利用LH-FAD2-1390RNAi上SEQ ID NO.2插入位点左边界附近的引物Primer4和SEQ ID NO.2上的引物Primer5作为引物对进行扩增(Primer5:5'—TTCTGCACTAGGTACCAGGCCTGGCCGTTGCTTATTGCGTTTG—3'(SEQ ID NO.8)和Primer6:5'—CTGACGTAGGGGCGATAGAGCTCCGGTATCTAATTGCCGCTGAT—3'(SEQ ID NO.9)),扩增长度483bp。PCR反应体系:DNA(20ng/ul)2ul,Primer5(10pmol/ul)2ul,Primer6(10pmol/ul)2ul,10xBuffer(MgCl2free)2ul,dNTP(10mM)0.4ul,MgCl2(25mM)1.2ul,rTaq(5u/ul)0.4ul,ddH2O 10ul,总体积20ul。扩增反应在PTC-200(MJ Research Inc.)PCR仪上进行:94℃3min;94℃30sec,55℃45sec,72℃1min,35个循环;72℃5min。
用试剂盒(北京Tiangen公司)纯化回收PCR产物。PCR产物用1%的琼脂糖电泳检测。
2、表型鉴定
分别将T0代转EH-pCAMBIA1390-DSS和EH-LH-FAD2-1390RNAi-DSS植株、Nanjing35和突变体dss种植在南京农业大学水稻试验站,对抽穗后小穗进行横截面切片观察和表达量分析,以及考察粒型。由图5所示,转入转EH-pCAMBIA1390-DSS的转基因植株DSS-OE1和DSS-OE2中DSS的表达量显著提高,种子的大小较突变体dss显著增大,恢复到野生型的水平。由图6所示,转入转EH-LH-FAD2-1390RNAi-DSS的转基因植株R4和R7中DSS的表达量显著降低,籽粒大小较野生型WT显著变小。说明DSS确实可以影响种子的粒型。
<110> 南京农业大学
<120>一种水稻粒型基因DSS及其编码蛋白质和应用
<160> 21
<210> 1
<211> 7550
<212> DNA
<213> 稻属水稻(Oryza sativa var. Nipponbare)
<220>
<223> 种子粒型相关基因DSS的基因序列
<400> 1
aaagaaaagg gctagagtct aagaggggag agagagagag agagagagag gaaggaaccc 60
ttcgtcctcg tcgcctcact tttgtctccc actccttcgt cggcggctcg gctcggcgca 120
ggcgcagcgg ggagaagacc aaggaggagg gagaggcgga cgcgggagcg gaagagatta 180
atttccagtg gggtttgggg cgcggtgagg aggtgaggga tgcagcggcg gcgggcgcag 240
acgtgggcgg gggtggggaa gacggcgcag gcggcggcgg cgcacgcggc gctcttctgc 300
ttcacgctcc tcctcgcgct caaagtcgac ggccgcacag cctactcctg gtggtaacgc 360
tccctgctct aaaccctagc tagcaccctc ccccgtcctc cgccgccacg ggcctccgct 420
tcgatctggc ttagtggttc ccgcgagatt gcgagttggg ggtggaatta gtggctggcg 480
tagtggtttt tttggggggg tttccatcgg atgcagatgc aggctgaggg gggaatcgga 540
ctagtccttt gcgtgcggtt gagagtcgtc gcctgcttgt ggtggtctgg tgaactaatt 600
ttctccacca gaacgattca gctctttcgt gtccttgtgt ttggacattg atgagttgat 660
gtaggcattt tgctcacgca gagggtgtgc ttcggttagt ctttagctga tgctgggcca 720
cagttcctgg ttctactgaa ggctgcactt tgagagctcg ttcttatttg gttatgtatt 780
tgtttgagta acccagcgct cttgttccta taatgatggt agcagattca gaagacattg 840
ttgactgctt tgtctgtagc agtgaaggta ttaataccga atgctaattc tgctatttcc 900
atcatgcagg attatattca tccctctatg gctatttcat ggcattgttg cccgtggaag 960
gttttcaatg ccagcccctt cgcttcctca tggccgtcat gtaagaattg gtatcaattt 1020
ctctagttag tatgcacgtg cttaccccac attttgatct gatgggtttc tatttgtatg 1080
tagtgggctc cttgccattc aattgttgca gcgccgttgc ttattgcgtt tgagctgctg 1140
ctttgcatat atctcgaaag tttgagaggt aggttcttag gttatctaga tgagagaagc 1200
tttggcgacc ataaacgaat ttcctggagg ctcttatacc ccttctctct gtttgttctt 1260
ccgcagttaa aagtaagccg actgttgatt tgaagattgt attccttcct cttctggcct 1320
ttgaagtgat tattcttgct gacaatttca ggtaatgaat ctgaacaatt attttgcatg 1380
cctttaatac tgtatcagta aatgcacaaa cgcactacca attggcacga ttgtatgtgc 1440
cttactgttt tatctgctta tgtattctgc aagtcttaag tgctgaatgt aactagtttt 1500
tttttccaag attgtttttc tgactaagca gctagcactt ataaactgtg ccatgaactc 1560
gtaatatgtc ctaacctatt tttggttacg tctgggattg tagtaagacg acctgaccta 1620
ttgtcaaata tggtatgcac cttcaagagc agctaacgcg ttttagatta taaatttctt 1680
gcaaccaaaa gaattcaatt atctggtgtt ctgttgttct caatggccgg ttcttggtgt 1740
ctgtcttttt ctccactgga aagaatactg aaattactca actgcctctt tgtttatttt 1800
tgcacactgc ttaggctgtg ttcgccagtc cacgttccca accggaacag tacgcgcgga 1860
aaacggagcg gtccattagc gcgtaattaa ttaagtatta gctatttttt tttcaaaaat 1920
agattaattt gattttttaa gcaacttttg tatagaaact ttttgcaaaa aacacaccgt 1980
ttaacagttt gaaaagtgtg cgcgtggaaa acgagggaga ggggttggaa aaaggggtgc 2040
cgaacacagc cttagtcagg ttcaatgata tctttctgtt ggttgcaaaa taaattaatc 2100
atgatcatta tactcatatg gtttctgttg gttgcaaaat aaattaataa ttatcattat 2160
acttgacgac ttggtatgta gagggtagca ctaagtgctt gtttatcatt gcttgtttga 2220
tagcaggttg aattatctca attacaaata tactcaagtc tactgttgat attattctta 2280
gttttgttat tccgtacaac attttttttg ctacataata ataaatggtg gcattctatc 2340
caaaagttac aaatggtgtt tttaaaaggt aaatttcgca atactgaact accatttgca 2400
aaactatcgc aaaagacaca tgtttattca caattttgga gaactacact ttttagttgc 2460
aaaatgtgca gcaaaactac actcctatca gagaaacagg tctgataggt tgggccctct 2520
catcagtcat cagtatttca tccgggttgt ttctgtttct gatgcatgtg ttggttaaaa 2580
agaaacagcc tacacatgca acactgacta gtggacctag cctgtcaggc tcattggcat 2640
tttcagtaat ttagttttgt gaaacttttc acaaccaaag gtattcctcc gaaatcgtcg 2700
caaaagtgtg tttgcgattg ttttagcgat ggcttttgtc tggtttaatg aaattgaatc 2760
attgttaaaa tttagcttgt cacacaatca gtactgttgt tggtatgcaa cgcataaatt 2820
ggatgcaatt cataaagata tgtgctgacc aaatcatgaa ccttaatttg gccaaaaata 2880
tctagagata ttagttgtta atacaatagt agcgctaaag ttaatttgga tgttaacctt 2940
tatttttttt ccttgcattg gtttgactat tcagaatgtg tagagcttta atgccaggag 3000
atgaagaaag tatgagcgat gaagctattt gggagacact tcctgtgagt ataagtacta 3060
gtaactagtg gttcttttta agaaattatc tccattagct tcaatttgag cttaactttt 3120
atttactata agtaaccata cttctaccaa atcatcttat aaaaatatat tagaaacttt 3180
taaatacgat gataactaaa ttagagagct gaatatcatg caacaaaatg cattattttt 3240
cagtccattt ttagtggaat actggattgg aataatttta ttgataagaa taaatcagct 3300
gcaaggatga aagtagaatc tcatgaactt gtcaattgac gatgctgtat tttcacatta 3360
tggagcctat atgttggact tgtaccagct taatatgggt tgatgattta ttaagtttaa 3420
caaagcaaaa catatacagt gaacaaatat tcactacata atgaagtaaa ttctgttcaa 3480
agtttaagag aattaaacct tgatcagggc ttgtgtttat agaattatgg tttgatcatt 3540
tcattctatc tgatactcta tttgtcacag cagaatgtac cgatttacat tgtaatattt 3600
cacaccgatg taaagtctat gaatgaataa cattgtgtgt ggctctttta taagttatct 3660
atgatatcat atttcttatc ttgtgctgac tgccgtgttc tagaatagtg tggactatac 3720
actgttcttt tcatcttata tgacacggct tctatttgct atcagcactt ttgggttgca 3780
atttctatgg tgtttcttat agctgctaca accttcacac ttttgaagct gtctggtaaa 3840
gtttcctgga tctccttttt gttttttgac cttcattatg gcatgtccta tttgttatgt 3900
gttttcaagc actgtagact gtagagttaa aaagtttgct tccttgcaca tgactaatat 3960
tgtttgtttg tctgctaagc ctctatagtt ggtaggatat ggctttctca aaagtcgctt 4020
cattgtttac tagagtggtt gtcacaatga cattcttcta agagtgatta ggtagttgca 4080
aatgagacaa tagttactaa aacaagatta gattgtcaat taaccataaa atctggaaac 4140
attacattca gcagcttggt tttgaaagcc aggcagtttt ctactatttg gaaatggctg 4200
gtgatttcac ctgaactggc cgggtttcta tttttggcag tttaaagcat aaattcgtgc 4260
aagttaaaac tatctttagt ataagcaata caatgttgga tagagagcaa aaagatattc 4320
ctagggttcc cgtgatgtga agacccacca gctgctttcc cattcacatg catatatgca 4380
acatttttcc atggtttctc actctaaaga gtgtaatctt ccaattccca acacaaaatc 4440
gaagtcagct tctccacact gaatcaaact ccttaatgca tttcatgtgg tcgattttct 4500
ttgacgatac tttcaatttg gtgatctatt acagttcttt tttttttggt atacgcaaaa 4560
gacttgtgta gcattaagga gtttgaatgt tacatcccct gcctagctcc atatagctgg 4620
gcaactacct aatgagtagt acaagattaa ttctcgtgat acaattgtgc gacctatgtg 4680
ccagagcgat gttagaccac agattgagcc atctttgctc ctgcaacgat ccagagtctt 4740
gcctctgcgg tgattgctgc aatcaccgca tccagttcct actttcccaa ttgaaaatcc 4800
ggtccttcaa gattacccaa gcgaccagga tccatcaaag ttctgagttg ttccagttac 4860
taggggctgc tttgtctgcc tcctccatga gcttttaagt gctacttttt aaatcaaatc 4920
atttattagt tcgatgtgat aagaacaaca tgttcagcaa actatcttag attgtacaat 4980
attcaggttt ttatttctct tcggcctaat tttcctctac tctgaaatgt tttgtgatat 5040
tattattgca tgacaggtga tgttggtgct ttgggatggt gggatttgtt tataaattat 5100
gggtgagact agtctcaata gcaattttct ttattaacga gatctgttat aatataatcc 5160
agcaccttct tttttgtaca gaatcgcgga gtgttttgca tttcttgttt gtactagatg 5220
gtttaatccc atgattcata aatctcctaa tcctggggag gctagctcat catcagcggc 5280
aattagatac cgtgattggg agagtggtct tctcctccca tcactagaag atcatgaaca 5340
agagaggctc tgtggtcttc ctgacatagg aggtcacgta atgaaaatac cactggtgat 5400
tttccaagtt ttgctttgta tgcgcttgga ggtacgtgtc atttatatat ttctattggg 5460
ttacatatgg ttgataaact ggtagatgca cttgtagaca gacattggat ggggattggg 5520
gagcttccag gaattgtttt ttaattatgt catgtaacag aacacagtaa cactatttgg 5580
aaaaaatgca aaacaagaac tttgtccatt ttctgagttc gtctaggggg tcaacgcttg 5640
ttagtggctt tttatcatga gctggatcaa taataatctt gaaaacatca tttgcttttg 5700
ttttttcagg gtacgcctcc tagtgctcag tatattccga tatttgcact gttctcccca 5760
ctgtttattt tacaaggcgc tggtgtcctt ttctctctag caagattgtt ggagaaggtt 5820
gttctactat tacgaaatgg accagttagt cctaattacc ttacaatctc atcaaaagtc 5880
cgtgattgct ttgcttttct tcatcgtggt tcaaggtaat atttgatagc tattatgagc 5940
tacttctcta tatgtttgtt ttcttgttgg cttatcttac tttgcatcac acaggcttct 6000
tggttggtgg tctattgatg aaggcagcaa agaagagcaa gcccggttat tctatactga 6060
atctactggg tacatgatag ttgacttcag cctgttcata ttgttaattt agatcctatt 6120
aagctggtca agttgtttca tttcctctat gtttacagtt ctttttgcgc atccacatcc 6180
actttctata ctgatttcct gcctggttgc cttttggttt taaggtacaa cacattttgt 6240
ggctatccac ctgaggtagt caggaaaatg cctaagaggg atcttgcaga agaggttaca 6300
ttctctcttt tcattttatt attgtttacc ttattaatgt tatgtgcact ctattttatc 6360
ataatataac tattttccta cttattatct ttcaggtatg gaggctccaa gcagctttgg 6420
gagagcaatc agaaattacc aaatgtacca agcaggaatt tgaaaggctt caaaatgtac 6480
catctccttg tgacttgtga agtttcatca ttttacatta tataaattgg tgcaatacat 6540
cctatagaca tgattgagtc cattaacttg aggacatgcc atttaggtcg ctcagcttac 6600
acaataagat cacatatgtc tgagtcgttc atgtttaagg agacttatgt gatatagcct 6660
tgaaactttt agcaaactac aattttaggt accgagaaat attgaattat caagtttgtg 6720
ggttcaagtg ggacatccat acaactctaa gaaactcatt tcattttaac cttttctgtt 6780
gttttattta agaacctaag tcactacagc tctatggcac taactgaaac ttccagagag 6840
gcagagagcg ctgatgatga tctgttggtt gtctgaccgg ctctttttcc tttgttgact 6900
aagtacttcc ttttccattt caggagaagg ttctttgtag gatttgctac gagggggaga 6960
tatgcatggt cttacttcct tgccggcaca gaacattatg caagtatgtt tccagtcact 7020
tgttaagcca ctttggatgc tcttacatgt tgatttggaa ctgacagttt tgttgatggt 7080
tctgtgatag gacttgttct gataagtgca agaaatgtcc aatctgccgt gtgcccattg 7140
aagaacgcat gcccgtatat gatgtttaaa cttcgctaac tcagatgaac gttacaaatt 7200
tgtacatgtt ggttgtgcaa tgtcgcgcca tgtagtctca atcacaactt taagctgatt 7260
gaggtttgca caagttcaga aaggtttacc gaatatggag aaaatataaa gcatatcatg 7320
tctaaccaaa agcatgaaaa ggtagttgat gatcattttg ccggttacaa ttatgtactg 7380
taagtatgtc atcggtggtt ttaacttttt tttttggtga tcgatagatg ctccagttag 7440
attgtgtagc atcttctcaa gtttatgcat tgtctgaatg taaataagaa tattgtcttg 7500
tttgagtgtt gtagtgctct ttggttgaga agagtagaaa agaaaaatgt 7550
<210> 2
<211> 1422
<212> DNA
<213> 稻属水稻(Oryza sativa var. Nipponbare)
<220>
<223> 种子粒型相关基因DSS的CDS序列
<400> 2
atgcagcggc ggcgggcgca gacgtgggcg ggggtgggga agacggcgca ggcggcggcg 60
gcgcacgcgg cgctcttctg cttcacgctc ctcctcgcgc tcaaagtcga cggccgcaca 120
gcctactcct ggtggattat attcatccct ctatggctat ttcatggcat tgttgcccgt 180
ggaaggtttt caatgccagc cccttcgctt cctcatggcc gtcattgggc tccttgccat 240
tcaattgttg cagcgccgtt gcttattgcg tttgagctgc tgctttgcat atatctcgaa 300
agtttgagag ttaaaagtaa gccgactgtt gatttgaaga ttgtattcct tcctcttctg 360
gcctttgaag tgattattct tgctgacaat ttcagaatgt gtagagcttt aatgccagga 420
gatgaagaaa gtatgagcga tgaagctatt tgggagacac ttcctcactt ttgggttgca 480
atttctatgg tgtttcttat agctgctaca accttcacac ttttgaagct gtctggtgat 540
gttggtgctt tgggatggtg ggatttgttt ataaattatg gaatcgcgga gtgttttgca 600
tttcttgttt gtactagatg gtttaatccc atgattcata aatctcctaa tcctggggag 660
gctagctcat catcagcggc aattagatac cgtgattggg agagtggtct tctcctccca 720
tcactagaag atcatgaaca agagaggctc tgtggtcttc ctgacatagg aggtcacgta 780
atgaaaatac cactggtgat tttccaagtt ttgctttgta tgcgcttgga gggtacgcct 840
cctagtgctc agtatattcc gatatttgca ctgttctccc cactgtttat tttacaaggc 900
gctggtgtcc ttttctctct agcaagattg ttggagaagg ttgttctact attacgaaat 960
ggaccagtta gtcctaatta ccttacaatc tcatcaaaag tccgtgattg ctttgctttt 1020
cttcatcgtg gttcaaggct tcttggttgg tggtctattg atgaaggcag caaagaagag 1080
caagcccggt tattctatac tgaatctact gggtacaaca cattttgtgg ctatccacct 1140
gaggtagtca ggaaaatgcc taagagggat cttgcagaag aggtatggag gctccaagca 1200
gctttgggag agcaatcaga aattaccaaa tgtaccaagc aggaatttga aaggcttcaa 1260
aatgagaagg ttctttgtag gatttgctac gagggggaga tatgcatggt cttacttcct 1320
tgccggcaca gaacattatg caagacttgt tctgataagt gcaagaaatg tccaatctgc 1380
cgtgtgccca ttgaagaacg catgcccgta tatgatgttt aa 1422
<210> 3
<211> 473
<212> PRT
<213> 稻属水稻(Oryza sativa var. Nipponbare)
<220>
<223> 种子粒型相关基因DSS的氨基酸序列
<400> 3
Met Gln Arg Arg Arg Ala Gln Thr Trp Ala Gly Val Gly Lys Thr
1 5 10 15
Ala Gln Ala Ala Ala Ala His Ala Ala Leu Phe Cys Phe Thr Leu
20 25 30
Leu Leu Ala Leu Lys Val Asp Gly Arg Thr Ala Tyr Ser Trp Trp
35 40 45
Ile Ile Phe Ile Pro Leu Trp Leu Phe His Gly Ile Val Ala Arg
50 55 60
Gly Arg Phe Ser Met Pro Ala Pro Ser Leu Pro His Gly Arg His
65 70 75
Trp Ala Pro Cys His Ser Ile Val Ala Ala Pro Leu Leu Ile Ala
80 85 90
Phe Glu Leu Leu Leu Cys Ile Tyr Leu Glu Ser Leu Arg Val Lys
95 100 105
Ser Lys Pro Thr Val Asp Leu Lys Ile Val Phe Leu Pro Leu Leu
110 115 120
Ala Phe Glu Val Ile Ile Leu Ala Asp Asn Phe Arg Met Cys Arg
125 130 135
Ala Leu Met Pro Gly Asp Glu Glu Ser Met Ser Asp Glu Ala Ile
140 145 150
Trp Glu Thr Leu Pro His Phe Trp Val Ala Ile Ser Met Val Phe
155 160 165
Leu Ile Ala Ala Thr Thr Phe Thr Leu Leu Lys Leu Ser Gly Asp
170 175 180
Val Gly Ala Leu Gly Trp Trp Asp Leu Phe Ile Asn Tyr Gly Ile
185 190 195
Ala Glu Cys Phe Ala Phe Leu Val Cys Thr Arg Trp Phe Asn Pro
200 205 210
Met Ile His Lys Ser Pro Asn Pro Gly Glu Ala Ser Ser Ser Ser
215 220 225
Ala Ala Ile Arg Tyr Arg Asp Trp Glu Ser Gly Leu Leu Leu Pro
230 235 240
Ser Leu Glu Asp His Glu Gln Glu Arg Leu Cys Gly Leu Pro Asp
245 250 255
Ile Gly Gly His Val Met Lys Ile Pro Leu Val Ile Phe Gln Val
260 265 270
Leu Leu Cys Met Arg Leu Glu Gly Thr Pro Pro Ser Ala Gln Tyr
275 280 285
Ile Pro Ile Phe Ala Leu Phe Ser Pro Leu Phe Ile Leu Gln Gly
290 295 300
Ala Gly Val Leu Phe Ser Leu Ala Arg Leu Leu Glu Lys Val Val
305 310 315
Leu Leu Leu Arg Asn Gly Pro Val Ser Pro Asn Tyr Leu Thr Ile
320 325 330
Ser Ser Lys Val Arg Asp Cys Phe Ala Phe Leu His Arg Gly Ser
335 340 345
Arg Leu Leu Gly Trp Trp Ser Ile Asp Glu Gly Ser Lys Glu Glu
350 355 360
Gln Ala Arg Leu Phe Tyr Thr Glu Ser Thr Gly Tyr Asn Thr Phe
365 370 375
Cys Gly Tyr Pro Pro Glu Val Val Arg Lys Met Pro Lys Arg Asp
380 385 390
Leu Ala Glu Glu Val Trp Arg Leu Gln Ala Ala Leu Gly Glu Gln
395 400 405
Ser Glu Ile Thr Lys Cys Thr Lys Gln Glu Phe Glu Arg Leu Gln
410 415 420
Asn Glu Lys Val Leu Cys Arg Ile Cys Tyr Glu Gly Glu Ile Cys
425 430 435
Met Val Leu Leu Pro Cys Arg His Arg Thr Leu Cys Lys Thr Cys
440 445 450
Ser Asp Lys Cys Lys Lys Cys Pro Ile Cys Arg Val Pro Ile Glu
455 460 465
Glu Arg Met Pro Val Tyr Asp Val
470 473
<210> 4
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> Primer1
<400> 4
cgggagcgga agagatta 18
<210> 5
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> Primer2
<400> 5
tcggtaaacc tttctgaact t 21
<210> 6
<211> 33
<212> DNA
<213> 人工序列
<220>
<223> Primer3
<400> 6
ttctgcacta ggtaccatgc agcggcggcg ggc 33
<210> 7
<211> 27
<212> DNA
<213> 人工序列
<220>
<223> Primer4
<400> 7
ggactagttt aaacatcata tacgggc 27
<210> 8
<211> 43
<212> DNA
<213> 人工序列
<220>
<223> Primer5
<400> 8
ttctgcacta ggtaccaggc ctggccgttg cttattgcgt ttg 43
<210> 9
<211> 44
<212> DNA
<213> 人工序列
<220>
<223> Primer6
<400> 9
ctgacgtagg ggcgatagag ctccggtatc taattgccgc tgat 44
<210> 10
<211> 38
<212> DNA
<213> 人工序列
<220>
<223> Primer7
<400> 10
cggggatccg tcgactacgc cgttgcttat tgcgtttg 38
<210> 11
<211> 39
<212> DNA
<213> 人工序列
<220>
<223> Primer8
<400> 11
aggtggaaga cgcgttaccg gtatctaatt gccgctgat 39
<210> 12
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> a13上游引物
<400> 12
aggcgattcc catttgcttg c 21
<210> 13
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> a13下游引物
<400> 13
agcagcgagg agggagaaga gg 22
<210> 14
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> Indel3-4上游引物
<400> 14
cattctaaat gtgaccgtta tgtcc 25
<210> 15
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> Indel3-4下游引物
<400> 15
gtaccgggtc gctttgttct 20
<210> 16
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> Indel3-3上游引物
<400> 16
gtggggaaca ggtttgaccg 20
<210> 17
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> Indel3-3下游引物
<400> 17
tgcagcgttt tcgcatcgt 19
<210> 18
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> a15上游引物
<400> 18
acggctccac gagaacatct gg 22
<210> 19
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> a15下游引物
<400> 19
ctgctgcgga attgagcttg g 21
<210> 20
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> a1上游引物
<400> 20
caggatcgga caggatcaca gg 22
<210> 21
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> a1下游引物
<400> 21
gctcctggcg cagctataga cc 22
<210> 22
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> a2上游引物
<400> 22
tccacgtgtt atcctctctt tgc 23
<210> 23
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> a2下游引物
<400> 23
ccagattcct gcgttgtaca gg 22
<210> 24
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> a19上游引物
<400> 24
aagtgaggcg acgaggacga agg 23
<210> 25
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> a19下游引物
<400> 25
aaacgcaacg cacagaagga agg 23
<210> 26
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> Indel3-9上游引物
<400> 26
tgtcatcgtt gcatgtttgt t 21
<210> 27
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> Indel3-9下游引物
<400> 27
cagcagttct cgcatagtcc t 21
<210> 28
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> RM426上游引物
<400> 28
atgagatgag ttcaaggccc 20
<210> 29
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> RM426下游引物
<400> 29
aactctgtac ctccatcgcc 20
<210> 30
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> RM168上游引物
<400> 30
tgctgcttgc ctgcttcctt t 21
<210> 31
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> RM168下游引物
<400> 31
gaaacgaatc aatccacggc 20
<210> 32
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> RM1350上游引物
<400> 32
aggaacaccc aagagagtca tgc 23
<210> 33
<211> 22
<212> DNA
<213> 人工序列
<220>
<223> RM1350下游引物
<400> 33
gcaagaaagc tctgctccat gc 22
<210> 34
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> RM8277上游引物
<400> 34
cagcagagac tatagacact caagc 25
<210> 35
<211> 24
<212> DNA
<213> 人工序列
<220>
<223> RM8277下游引物
<400> 35
tgcctagcta ctctaggtga aacc 24
<210> 36
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> RM3225上游引物
<400> 36
gatagaggat tgggtgcgtg tgc 23
<210> 37
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> RM3225下游引物
<400> 37
tacgccaacc aattccaaac acc 23
序列表
1
- 还没有人留言评论。精彩留言会获得点赞!
- 腈水解酶突变体及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白AsTMK1及其编码基因和应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种花狭口蛙的基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 一种泽陆蛙基因及其编码的多肽和该多肽的用途的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 蛋白StTrxF、编码基因及其在提高植物淀粉含量中的应用的制造方法与工艺
- 蛋白质及其编码基因在调控植物抗黄萎病性中的应用的制造方法与工艺
- 甘薯耐逆相关蛋白IbFBA2、编码基因、重组载体与应用的制造方法与工艺
- 植物抗旱相关蛋白ZmNAC111及其编码基因与应用的制造方法与工艺
- 植物抗旱相关蛋白EtSnRK2.2及其编码基因和应用的制造方法与工艺
- OsSAPK7蛋白及其编码基因在提高水稻白叶枯病抗性中的应用的制造方法与工艺
- 一种抗除草剂抗虫融合基因、编码蛋白及应用的制造方法与工艺
- 毛果杨PtrZFP103基因及其编码蛋白和应用的制造方法与工艺
- 大豆bHLH转录因子基因GmFER及其编码蛋白和应用的制造方法与工艺
- 一种水稻MIT1基因、其编码蛋白及应用的制造方法与工艺
- 蛋白StTrxF、编码基因及其在提高植物淀粉含量中的应用的制造方法与工艺
- 蛋白质及其编码基因在调控植物抗黄萎病性中的应用的制造方法与工艺
- 植物抗旱相关蛋白ZmNAC111及其编码基因与应用的制造方法与工艺
- 核盘菌凝集素SSL‑6蛋白及其编码基因与应用的制造方法与工艺