基于美洲南瓜转录组序列开发的SSR引物组及其应用的制作方法
本发明具体涉及基于美洲南瓜转录组序列开发的ssr引物组及其应用,属于生物技术领域。
背景技术:
美洲南瓜(cucubitapepol.)是葫芦科南瓜属的一年生蔓性草本植物,是人类晟早栽培的作物之一,其味道鲜美,营养丰富,也有药用价值的优点受到大众喜爱。在美洲南瓜的生产上,其适应性较强。种植周期较短,栽培相对容易,产品产量较高,供应周期很长,也比较容易贮存且适宜间作套种的好处,在我国有大范围的种植,现已成为我国瓜类蔬菜的主要栽品种之一,栽培面积次于黄瓜。我国美洲南瓜育种发展时间较短,近几年各地才逐渐开始对美洲南瓜种质资源进行收集和整理。由于缺乏大量的多态性分子标记,其遗传学和基因组学方面的研究比较滞后。因此,查清美洲南瓜种质资源的遗传背景、开展相应的遗传学基础研究、定位重要经济性状是我国美洲南瓜选育工作中首先需要解决的问题。
分子标记是以个体间遗传物质内核苷酸序列变异为基础的遗传标记,能在dna水平上反映植物遗传基础的差异,是dna水平遗传多态性的直接的反映。简单重复序列(simplesequencerepeat,ssr)广泛分布于各类真核生物基因组的不同位置,由于ssr的重复次数不同和重复程度不同,使其呈现高度的多态性。与其它分子标记技术相比,ssr标记具有多态信息含量高、共显性遗传、技术简单、重复性好、特异性强、操作便利、并在基因组中分散分布等优点已成为最受人们欢迎的分子标记之一,被认为是可靠性最高的分子标记类型之一。在许多领域广泛应用。目前美洲南瓜ssr报道非常少,而分子标记的数量影响着种质资源遗传多样性分析的准确性和遗传图谱构建的精确性,现有的美洲南瓜ssr分子标记数量远远不能满足美洲南瓜分子生物学研究的需求,因此大量开发ssr标记仍是目前美洲南瓜研究的重要工作之一。鉴于此,开发基于美洲南瓜转录组序列的ssr引物组,将会对美洲南瓜遗传多样性分析、亲缘关系鉴定、dna指纹图谱构建、重要性状基因的定位、克隆及分子标记辅助选择育种和比较基因组学研究等起重要推动作用。
技术实现要素:
针对现有技术的不足,本发明的目是提供一套基于美洲南瓜转录组序列开发的ssr引物组及其应用。
本发明所述的基于美洲南瓜转录组序列开发的ssr引物组,该ssr引物组有35对引物,分别为:
第1对引物,其序列如seqidno:1和seqidno:2所示;
第2对引物,其序列如seqidno:3和seqidno:4所示;
第3对引物,其序列如seqidno:5和seqidno:6所示;
第4对引物,其序列如seqidno:7和seqidno:8所示;
第5对引物,其序列如seqidno:9和seqidno:10所示;
第6对引物,其序列如seqidno:11和seqidno:12所示;
第7对引物,其序列如seqidno:13和seqidno:14所示;
第8对引物,其序列如seqidno:15和seqidno:16所示;
第9对引物,其序列如seqidno:17和seqidno:18所示;
第10对引物,其序列如seqidno:19和seqidno:20所示;
第11对引物,其序列如seqidno:21和seqidno:22所示;
第12对引物,其序列如seqidno:23和seqidno:24所示;
第13对引物,其序列如seqidno:25和seqidno:26所示;
第14对引物,其序列如seqidno:27和seqidno:28所示;
第15对引物,其序列如seqidno:29和seqidno:30所示;
第16对引物,其序列如seqidno:31和seqidno:32所示;
第17对引物,其序列如seqidno:33和seqidno:34所示;
第18对引物,其序列如seqidno:35和seqidno:36所示;
第19对引物,其序列如seqidno:37和seqidno:38所示;
第20对引物,其序列如seqidno:39和seqidno:40所示;
第21对引物,其序列如seqidno:41和seqidno:42所示;
第22对引物,其序列如seqidno:43和seqidno:44所示;
第23对引物,其序列如seqidno:45和seqidno:46所示;
第24对引物,其序列如seqidno:47和seqidno:48所示;
第25对引物,其序列如seqidno:49和seqidno:50所示;
第26对引物,其序列如seqidno:51和seqidno:52所示;
第27对引物,其序列如seqidno:53和seqidno:54所示;
第28对引物,其序列如seqidno:55和seqidno:56所示;
第29对引物,其序列如seqidno:57和seqidno:58所示;
第30对引物,其序列如seqidno:59和seqidno:60所示;
第31对引物,其序列如seqidno:61和seqidno:62所示;
第32对引物,其序列如seqidno:63和seqidno:64所示;
第33对引物,其序列如seqidno:65和seqidno:66所示;
第34对引物,其序列如seqidno:67和seqidno:68所示;
第35对引物,其序列如seqidno:69和seqidno:70所示。
所述基于美洲南瓜转录组序列开发的ssr引物组在鉴定美洲南瓜亲缘关系和遗传特性中的应用。
本发明突出的效果是:1)本发明以提取的美洲南瓜总dna为鉴定材料,在任何生长时期和部位取材都不影响反应结果;2)本发明的35对ssr引物多态性丰富,扩增稳定,重复性好,扩增条带清晰,具有简便、快捷、特异等特点;3)通过大量的筛选工作,得到了多态性的ssr引物组,进行美洲南瓜多样性评价、亲缘关系分析、品种鉴定和品种权保护等提供分子水平上的依据,促进了美洲南瓜遗传育种水平的提高和美洲南瓜产业的发展。
附图说明
图1:引物有效性扩增验证。其中,m:marker;1-150:分别为150条引物。
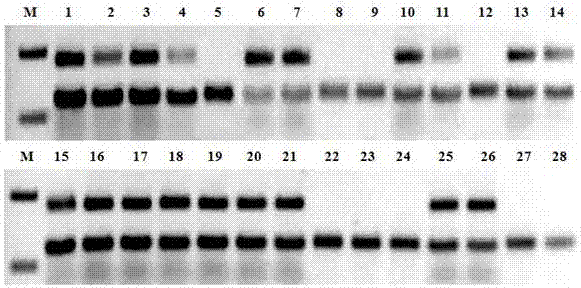
图2:引物xh4对28份美洲南瓜材料的扩增结果。其中,m:marker;1-28:美洲南瓜材料。
图3:基于35对美洲南瓜ssr引物组对28份美洲南瓜材料聚类分析。其中,1-28:美洲南瓜材料。
具体实施方式
下面结合实施例对本发明作进一步的说明,但并不局限于此。
一、转录组数据来源
美洲南瓜转录组数据来源于本课题组2016年对果实进行illumina高通量深度测序的结果。样品委托北京百迈客生物科技有限公司rna-seq转录组测序,并通过denovo方法,组装得到83650条unigene,作为分析数据。
二、转录组ssr位点鉴别及ssr引物设计
使用软件misa对丝瓜转录组中的ssr位点搜索,搜索标准为:重复单元长度2~6bp,二核苷酸、三核苷酸、四核苷酸、五核苷酸和六核苷酸最少重复次数分别为6、5、5、4和4次。用primer3.0软件对ssr重复单元前后的序列进行引物设计及评价,每条ssr产生3对引物。引物序列长度18~25bp,引物太短不能保证扩增出来序列的独特性,引物较长可能会与错误配对序列杂交,降低了特异性,扩增产物长度100~280bp,gc含量40%~60%,退火温度55~65℃,上、下游引物的退火温度值相差不大于5℃。尽量避免出现发卡结构、二聚体、错配和引物二聚体等。
设计引物时,引物不能存在ssr,此外与unigene序列比对时,其5′端允许有3个碱基的错配,3′端允许有1个碱基的错配,最后筛选出唯一匹配的引物。从中随机挑选150对20bp以上的2~6不同重复单元核苷酸引物,由上海博尚生物技术有限公司合成。
三、dna提取
采用ctab(十六烷基三乙基溴化铵)法提取28个美洲南瓜(表1)基因组dna,具体步骤:
(1)用酒精擦拭所选取的长势良好,形态完整的美洲南瓜幼嫩叶片,之后快速剪取0.3g嫩叶放入研钵中,加入液氮和0.1g的pvpp快速充分研磨至粉末状,之后将粉末放入1.5ml的离心管中;
(2)向离心管中加入600μl预热至65℃的2%ctab提取缓冲液和7μlβ-琉基乙醇,充分混匀后,放入65℃水浴锅中1h,期间多次摇匀;
(3)从水浴锅中取出离心管冷却至室温,加入等体积的氯仿/异戊醇(24:1),轻缓颠倒混匀,静置10min,后于4℃下12000rpm离心10min;
(4)用移液枪取离心管中的上清液加入另一新的1.5ml离心管中,随后加入100μl3mol/lnaac和300μl的氯仿/异戊醇充分混匀,在4℃下12000rpm离心10min;
(5)再次用移液枪吸取上清液至新的1.5ml离心管中,并加入0.6倍体积异丙醇,轻轻颠倒混匀至能看到白色絮状物,后于4℃冰箱静置30~60min,之后于4℃下12000rpm离心10min;
(6)用75%的乙醇洗涤dna2-3次,随后放于超净工作台上。将风干后的dna溶于100μlte溶液,再加入2.5μlrnasea去除rna,并存于37℃的水浴锅中20min-30min保存备用;
(7)吸取4μldna溶液与2μl溴酚蓝混合,在1%的琼脂糖凝胶进行电泳检测dna纯度,保存于4℃或-20℃备用。
表1美洲南瓜材料
四、ssr引物筛选
选择一个美洲南瓜品种dna进行扩增,验证引物的有效性。结果表明,114对引物实现有效扩增(图1中的亮白条带),占150对ssr引物的76%。
选择形态差异大的5个美洲南瓜品种基因组dna为模板,对上述114对有效引物进行多态性丰富、重复性好、扩增稳定验证,筛选出35对多态性丰富、重复性好、扩增稳定美洲南瓜ssr引物组(表2)。
五、ssr引物组的有效性检验
利用35对ssr引物组对从国内外收集的28份美洲南瓜种质资源材料(见表1)进行多样性分析。发现这35对引物在28个不同美洲南瓜品种上均有扩增产物,且多态性高(部分引物对扩增结果如图2所示),聚类分析结果(图3)表明这35对引物能将28个不同美洲南瓜品种分为三大类,说明这35对引物(即本发明所述引物对,其特征如表2所示)可以用于美洲南瓜种质资源遗传多样性分析、亲缘关系和遗传特性等研究中。
sequencelisting
<110>福建省农业科学院作物研究所
<120>基于美洲南瓜转录组序列开发的ssr引物组及其应用
<130>70
<160>70
<170>patentinversion3.3
<210>1
<211>20
<212>dna
<213>人工序列
<400>1
cttgccaaaacaaagcaaca20
<210>2
<211>20
<212>dna
<213>人工序列
<400>2
gtgtaccacccgacaatcct20
<210>3
<211>20
<212>dna
<213>人工序列
<400>3
gaagcagaggaccagtcagc20
<210>4
<211>20
<212>dna
<213>人工序列
<400>4
gcgtttgctgccattatttt20
<210>5
<211>20
<212>dna
<213>人工序列
<400>5
tcttccttcctccaattccc20
<210>6
<211>20
<212>dna
<213>人工序列
<400>6
tctttgtccggagaagttgc20
<210>7
<211>20
<212>dna
<213>人工序列
<400>7
tcaaccccttcactctcacc20
<210>8
<211>20
<212>dna
<213>人工序列
<400>8
cgctccctcatagtccgtta20
<210>9
<211>20
<212>dna
<213>人工序列
<400>9
ggataccagacacctaccgc20
<210>10
<211>20
<212>dna
<213>人工序列
<400>10
agcaactgtgaaactgggct20
<210>11
<211>20
<212>dna
<213>人工序列
<400>11
ctaaacccaaacctacccgc20
<210>12
<211>20
<212>dna
<213>人工序列
<400>12
ccacacaaggaaagggtcac20
<210>13
<211>20
<212>dna
<213>人工序列
<400>13
aaggctgctggtgaatgagt20
<210>14
<211>20
<212>dna
<213>人工序列
<400>14
ttcccacctgggtgttgtat20
<210>15
<211>20
<212>dna
<213>人工序列
<400>15
atcagcagtagaggcgtcgt20
<210>16
<211>20
<212>dna
<213>人工序列
<400>16
tgattttgcagcgttgattc20
<210>17
<211>20
<212>dna
<213>人工序列
<400>17
actttcagttggtggggaga20
<210>18
<211>20
<212>dna
<213>人工序列
<400>18
gaagaaccccaagagatgga20
<210>19
<211>20
<212>dna
<213>人工序列
<400>19
tctgtccggaaagttcaacc20
<210>20
<211>20
<212>dna
<213>人工序列
<400>20
tcgttttcatcttcagcacg20
<210>21
<211>20
<212>dna
<213>人工序列
<400>21
gatgatgatgacatgcctgg20
<210>22
<211>20
<212>dna
<213>人工序列
<400>22
atcaaccatcaatccccaaa20
<210>23
<211>20
<212>dna
<213>人工序列
<400>23
cagcagcagaacatcaggaa20
<210>24
<211>20
<212>dna
<213>人工序列
<400>24
ccccacaacaaaaccagaat20
<210>25
<211>20
<212>dna
<213>人工序列
<400>25
ttcattcaaggagacgggac20
<210>26
<211>20
<212>dna
<213>人工序列
<400>26
accattgtttcctcgttcca20
<210>27
<211>20
<212>dna
<213>人工序列
<400>27
atcaagggaggatgtgttgg20
<210>28
<211>21
<212>dna
<213>人工序列
<400>28
ggtgacagtaacagaggcagc21
<210>29
<211>21
<212>dna
<213>人工序列
<400>29
tcaaccccaccctacaataca21
<210>30
<211>20
<212>dna
<213>人工序列
<400>30
taagagatccgaaccgttgc20
<210>31
<211>20
<212>dna
<213>人工序列
<400>31
acacgggaatctcgaatcag20
<210>32
<211>20
<212>dna
<213>人工序列
<400>32
tggggttttctccattttca20
<210>33
<211>20
<212>dna
<213>人工序列
<400>33
gttcatccacagccaggaat20
<210>34
<211>20
<212>dna
<213>人工序列
<400>34
gaagaaaatgggtgcctgaa20
<210>35
<211>20
<212>dna
<213>人工序列
<400>35
gcctccttcaatggaatcaa20
<210>36
<211>20
<212>dna
<213>人工序列
<400>36
ctgtttttcgggttctcctg20
<210>37
<211>20
<212>dna
<213>人工序列
<400>37
ggacgaattcttctccgtca20
<210>38
<211>20
<212>dna
<213>人工序列
<400>38
ccctagaaatcccttagccg20
<210>39
<211>20
<212>dna
<213>人工序列
<400>39
cgaactcggagaagaagtcg20
<210>40
<211>20
<212>dna
<213>人工序列
<400>40
actgctcagcaatttcagca20
<210>41
<211>20
<212>dna
<213>人工序列
<400>41
gcagccaattcaaccagttt20
<210>42
<211>20
<212>dna
<213>人工序列
<400>42
ggaaagaatgcgtcggtaaa20
<210>43
<211>20
<212>dna
<213>人工序列
<400>43
gggagtttgagaaggcatca20
<210>44
<211>20
<212>dna
<213>人工序列
<400>44
ctttcgtgttcgatgcgata20
<210>45
<211>20
<212>dna
<213>人工序列
<400>45
gatgagagcgcaggaaaaac20
<210>46
<211>20
<212>dna
<213>人工序列
<400>46
tcatcattttcagtggcgaa20
<210>47
<211>20
<212>dna
<213>人工序列
<400>47
agctgcatcatagcacctca20
<210>48
<211>20
<212>dna
<213>人工序列
<400>48
gcttccccacatgttctgtt20
<210>49
<211>20
<212>dna
<213>人工序列
<400>49
gaattggaattggcatgctt20
<210>50
<211>20
<212>dna
<213>人工序列
<400>50
tgagtgtcccaaggggttta20
<210>51
<211>20
<212>dna
<213>人工序列
<400>51
ctcggccacataaaccctta20
<210>52
<211>20
<212>dna
<213>人工序列
<400>52
cttgtggtgggatacccttg20
<210>53
<211>20
<212>dna
<213>人工序列
<400>53
tacacgatggagcgagtcag20
<210>54
<211>20
<212>dna
<213>人工序列
<400>54
gatttgcagaagcagaaggc20
<210>55
<211>20
<212>dna
<213>人工序列
<400>55
tagaggaggcaggaggtcaa20
<210>56
<211>20
<212>dna
<213>人工序列
<400>56
atgcaatgaagccaacatca20
<210>57
<211>23
<212>dna
<213>人工序列
<400>57
ttcccaactgacctaggatatga23
<210>58
<211>20
<212>dna
<213>人工序列
<400>58
caatttgctcaagcgttcaa20
<210>59
<211>20
<212>dna
<213>人工序列
<400>59
ttcacaccataatgccgaaa20
<210>60
<211>20
<212>dna
<213>人工序列
<400>60
accccgcaatactcactcac20
<210>61
<211>20
<212>dna
<213>人工序列
<400>61
tggcattcaaagcaacaaag20
<210>62
<211>20
<212>dna
<213>人工序列
<400>62
gcatcagatatcaacggcct20
<210>63
<211>20
<212>dna
<213>人工序列
<400>63
taacctacaaaaccaccgcc20
<210>64
<211>20
<212>dna
<213>人工序列
<400>64
ttcacgttggttactgctgc20
<210>65
<211>20
<212>dna
<213>人工序列
<400>65
cagttcccttcgttgagtgc20
<210>66
<211>20
<212>dna
<213>人工序列
<400>66
attctgtccattccggtgaa20
<210>67
<211>20
<212>dna
<213>人工序列
<400>67
ccaaagaagcaaccaagctc20
<210>68
<211>20
<212>dna
<213>人工序列
<400>68
tatttggcctcacaccacaa20
<210>69
<211>20
<212>dna
<213>人工序列
<400>69
agcgggagaaaccttagagc20
<210>70
<211>20
<212>dna
<213>人工序列
<400>70
caatggcttccacctcttgt20
- 还没有人留言评论。精彩留言会获得点赞!