一种Hemi-M甲基化修饰引物及其应用的制作方法
本发明涉及分子生物学
技术领域:
,尤其涉及一种hemi-m甲基化修饰引物及其应用。
背景技术:
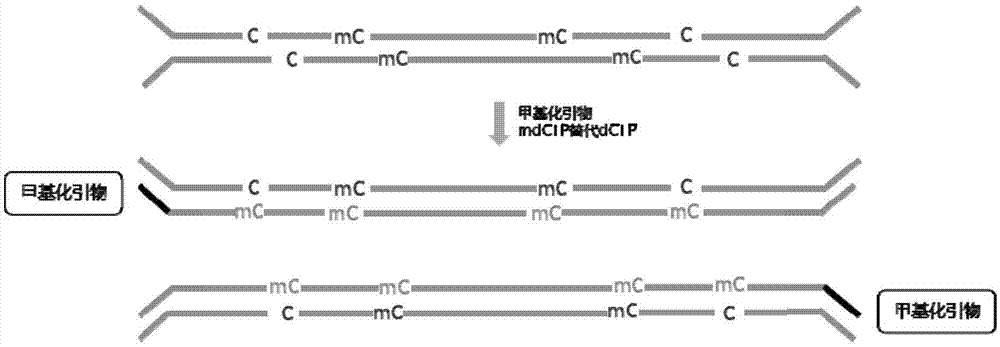
在表观遗传学中,甲基化是目前研究中相对较为深刻的。dna的甲基化水平可以决定一个或者一类基因的表达或者抑制,对于细胞功能正常与否有着重要作用,进而影响人类的生命进程。所以,甲基化研究是表观遗传学研究的热门领域之一。基因组dna水平的甲基化是在dna甲基转移酶的作用下,以硫腺苷甲硫氨酸作为甲基供体,将一个甲基添加到胞嘧啶5’-碳原子上,形成5-甲基胞嘧啶,原理如图1所示。cpg岛(cpgisland)是富含cpg二核苷酸的一些区域,长度为300—3000bp,cpg是胞嘧啶(c)—磷酸(p)—鸟嘌呤(g)的缩写,位于转录起始位点上游的启动子区域,看家基因的启动子cpg岛保持非甲基化状态,以保证看家基因的正常表达。组织特异性基因的cpg相对较少,并且在大多数组织中都处于甲基化状态。当启动子区域的cpg被甲基化时,转录受到抑制,该区域的cpg甲基化密度与转录抑制的程度有关。肿瘤组织中存在着基因组普遍低甲基化和局部区域过甲基化。抑癌基因启动子区域cpg岛过甲基化是许多肿瘤发生的早期重要事件,抑癌基因启动子区域cpg岛过甲基化可致使相关基因表达下调,甚至不表达,从而影响细胞内及细胞间正常生长凋亡。原癌基因的低甲基化,可以引起原癌基因的转录激活,同时也能影响临近基因的正常表达。dna的去甲基化破坏基因组印记,增加了患癌风险。目前的甲基化研究方法中,主要包含:甲基化特异性pcr、重亚硫酸盐测序法、高分辨率溶解曲线法、基因组直接测序法等。最常用的方法是重亚硫酸盐的方法。该方法中,在重亚硫酸盐的作用下,dna中未被甲基化修饰的胞嘧啶(c)转化为尿嘧啶(u),通过高通量测序检测出未被转化的胞嘧啶(c),即为被甲基化修饰。cn105002567a提供了一种无参考基因组高通量简化甲基化测序文库的构建方法,对样品基因组酶切和加a,获得5’末端具有磷酸化修饰和3’粘性末端a的dna片段,将其与含有不同条形码序列的甲基化接头相连;连接产物分为两组,一组进行pcr扩增,另一组经重亚硫酸盐转化后再扩增,获得两组含有相同条形码、仅在无甲基化的胞嘧啶位点不同的扩增产物序列;两组pcr产物分别混合,选择相同的特定长度片段序列进行低循环pcr,扩增产物分别分离纯化构建高通量简化甲基化测序文库。该方法通量高、成本低、序列一致,无需参考基因组,在大量无参考基因组或参考基因组组装不全物种的dna甲基化表观遗传学研究领域应用前景广阔。cn104532360a提供了一种全基因组甲基化测序文库及其构建方法。该构建方法包括以下步骤:s1,对全基因组dna进行片段化,得到dna片段;s2,采用由datp、dttp和dgtp混合形成的dntp对dna片段进行末端修复,得到修复片段;s3,对修复片段进行3’末端加“a”,得到3’末端带“a”片段;s4,采用经过“c”到“t”转化处理的接头序列对3’末端带“a”片段进行接头连接,得到带接头片段;s5,对带接头片段进行“c”到“t”转化处理,得到处理片段;s6,对处理片段进行扩增,得到全基因组甲基化测序文库,通过采用不含dctp的dntp进行末端修复,避免了非甲基化c的引入,提高了甲基化程度分析的准确性。但是,目前的研究中,只能将序列比对到基因组上,才能得知甲基化位点。还没有一种方法可以是自身作为对照进行甲基化位点定位分析。因此,提供一种甲基化修饰引物并用于以自身为对照进行甲基化位点分析,具有广阔的应用前景和巨大的市场价值。技术实现要素:针对现有技术的不足及实际的需求,本发明提供一种hemi-m甲基化修饰引物及其应用,本发明通过设计特异性的甲基化修饰引物,巧妙地与dctp被mdctp替代的dntp相结合,对样本dna进行胞嘧啶保护,创造性地将其应用于甲基化文库的构建,辅佐以特定的标签,适用于多种应用领域和场景,从而解决文库dna自身对比分析的问题,实现更准确的甲基化位点分析,具备广阔的应用前景和巨大的市场价值。为达此目的,本发明采用以下技术方案:第一方面,本发明提供一种hemi-m甲基化修饰引物,所述引物至少含有一个被甲基化修饰的胞嘧啶;其中,所述甲基化修饰包括:甲基化、羟甲基化等不能够被重亚硫酸盐处理转化为尿嘧啶(u)的修饰。所述hemi-m为甲基化hemi-methylation的缩写。在本发明中,发明人通过深入研究甲基化在表观遗传学中的作用,广泛探究甲基化研究方法的优缺点,发现甲基化检测的常用方中法,只能将序列比对到基因组上,才能得知甲基化位点,还没有一种方法可以是自身作为对照进行甲基化位点定位分析,因此结合甲基化反应的特性与测序文库的要求,通过大量创造性实验,最终摸索设计得到了一种甲基化修饰引物,能够应用于甲基化检测领域,对dna链中的胞嘧啶(c)进行甲基化保护,产生一条链正常,另一条链胞嘧啶(c)全部被甲基化胞嘧啶(mdc)代替,从而解决文库dna自身对比分析的问题,更好的定位甲基化位点。第二方面,本发明提供一种pcr方法,所述方法为:采用如第一方面所述的甲基化修饰引物进行pcr扩增反应,对样本dna链进行胞嘧啶保护,其中,所述pcr扩增的dntp中的dctp被mdctp替代。优选地,所述pcr扩增的反应循环数为1-3个循环,例如可以是1个、2个或3个循环。具体地,所述方法为:将如第一方面所述的甲基化修饰引物与dntp(含甲基化的mdctp,不含未甲基化的dctp)进行甲基化文库构建的ct转化步骤前的扩增反应,对dna互补链进行胞嘧啶保护。第三方面,本发明提供一种甲基化文库的构建方法,所述方法包括如下步骤:(1)将dna样品进行末端修复,3’端加a,甲基化接头连接;(2)将步骤(1)处理后的产物采用第一方面所述的甲基化修饰引物进行胞嘧啶保护;(3)将步骤(2)处理后的产物进行重亚硫酸盐处理;(4)将步骤(3)处理后的产物进行扩增添加索引序列,得到所述甲基化文库。优选地,若步骤(1)所述的dna样品为gdna,所述方法还包括对dna样品进行片段化处理的步骤。本发明中,若步骤(1)所述的dna样品为cfdna,则可以直接用于步骤(1)。优选地,所述步骤(1)之前还包括引入标签的步骤。优选地,所述标签的结构为反向互补,正链3’端突出,5’端未被磷酸化,负链5’端被磷酸化。优选地,所述3’端突出为悬突胸腺嘧啶。优选地,所述标签含有鸟嘌呤和胞嘧啶,且与第一方面所述的甲基化修饰引物结合于同一条dna链上,且标签序列的所有胞嘧啶全部被甲基化修饰。优选地,引入所述标签的方法为:将所述标签引入到dna片段两端。优选地,所述标签为一条oligo退火形成的茎环结构,且3’端突出,5’端磷酸化。优选地,所述标签为两条oligo退火形成两端或一端互补配对,且3’端突出,5’端磷酸化。本发明中,所述标签存在三种情况,当一条链退火形成茎环结构;第二种情况:当两条链发生两端互补配对时形成结构;第三种情况:当两条链发生一端互补配对形成结构,三种情况示意图如图5。优选地,引入所述标签的方法为:将所述标签引入到dna片段两端,经过处理后形成5’端突出,延伸后形成两端为平末端带标签的dna片段。本发明中,步骤(4)所述索引序列与甲基化标签不同,用于区分不同的样本;因为不同的样本混合后共同检测,需要此索引序列区分不同的样本,是构建二代测序文库时均需添加的序列。第四方面,本发明提供一种试剂盒,所述试剂盒包含第一方面所述的甲基化修饰引物。第五方面,本发明提供一种如第一方面所述的甲基化修饰引物和/或如第四方面所述的试剂盒用于制备检测癌症的药物和/或试剂。与现有技术相比,本发明具有如下有益效果:本发明提供的甲基化修饰引物,通过与dctp被mdctp替代的dntp相结合,对样本dna进行胞嘧啶保护,应用于甲基化文库的构建,辅佐以特定的标签,适用于多种应用领域和场景,从而解决文库dna自身对比分析的问题,实现更准确的甲基化位点分析,减少将测序结果比对回基因组序列的复杂过程,具备广阔的应用前景和巨大的市场价值。附图说明图1为本发明中基因组dna甲基化的原理图;图2为本发明中随机标签(barcode1)引入dna片段两端的示意图;图3为本发明中利用甲基化修饰引物进行胞嘧啶保护的示意图;图4为本发明中的随机标签(barcode2)引入dna片段两端的示意图;图5为本发明中的引入标签的三种情况示意图。具体实施方式为更进一步阐述本发明所采取的技术手段及其效果,以下结合附图并通过具体实施方式来进一步说明本发明的技术方案,但本发明并非局限在实施例范围内。实施例中,相关术语解释:(1)甲基化标签:反向互补双链结构,正链的5’端磷酸修饰(p○);当两条链退火后,负链在3’端悬突胸腺嘧啶。(2)甲基化修饰引物:引物序列中,胞嘧啶被甲基化处理为5-甲基胞嘧啶(5-mdc)。(3)mdc:无特殊说明,mdc指5-甲基胞嘧啶。(4)barcode:随机标签。(5)甲基化引物:引物序列中,所有的胞嘧啶被甲基化修饰。(6)纯化:如无特殊标注,实施例中的“纯化”指的是磁珠纯化。(7)退火:两条全部或部分反向互补的dnaoligo在一定反应条件下,结合为双链dna。(8)加a:在dna片段3’末端加上一个腺嘌呤碱基。实施例1(1)一种甲基化修饰引物,所述引物序列如seqidno.1所示:所述seqidno.1如下:引物1:5’ga/mdc/tggagtt/mdc/aga/mdc/gtgtg3’所述引物修饰方法如下:上述甲基化引物序列中,所有胞嘧啶(c)在合成时全部被修饰为5-甲基胞嘧啶(mdc)。(2)样本处理:若被处理样本为gdna,利用neb公司的片段化酶将2μg样本gdna片段化处理,通过磁珠或者切胶的方法选择100-250bp的dna片段,片段化酶处理条件:37℃,43min,将片段选择后的dna用30μl去离子水溶解;若被处理样本为cfdna,可以直接用于后续实验过程。(3)利用试剂盒neb文库准备试剂盒进行dna末端修复,3’端加a,甲基化接头连接。(4)胞嘧啶(c)保护:将甲基化接头连接后的纯化产物按表1所示体系进行反应:表1pcr循环条件如表2:表2温度/℃时间9545s6130s685min4保持(5)对上述产物进行纯化,纯化后按照zymodna重亚硫酸盐转化试剂盒进行重亚硫酸盐处理、纯化。(6)终文库扩增加索引序列:将上述纯化产物按表3所示体系进行反应:表3pcr循环条件如表4所示,:95℃-30s,[95℃-15s,61℃-30s,68℃-30s]15-18个循环,68℃-5min,4℃-保持。表4(7)对上述产物进行纯化,-20℃保存。实施例2(1)一种甲基化标签,所述甲基化标签正链与负链的核苷酸序列如seqidno.2和seqidno.3所示:seqidno.2即barcodef:5’nnnnnnnntgaat3’seqidno.3即barcoder:5’-tt/mdc/annnnnnnn3’其中,barcodef与barcoder反向互补,barcoder的5’端磷酸修饰当两条链退火后,barcodef在3’端悬胸腺嘧啶,5’端不进行磷酸化处理。将barcodef与barcoder退火为标签barcode1,barcode1为双链oligo,每条链的序列即seqidno.2和no.3相同,只是两条链互补形成双链结构。(2)一种甲基化修饰引物,所述引物序列如下:seqidno.1即primer1:5’ga/mdc/tggagtt/mdc/aga/mdc/gtgtg3’所述引物修饰方法如下:上述甲基化引物序列中,所有胞嘧啶在合成时全部被修饰为5-甲基胞嘧啶(mdc)。(3)样本处理:若被处理样本为gdna,利用neb公司的片段化酶将2μg样本gdna片段化处理,通过磁珠或者切胶的方法选择100-250bp的dna片段,片段化酶处理条件:37℃,43min。将片段选择后的dna用30μl去离子水溶解;若被处理样本为cfdna,可以直接用于后续实验过程。(4)片段化dna末端修复,3’端加a:利用试剂盒neb文库准备试剂盒进行dna末端修复,3’端加a。(5)标签barcode1连接:上述产物不需经过纯化,按表5所示体系进行反应,示意图如图2所示:表5组分体积μl上一步处理后的dna60barcode12.5连接混合体系30连接提高剂1共计93.5(6)将上述产物进行纯化,利用试剂盒neb文库准备试剂盒进行dna末端修复,3’端加a,甲基化接头连接。(7)胞嘧啶保护:将甲基化接头连接后的纯化产物按表6所示体系进行反应,示意图如图3所示:表6组分体积μl甲基化接头连接的dna30引物12.5dntp(mdctp替代dctp)(10mm)15×epimark热启动taq酶反应缓冲液10epimark热启动taq酶(2units/μl)0.25ddh2o加至50pcr循环条件如表7所示:表7温度/℃时间9545s6130s685min4保持(8)对上述产物进行纯化,纯化后按照zymodna重亚硫酸盐转化试剂盒进行重亚硫酸盐处理、纯化。(9)终文库扩增加索引序列:将上述纯化产物按表8所示体系进行反应:表8pcr循环条件如表9所示:表9(10)对上述产物进行纯化,-20℃保存。实施例3(1)一种标签,所述标签的核苷酸序列如seqidno.4所示:seqidno.4即oligo:5’-catag/du/nnnnnnnnctatgt3’oligo的5’端磷酸化修饰,且5’端五个碱基与3’端反向互补,退火后形成茎环结构,且3’端悬突胸腺嘧啶的标签barcode2,,所示barcode2的核苷酸序列序列即seqidno.4,只是退火后自身互补形成茎环结构:(2)一种甲基化修饰引物,所述引物序列如下:seqidno.1即primer1:5’ga/mdc/tggagtt/mdc/aga/mdc/gtgtg3’所述引物修饰方法如下:上述甲基化引物序列中,所有胞嘧啶(c)在合成时全部被修饰为5-甲基胞嘧啶(mdc)。(3)样本处理:若被处理样本为gdna,利用neb公司的片段化酶将2μg样本gdna片段化处理,通过磁珠或者切胶的方法选择100-250bp的dna片段,片段化酶处理条件:37℃,43min。将片段选择后的dna用30μl去离子水溶解;若被处理样本为cfdna,可以直接用于后续实验过程。(4)片段化dna末端修复,3’端加a:利用试剂盒neb文库准备试剂盒进行dna末端修复,3’端加a。(5)标签barcode2连接:上述产物不需经过纯化,按表10所示体系进行反应,示意图如图4所示:表10组分体积μl上一步处理后的dna60barcode22.5连接混合体系30连接提高剂1共计93.5(6)在上述产物中加入3μl的user酶和3μl的虾碱性磷酸酶(rsap),37℃反应30min。(7)标签延伸:将上述产物纯化后按表11所示体系进行反应:表11组分体积μlbarcode2连接的dna30dntp(mdctp替代dctp)(10mm)15×epimark热启动taq酶反应缓冲液10epimark热启动taq酶(2units/μl)0.25ddh2o加至50pcr循环条件:95℃-45s,61℃-30s,68℃-5min,4℃-保持。(8)对上述产物进行纯化,利用试剂盒neb文库准备试剂盒进行dna末端修复,3’端加a,甲基化接头连接。胞嘧啶保护:将甲基化接头连接后的纯化产物按表12所示体系进行反应:表12组分体积μl甲基化接头连接的dna30引物12.5dntp(mdctp替代dctp)(10mm)15×epimark热启动taq酶反应缓冲液10epimark热启动taq酶(2units/μl)0.25ddh2o加至50pcr循环条件如表13所示:表13温度/℃时间9545s6130s685min4保持(9)对上述产物进行纯化,纯化后按照zymodna重亚硫酸盐转化试剂盒进行重亚硫酸盐处理、纯化。(10)终文库扩增加索引序列:将上述纯化产物按表14所示体系进行反应:表14组分体系μl修改后dna30nebnext通用pcr引物2.5nebnext索引(x)引物2.5dntp(10mm)15×epimark热启动taq酶反应缓冲液10epimark热启动taq酶(2units/μl)0.25ddh2o加至50pcr循环条件如表15所示:表15(11)对上述产物进行纯化,-20℃保存。综上所述,本发明提供的一种hemi-m甲基化修饰引物及其应用,所述引物至少含有一个被甲基化修饰的胞嘧啶,其中,所述甲基化修饰包括甲基化和/或羟甲基化修饰;本发明通过设计特异性的甲基化修饰引物,巧妙地与dctp被mdctp替代的dntp相结合,对样本dna进行胞嘧啶保护,创造性地将其应用于甲基化文库的构建,辅佐以特定的标签,适用于多种应用领域和场景,从而解决文库dna自身对比分析的问题,实现更准确的甲基化位点分析,减少将测序结果比对回基因组序列的复杂过程,具备广阔的应用前景和巨大的市场价值。申请人声明,本发明通过上述实施例来说明本发明的详细方法,但本发明并不局限于上述详细方法,即不意味着本发明必须依赖上述详细方法才能实施。所属
技术领域:
的技术人员应该明了,对本发明的任何改进,对本发明产品各原料的等效替换及辅助成分的添加、具体方式的选择等,均落在本发明的保护范围和公开范围之内。sequencelisting<110>深圳市海普洛斯生物科技有限公司<120>一种hemi-m甲基化修饰引物及其应用<130>2018年<160>4<170>patentinversion3.3<210>1<211>26<212>dna<213>人工合成<400>1gamdctggagttmdcagamdcgtgtg26<210>2<211>13<212>dna<213>人工合成<220><221>misc_feature<222>(1)..(8)<223>nisa,c,g,ort<400>2nnnnnnnntgaat13<210>3<211>14<212>dna<213>人工合成<220><221>misc_feature<222>(7)..(14)<223>nisa,c,g,ort<400>3ttmdcannnnnnnn14<210>4<211>21<212>dna<213>人工合成<220><221>misc_feature<222>(8)..(15)<223>nisa,c,g,toru<400>4catagdunnnnnnnnctatgt21当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1