一种基因调控网络的优化控制方法与流程
本发明涉及生物网络控制技术领域,尤其涉及一种基因调控网络的优化控制方法。
背景技术:
基因调控网络是一种重要的生物网络,其建模和分析对更深入地理解生物过程以及发展有效的治疗干预用于人类疾病具有极大的作用。目前,布尔网络和概率布尔网络已经被广泛地用于对基因调控网络进行建模。布尔网络(Boolean Network,BN)是kauffman在1969年提出的一种简单的逻辑动态系统,并作为一种重要的模型用于研究基因调控网络的动态行为。在布尔网络中,一些二进制值的结点和结点之间的交互规则构成了整个网络的拓扑结构。假设基因的状态被划分为两种:“0”和“1”,其中,“0”代表基因未被表达,“1”代表基因被表达,因此,布尔网络中每个结点代表一个基因的状态。结点之间交互的规则通过布尔函数进行表示。布尔网络可以表示成B=(G,F)。G={V,E}是一个有向图,其中V={x1,x2,x3,…xn}表示网络中结点的集合,E表示结点之间关联关系。每一个结点xi∈{0,1}代表基因i的布尔状态值。F={f1,f2,f3,…,fn}是一个布尔函数集合,表示所有相互关联的基因之间调控交互的规则,同时定义了网络的演变规则。
在布尔网络的基础上,通过添加布尔控制结点作为控制输入可以构造布尔控制网络(Boolean Control Network,BCN)。布尔控制网络是指带有输入和输出的布尔网络。输出用于表示期望的网络状态。添加布尔控制结点的目的是为了通过操控布尔控制结点的取值从而改变布尔网络的状态迁移,使网络按照期望的方式运行。
由于生物系统具有随机性质以及在复杂测量过程中存在实验噪声的影响导致用于推理网络结构的数据集合通常是不准确的。在2002年,Shmulevich提出了概率布尔网络(Probabilistic Boolean Network,PBN)。概率布尔网络是在布尔网络的基础上通过为每个基因提供多个布尔函数,用于处理来自数据和模型选择方面的不确定性。在每个时刻,每个基因按照给定的概率分布随机地从候选布尔函数集合中选择一个,构成当前网络的演变规则。概率布尔网络仍可表示B=(G,F)。与布尔网络相比,布尔函数向量F={F1,F2,F3...,Fn}中的每一个Fi={f1(i),f2(i),…,fl(i)(i)}代表一个由l(i)个布尔函数组成的集合。fj(i)表示基因i的第j个布尔函数。每一个fj(i):{0,1}k(i)→{0,1}实现一个状态的映射,决定基因i下一个时刻可能的状态。对于每一个fj(i),k(i)的值可能是不同的并且被选择的概率为Cj(i)。显然的是,Cj(i)需要满足归一性的条件。
当前,在通过基因调控网络获取最优的控制结果时,往往需要占用较多的内存,并且数据处理的时间也比较久。因此,当前亟需一种能够快速并且消耗较低内存的优化控制方法。
技术实现要素:
本发明的目的在于提供一种基因调控网络的优化控制方法,能够在占用较低内存的同时,提高获取最优的优化控制结果的效率。
为实现上述目的,本发明提供了一种基因调控网络的优化控制方法,所述方法包括:在概率模型检测器PRISM中对带有干扰的并且上下文相关的概率布尔网络进行建模,得到基于PRISM的概率布尔网络模型;利用所述PRISM中的reward结构对所述概率布尔网络的状态设置不同的状态回报值,所述状态回报值用于表征控制成本函数和终端成本;确定分别对有限范围和无限范围进行控制成本优化的第一时序逻辑公式和第二时序逻辑公式;将所述基于PRISM的概率布尔网络模型、所述不同的状态回报值以及所述第一时序逻辑公式和第二时序逻辑公式输入所述概率模型检测器PRISM中,得到最优的优化控制结果。
进一步地,在概率模型检测器PRISM中对带有干扰的并且上下文相关的概率布尔网络进行建模,得到基于PRISM的概率布尔网络模型具体包括:将所述概率布尔网络中的各个布尔函数转换为实数域上的多项式形式,所述概率布尔网络中包括多个普通结点和多个控制结点;获取预设马尔科夫决策过程,所述马尔科夫决策过程中包括转换概率、转换开关、干扰概率和干扰事件;分别对所述转换开关、所述干扰事件、所述普通结点以及所述控制结点进行建模,得到所述基于PRISM的概率布尔网络模型。
进一步地,对所述转换开关进行建模具体包括:设定所述转换开关的取值为0或者1,其中,所述转换概率的值可使得所述转换开关取值为1,下述公式可使得所述转换开关取值为0:
1-q
其中,q表示所述转换概率的值;
当所述转换开关取值为1时,所述概率布尔网络按照概率分布随机选择一个布尔网络作为网络的演变规则;当所述转换开关取值为0时,保持当前的布尔网络不变。
进一步地,对所述干扰事件进行建模具体包括:设定所述干扰事件的取值为0或者1,其中,所述转换概率的值可使得所述干扰事件取值为1,下述公式可使得所述干扰事件取值为0:
1-q
其中,q表示所述转换概率的值。
进一步地,所述第一时序逻辑公式为:
Rmin=?:[C<=T+1]
其中,所述第一时序逻辑公式表示有限范围对应的最小累计回报值,所述累计回报值为每个时刻的控制成本函数值以及终端成本的累加,Rmin表示操作符,C表示累计时间,T表示整数变量,?:表示条件运算符;
所述第二时序逻辑公式为:
Rmin=?:[F prop]
其中,所述第二时序逻辑公式表示无限范围对应的最小可达性回报值,F表示时序逻辑词,prop表示目标状态。
本发明可以将概率布尔网络的状态演变看作是一条离散时间的马尔科夫链。在概率布尔网络中可以选择一些结点作为控制结点,构成概率布尔控制网络。控制结点在每一个时刻可以非确定地选取一个二进制的值,概率布尔控制网络的状态迁移构成马尔科夫决策过程(MDP)。为了使用概率模型检测方法解决有限范围和无限范围两类优化控制问题,本申请需要将概率布尔控制网络的状态演变转换为一个相应的MDP模型。两类控制问题分别对应着有限范围马尔科夫决策过程和无限范围马尔科夫决策过程,然后使用对应的时序逻辑公式进行分析。在本申请中,根据优化控制问题的定义,使用reward结构对MDP模型扩展来指定状态回报值,用于表达控制成本函数和终端成本。最后,将基于PRISM的概率布尔网络模型、不同的状态回报值以及时序逻辑公式输入概率模型检测器PRISM中,从而能够得到最优的优化控制结果。不难看出,当将该方法应用到复杂的概率布尔网络优化控制问题中时,能够在占用较低内存的同时,提高获取最优的优化控制结果的效率。
附图说明
图1为本发明提供的一种基因调控网络的优化控制方法流程图;
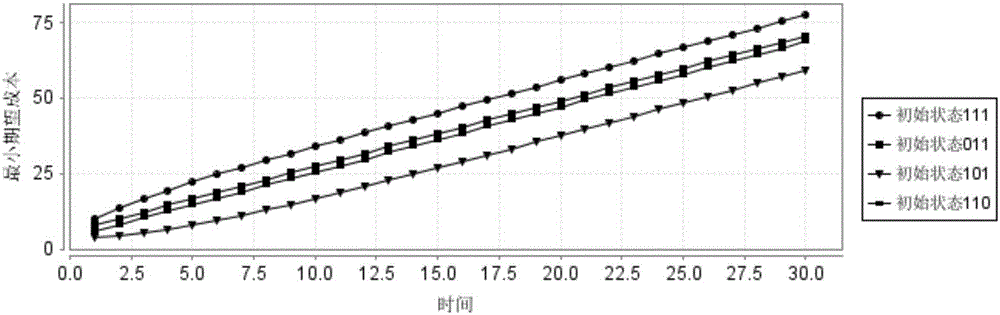
图2为本发明中控制节点初始值为0时有限范围对应的最小累计回报值的示意图;
图3为本发明中控制节点初始值为1时有限范围对应的最小累计回报值的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施方式中的附图,对本申请实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本申请一部分实施方式,而不是全部的实施方式。基于本申请中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施方式,都应当属于本申请保护的范围。
图1为本发明提供的一种基因调控网络的优化控制方法流程图。如图1所示,所述方法可以包括以下步骤。
步骤S1:在概率模型检测器PRISM中对带有干扰的并且上下文相关的概率布尔网络进行建模,得到基于PRISM的概率布尔网络模型。
在本实施方式中,可以将所述概率布尔网络中的各个布尔函数转换为实数域上的多项式形式,所述概率布尔网络中包括多个普通结点和多个控制结点。
针对两个布尔变量δ1,δ2,那么,如下关系成立:
1)等价于1-δ1;
2)δ1∨δ2等价于δ1+δ2-δ1δ2;
3)δ1∧δ2等价于δ1δ2。
在本实施方式中,可以将给定的系统描述成一个马尔科夫决策过程,从而能够获取预设马尔科夫决策过程,所述马尔科夫决策过程中包括转换概率q、转换开关s、干扰概率p和干扰事件peri。
在本实施方式中,可以分别对所述转换开关、所述干扰事件、所述普通结点以及所述控制结点进行建模,从而得到所述基于PRISM的概率布尔网络模型。
具体地,对转换开关s进行建模时,具体地执行代码可以如下所示:
1)module switch
2)s:[0..1]init 1;
3)[csPBN]c=0->q:(s'=1)+(1-q):(s'=0);
4)endmodule
其中,第2行代码表明:转换开关s可以取值0或者1,分别代表转换开关无效和有效,并赋初始值为1;第3行代码表明:转换开关s以q的概率变为1,以1-q的概率变为0。当s=1时,PBN按照概率分布随机地选择一个布尔网络作为网络的演变规则;当s=0时,保持当前的布尔网络不变。
在本实施方式中,对所述干扰事件进行建模的执行代码可以如下所示:
1)module perti
2)peri:[0..1]init 0;
3)[csPBN]c=0->p:(peri'=0)+(1-p):(peri'=1);
4)endmodule
其中,第2行代码表明:对任意干扰事件peri可以取值0或者1,分别代表干扰事件未发生和发生,并赋初始值为0;第3行的代码,表明干扰事件peri以p的概率变为0,以1-p的概率变为1。
在本实施方式中,对普通结点进行建模的代码可以如下所示:
1)module BNi
2)xi:[0..1]init 1;
3)di:[0..l(i)-1]init 0;
8)[csPBN]c=0&peri=1->(xi'=0);
9)[csPBN]c=0&peri=1->(xi'=1);
10)endmodule
其中,第2行代码表明,结点xi的值可以取0或者1,并赋初始值为1;第3行代码中的di,i=0,1,…,l(i)-1是整型常数,取值范围从0到l(i)-1,是对普通结点所选择的布尔函数的标记,赋初始值为0;第4行的代码表明,当转换开关打开且干扰事件未发生时,xi结点的值以的概率取决于并用di=0进行标记,加号后的情况与此类似;第5行到第7行的代码表明,当转换开关关闭且干扰事件未发生的时候,结点xi的值取决于上一时刻由di标记的布尔函数;第8行和第9行的代码表明,当干扰事件发生时,结点xi的值非确定地跳转到0和1。
在本实施方式中,对所述控制结点进行建模的代码可以如下所示:
1)module inputi
2)ui:[0..1]init 0;
3)[csPBN]c=0->(ui'=0);
4)[csPBN]c=0->(ui'=1);
5)endmodule
其中,第2行的代码表明:控制结点ui的取值为0或者1,并赋初始值为0;第3行到第4行的代码表明:每个时刻布尔控制结点ui的值可以非确定地取0和1。
步骤S2:利用所述PRISM中的reward结构对所述概率布尔网络的状态设置不同的状态回报值,所述状态回报值用于表征控制成本函数和终端成本。
在本实施方式中,为了求解优化控制问题,可以使用PRISM提供的reward结构对网络的状态设置不同的状态回报值,用于说明控制成本函数和终端成本。具体实现的代码可以如下所示:
1)rewards"reward_name"
2)guard:reward;
3)endrewards;
其中,“guard”是命令语句中的谓词公式,表明状态回报产生的条件,“reward”是一个实数值,表明状态回报值。回报项“guard:reward”的意思是对所有满足谓词公式guard的状态设置一个状态回报值reward。
步骤S3:确定分别对有限范围和无限范围进行控制成本优化的第一时序逻辑公式和第二时序逻辑公式。
在本实施方式中,对于解决有限范围的优化控制问题,可以用第一时序逻辑公式“Rmin=?:[C<=T+1]”表示对累积回报的计算,其中,所述第一时序逻辑公式表示有限范围对应的最小累计回报值,所述累计回报值为每个时刻的控制成本函数值以及终端成本的累加,Rmin表示操作符,C表示累计时间,T表示整数变量,?:表示条件运算符。该公式的目的是为了得到在T时间范围内,在控制输入序列的作用下,网络演变所产生的优化控制成本。公式中使用“T+1”而不是“T”的原因是模型检测算法对累积回报的计算过程中,不包含对终端时刻状态回报的累加。根据累计回报计算过程的定义,计算结果是结合迁移概率,对每个时刻状态回报值和每个状态迁移回报值进行累加。然而,由于在本申请中仅仅指定了状态回报值用于表示控制成本函数和终端成本,因此,公式“Rmin=?:[C<=T+1]”的计算过程意味着是对每个时刻的控制成本函数值以及终端成本的累加。操作符“Rmin”是用于在MDP模型上从所有不同组合的action序列中计算出最小的累计回报,即有限范围优化控制成本。
在本实施方式中,对于解决无限范围的优化控制问题,可以使用第二时序逻辑公式“Rmin=?:[F prop]”表示对可达性回报的计算,其中,所述第二时序逻辑公式表示无限范围对应的最小可达性回报值,F表示时序逻辑词,prop表示目标状态。该公式的目的是为了得到从初始状态出发,在控制输入序列的作用下,沿着每一条可执行的路径,当到达目标状态prop时,网络演变所产生的优化控制成本。根据可达性回报计算过程的定义,计算结果是结合迁移概率,对每个时刻状态回报值和每个状态迁移回报值进行累加,直到到达满足prop的状态。同样,由于本申请仅仅指定了状态回报值用于表示控制成本函数和终端成本,因此,公式“Rmin=?:[F prop]”的计算过程意味着是在网络到达目标状态之前,对每个时刻的控制成本函数值的累加。操作符“Rmin”是用于在MDP模型上从所有不同组合的action序列中计算出最小的可达性回报,即无限范围优化控制成本。
步骤S4:将所述基于PRISM的概率布尔网络模型、所述不同的状态回报值以及所述第一时序逻辑公式和第二时序逻辑公式输入所述概率模型检测器PRISM中,得到最优的优化控制结果。
在本实施方式中,将所述基于PRISM的概率布尔网络模型、所述不同的状态回报值以及所述第一时序逻辑公式和第二时序逻辑公式输入所述概率模型检测器PRISM中,可以通过概率模型检测算法进行自动地求解,从而可以得到最优的优化控制结果。
在具体应用场景中,以细胞凋亡网络作为优化控制问题的研究对象,在本实施方式中,可以将如下布尔网络转化为概率布尔控制网络:
X3(t+1)=X4(t)∨X2(t)
X4(t+1)=X4(t)
在上述公式中,X1代表IAP的浓度水平,X2代表C3a的浓度水平,X3代表C8a的浓度水平,X4代表TNF的浓度水平。Xi=1表示高浓度水平,Xi=0表示低浓度水平。在以上布尔网络中,可以选取X4作为布尔控制结点u。另外,可以采用同步更新和异步更新相结合方式对其动态性进行概率扩展,构建出概率布尔控制网络。设置所有结点的候选布尔函数被选择概率为0.5,得到以下动态方程:
在本申请中,可以将如上所示的每个布尔函数转换成实数域上的多项式形式,得到的布尔函数表达式为:f11,f12,f21,f22,f31,f32。
考虑两个布尔变量δ1,δ2,那么,如下关系成立:
1)等价于1-δ1
2)δ1∨δ2等价于δ1+δ2-δ1δ2
3)δ1∧δ2等价于δ1δ2
将上述动态方程进行转换的结果为:
X1(t+1)=X1(t)~f f12=x1;
X2(t+1)=X2(t)~f22=x2;
X3(t+1)=u(t)∨X2(t)~f31=u+x2-u*x2;
X3(t+1)=X3(t)~f32=x3
接着,可以将构造出的概率布尔控制网络模型描述成一个马尔科夫决策过程,为了考虑网络的稳定性和外界随机干扰的影响,给出转换概率q,转换开关s,干扰概率p,干扰事件peri。
然后,可以对转换开关s进行建模,具体实施方式如下:
1)module switch
2)s:[0..1]init 1;
3)[csPBN]c=0->0.3:(s'=1)+0.7:(s'=0);
4)endmodule
第2行代码说明转换开关s可以取二进制的值。第3行命令语句表明设定转换概率q=0.3。
然后,可以对干扰事件进行建模,具体实施方式如下:
1)module pert1
2)per1:[0..1]init 0;
3)[csPBN]c=0->0.9:(per1'=0)+0.1:(per1'=1);
4)endmodule
第2行代码说明干扰变量per1可以取二进制值。第3行命令语句表明设定干扰概率p=0.1。
然后,可以对模型中的结点x1进行建模,其中,f11,f12是模型中结点x1对应的候选布尔函数,每个候选布尔函数被选择的概率为0.5。具体实施方式如下:
1)module BN1
2)x1:[0..1]init 1;
3)d1:[0..1]init 0;
4)[csPBN]c=0&s=1&per1=0->0.5:(x1'=f11)&(d1'=0)+0.5:(x1'=f12)&(d1'=1);
5)[csPBN]c=0&s=0&per1=0&d1=0->(x1'=f11);
6)[csPBN]c=0&s=0&per1=0&d1=1->(x1'=f12);
7)[csPBN]c=0&per1=1->(x1'=0);
8)[csPBN]c=0&per1=1->(x1'=1);
9)endmodule
第4行的代码表明,当转换开关打开且干扰事件未发生时,x1结点的值以0.5的概率取决于f11并用d1=0进行标记,加号后的情况与此类似;第5行到第6行的代码表明,当转换开关关闭且干扰事件未发生的时候,结点x1的值取决于上一时刻由d1标记的布尔函数;第7行和第8行代码说明当干扰事件发生(per1=1)时,布尔结点x1下一个时刻的值非确定地变为1或0。
然后,可以对模型中的控制结点u进行建模,具体实施方式如下:
1)module input
2)u:[0..1]init 0;
3)[csPBN]c=0->(u'=0);
4)[csPBN]c=0->(u'=1);
5)endmodule
第3行到第4行的代码表明:每个时刻布尔控制结点u的值可以非确定地取0和1。
接着,为了求解优化控制问题,可以使用PRISM提供的reward结构对网络的状态设置不同的状态回报值,用于说明控制成本函数和终端成本。具体实施方式如下:
1)rewards"cost"
2)x1=0&x2=0&x3=0&u=0:0;
3)x1=0&x2=0&x3=0&u=1:1;
4)x1+x2+x3=1&u=0:2;
5)x1+x2+x3=1&u=1:3;
6)x1+x2+x3=2&u=0:4;
7)x1+x2+x3=2&u=1:5;
8)x1=1&x2=1&x3=1&u=0:6;
9)x1=1&x2=1&x3=1&u=1:7;
10)endrewards
在以上PRISM代码中,可以对网络所有状态设置了不同的状态回报值。网络状态的变化范围从[0,0,0]到[1,1,1]。第2行到第9行的代码说明了当网络处于所有不同的状态时,布尔控制结点u=0和u=1分别所对应的控制成本函数值。同时,第2、4、6和8行的代码也说明了所有不同状态的终端成本。在实际中,状态回报值必须要能够捕捉到干预的成本以及对不同状态的相对偏好。
然后,可以使用概率计算树逻辑(PCTL)公式分别表示对有限范围和无限范围优化控制成本的计算,具体包括:
使用概率计算树时序逻辑公式R{“cost”}min=?[C<=T+1]表示有限范围内的优化控制成本。在有限范围的优化控制中,T为一个整数变量,C代表累计时间。设定T变化范围从1到30以及增加的步长为1。
使用概率计算树时序逻辑公式R{“cost”}min=?[F x1=0&x2=0&x3=0]表示无限范围内的优化控制成本。在无限范围的优化控制中,我们指定网络的目标状态是[0,0,0]。除此以外,我们还设定网络分别从四种不同的初始状态以及布尔控制结点不同的初始值出发,探讨这些因素对于计算两类优化控制成本的影响。
最后,可以将带有干扰且上下文相关的概率布尔控制网络基于PRISM的模型、描述控制成本和终端成本的reward结构的PRISM建模代码以及表示有限范围内的优化控制成本的时序逻辑公式R{“cost”}min=?[C<=T+1]和表示无限范围内的优化控制成本的时序逻辑公式R{“cost”}min=?[F x1=0&x2=0&x3=0]输入到概率模型检测器PRISM中,通过概率模型检测算法进行自动地求解。
在本实施方式中,采用第二时序逻辑公式求取的无限范围对应的最小可达性回报值可以如表1所示。
表1采用第二时序逻辑公式求取的无限范围对应的最小可达性回报值
从表1中可以看出,通过本申请提供的基因调控网络的优化控制方法进行计算时,耗费的时间较少并且消耗的内存也较少,从而能够在占用较低内存的同时,提高获取最优的优化控制结果的效率。
请参阅图2和图3,图2和图3例示了在不同的控制节点初始值的情况下分别对应的有限范围的最小累计回报值的示意图。图2中布尔控制节点初始值为0,图3中布尔控制节点初始值为1。图2和图3中均例示了最小期望成本/回报随时间变化的关系,从图2和图3中可以看出,随着时间的增加,最小期望成本/回报也在增加,并且不同的初始状态在相同时间点处对应的最小期望成本/回报也不同。
由上可见,本发明可以将概率布尔网络的状态演变看作是一条离散时间的马尔科夫链。在概率布尔网络中可以选择一些结点作为控制结点,构成概率布尔控制网络。控制结点在每一个时刻可以非确定地选取一个二进制的值,概率布尔控制网络的状态迁移构成马尔科夫决策过程(MDP)。为了使用概率模型检测方法解决有限范围和无限范围两类优化控制问题,本申请需要将概率布尔控制网络的状态演变转换为一个相应的MDP模型。两类控制问题分别对应着有限范围马尔科夫决策过程和无限范围马尔科夫决策过程,然后使用对应的时序逻辑公式进行分析。在本申请中,根据优化控制问题的定义,使用reward结构对MDP模型扩展来指定状态回报值,用于表达控制成本函数和终端成本。最后,将基于PRISM的概率布尔网络模型、不同的状态回报值以及时序逻辑公式输入概率模型检测器PRISM中,从而能够得到最优的优化控制结果。不难看出,当将该方法应用到复杂的概率布尔网络优化控制问题中时,能够在占用较低内存的同时,提高获取最优的优化控制结果的效率。
上面对本申请的各种实施方式的描述以描述的目的提供给本领域技术人员。其不旨在是穷举的、或者不旨在将本发明限制于单个公开的实施方式。如上所述,本申请的各种替代和变化对于上述技术所属领域技术人员而言将是显而易见的。因此,虽然已经具体讨论了一些另选的实施方式,但是其它实施方式将是显而易见的,或者本领域技术人员相对容易得出。本申请旨在包括在此已经讨论过的本发明的所有替代、修改、和变化,以及落在上述申请的精神和范围内的其它实施方式。
本说明书中的各个实施方式均采用递进的方式描述,各个实施方式之间相同相似的部分互相参见即可,每个实施方式重点说明的都是与其他实施方式的不同之处。
虽然通过实施方式描绘了本申请,本领域普通技术人员知道,本申请有许多变形和变化而不脱离本申请的精神,希望所附的权利要求包括这些变形和变化而不脱离本申请的精神。
- 还没有人留言评论。精彩留言会获得点赞!
- 拟南芥SSCD1基因突变在调控植物体内茉莉酸合成中的应用的制作方法与工艺
- 一种基因调控网络的优化控制方法与流程
- 拟南芥WRKY家族转录因子AtWRKY44基因,蛋白编码序列及其应用的制作方法与工艺
- 针对免疫调控能力相关基因个体化配方食品及其制备方法与流程
- REVOLUTA基因在调控豆科植物小叶片数目和叶茎比中的应用的制作方法与工艺
- 玉米锌铁调控转运体ZmZIP3基因及其应用的制作方法与工艺
- 拟南芥基因SPOC1在调控植株开花期中的应用的制作方法与工艺
- 调控石榴花胚珠发育的PgAG基因及其用途的制作方法与工艺
- 光效调控基因HPE1及其应用的制作方法与工艺
- 菘蓝IiAP2/ERF049基因在调控木脂素类化合物合成中的应用的制作方法与工艺