增强和/或预测DNA扩增的组合物和方法与流程
本申请要求享有2014年4月22日提交的美国临时申请第61/982,784号的优先权和权益,该临时申请通过引用全部并入本文。
背景技术:
虽然核酸扩增方法常见并且众所周知,但是,很大程度上归因于存在涉及引物设计的困难,核酸扩增反应仍旧受不可预测性和/或不良性质的影响。核酸扩增的不可预测性很大程度上归因于缺少针对引物和探针的序列-可预测性设计参数,这些引物和探针实现了对目标-特定引物进行定量评估并且检测对抗脱靶连接的杂合作用、自身/自身和自身/非-自身二聚作用。实际上,挑选潜在引物序列的可变性和目标核酸序列施加的序列约束性使得经验性和系统性考查引物组合的外观及其效果变得困难。
基于PCR试验的设计参数集中于引物和探针融化温度,GC(鸟嘌呤和胞嘧啶)含量,引物长度以及最小化引物和目标核酸之外所有核酸的相互作用(参见,例如www.premierbiosoft.com/tech_notes/PCR_Primer_Design.html)。特别地,非常不鼓励使用可和自身分子间相互作用的引物(例如引物-二聚体),因为这样的引物会不合需要地影响引物和目标核酸分子的相互作用。另外,建议核酸引物的最佳长度是18到22个核苷酸,这个长度认为足够长因而具有足够特异性并且足够短以使在退火温度下引物可轻易和模板链接。对于GC含量,推荐GC含量为40%到60%。错误的是,普通试验设计实践假定当所有上述参数为扩增试验的正向和反向引物而同等设计时,也会证明这两种引物杂交作用的动力学是相似的。这些常用的设计参数没有一个充分和两阶段寡核苷酸杂交作用的复杂热力学相关,它们涉及焓、熵、溶剂化作用、最临近效应以及从单链到双链杂合阶段转换中的氢键结合的变化。而且,即使寡核苷酸杂合作用的两个阶段模型作为热力学算法基础的用途都被过度简化并且没有正确反映实际情况。因此,满足所有推荐标准的引物的性质依然不可预测。
确定一组引物于基本等温的条件下可预测性地扩增目标核酸的效力的进展有减少资源消耗的潜力,包括合成和经验性地检测大量引物组的精力、时间和费用(例如设计多种引物和成对地筛选多种引物组合)。需要新的参数和方法以增强和更好预测核酸扩增反应的性能和产率。
技术实现要素:
如本文所描述的,本发明提供了用以设计能预测性地扩增目标核酸分子的引物的改良方法以及用这些引物进行核酸扩增的方法,包括增强扩增目标核酸分子和/或减少或降低生成隐蔽产物。进一步地,本发明提供了用以扩增和检测试样目标寡核苷酸的组合物和方法。在具体实施例中,本发明的组合物和方法与等温核酸扩增反应相容。
本发明的一个方面提供了一种从5’到3’包括第一区和第二区的分离的引物寡核苷酸,所述第一区具有自身-互补序列(从5’到3’包括切口酶识别序列的反向互补序列),回文序列以及所述切口酶识别序列,所述第二区的长度是至少16个核苷酸并且特异性结合至目标核酸分子上的互补区以形成双链杂合体(具有比涉及第二区或与第二区互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG),其中所述第二区于3’末端上具有一个或多个2’修饰的核苷酸。
本发明的另一方面提供了一种包括两种寡核苷酸单体的分离的引物-二聚体,所述两种寡核苷酸单体从5’到3’包含第一区和第二区,所述第一区具有自身-互补序列(从5’到3’包括切口酶识别序列的反向互补序列)、回文序列以及切口酶识别序列,所述第二区的长度是16个核苷酸并且特异性结合至目标核酸分子上的互补区以形成双链杂合体(具有比涉及所述第二区或和所述第二区相互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG),其中所述第二区在3’末端具有一个或多个2’修饰的核苷酸。
本发明的另一方面提供了用来检测目标核酸分子的分离的寡核苷酸探针,包括:寡核苷酸;荧光报道物;能从荧光报道物吸收激发能的淬灭分子;其中荧光报道物和淬灭分子共价地附接于和寡核苷酸相对的5’端和3’端,其中寡核苷酸包括第一区(具有大致互补于目标核酸序列的核酸序列)和第一区上游的第二区5’端以及第一区下游的第三区3’端(具有互补于所述第二区的核酸序列),其中当寡核苷酸未结合至目标核酸分子时,寡核苷酸能通过将第二区和第三区杂合作用形成茎环发夹结构,其中寡核苷酸探针的目标序列和第一序列之间的双链杂合体的ΔG比涉及寡核苷酸探针或和寡核苷酸探针相互作用的任意交替结构的ΔG低至少15kcal/mol。
本发明的另一个方面提供了在切割和扩展扩增反应中扩增特定产物的方法,该方法包括:在大致等温条件下,将目标核酸分子和聚合酶、两个或更多引物(每一个在目标核酸分子上都特异性地连接于互补序列)、切口酶以及可检测的多核苷酸探针接触,其中至少一个引物从5’到3’包括第一区和第二区,所述第一区具有自身-互补序列(从5’到3’包括切口酶识别序列的反向互补序列、回文序列和所述切口酶识别序列),所述第二区的长度是16个核苷酸并且特异性结合至目标核酸分子上的互补区以形成双链杂合体(具有比涉及第二区或和第二区相互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG,其中第二区在3’末端具有一个或多个2’修饰的核苷酸);以及生成包含至少一部分目标核酸分子的扩增子。
本发明的另一方面提供了在切割和扩展扩增反应中检测特定产物的方法,该方法包括:在大致等温条件下,将目标核酸分子与聚合酶、两个或更多引物(每一个在目标核酸分子上特异性地连接于互补序列)、切口酶以及可检测的多核苷酸探针接触,其中至少一个引物从5’到3’包括第一区和第二区,所述第一区包括自身-互补序列(从5’到3’具有切口酶识别序列的反向互补序列)、回文序列、所述切口酶识别序列,所述第二区的长度是16个核苷酸并且特异性结合至目标核酸分子上的互补区以形成双链杂合体(具有比涉及第二区或和第二区相互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG,其中第二区在3’末端具有一个或多个2’端修饰的核苷酸);和生成包含至少一部分目标核酸分子的扩增子;以及检测寡核苷酸探针与目标核酸分子或其扩增子杂合作用的特定信号,其中所述信号表明试样存在目标核酸分子或存在其扩增子。
本发明的另一个方面提供了在切断扩增反应中扩增目标序列的试剂盒,该试剂盒包括一个或多个引物寡核苷酸(从5’到3’包括第一区和第二区),所述第一区包括自身-互补序列(从5’到3’包括切口酶识别序列的反向互补序列,回文序列以及所述切口酶识别序列),所述第二区长度是16个核苷酸并且特异性结合至目标核酸分子上的互补区以形成双链杂合体(具有比涉及所述第二区或和所述第二区相互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG,其中所述第二区在3’末端具有一个或多个2’修饰的核苷酸);以及本发明方法中引物寡核苷酸的使用说明。
根据本文描述的本发明任意方面,本发明的相关方面提供了挑选引物寡核苷酸的方法,包括提供在有形、永久计算机可读介质上,用来执行挑选寡核苷酸的方法的计算机程序指令。
上述方面的不同实施例中,第一区的长度是12、13、14、15、16、17、18、19、20、21、22、23或24个寡核苷酸。在不同实施例中,所述第一区全部自身-互补。上述方面的不同实施例中,所述第一区的回文序列的长度是2、4或6个核苷酸。上述方面的不同实施例中,所述第二区的长度是16、17、18、19、20、21、22、23、24、25、26、27、28、29或30个核苷酸。
上述方面的不同实施例中,交替结构是一个或多个部分双链的杂合体,所述一个或多个部分双链的杂合体能够由第二区自身形成(例如自身-自身引物)、由所述第二区与第一区的部分序列(例如异质二聚体)形成、由所述第二区与扩增反应中的其他寡核苷酸,引物或探针形成,或由所述第二区与目标序列区外部的部分互补的核酸序列(例如脱靶杂合体)形成。
上述方面的不同实施例中,寡核苷酸(例如引物寡核苷酸,寡核苷酸单体)的形式是通过将两种引物寡核苷酸分子自身-互补的第一区序列杂合作用形成的同源二聚体(例如引物-二聚体)。在不同实施例中,同源二聚体具有比涉及所引物寡核苷酸或和引物寡核苷酸相互作用的任意交替结构的ΔG低至少15kcal/mol的ΔG,包括含有引物寡核苷酸的最稳定交替结构。在上述方面的不同实施例中,于25℃和/或一个大气压(atm)(101.3kPa)为核酸确定或计算自由能(ΔG)(ΔG25℃)。在上述方面的不同实施例中,自由能(ΔG)通过mFold算法确定或计算。
在上述方面的不同实施例中,寡核苷酸(例如引物寡核苷酸,寡核苷酸引物)的第二区包括一个或多个2’端修饰的核苷酸,其中2’端变体选自由2’-O-甲基、2’-甲氧基乙氧基、2’-氟代、2’-羟基、2’-烷基、2’-O-[2-(甲氨基)-2-氧乙基]、4’-硫代、4’-CH2-O-2’-桥、4’-(CH2)2-O-2’-桥、2’-LNA和2’-O-(N-氨基甲酸甲酯)组成的组或包括碱基类似物的那些结构。在特定实施例中,一个或多个2’修饰的核苷酸放置在第二区的3’终端。在其他实施例中,两个或更多个2’修饰的核苷酸是相邻的。进一步地,在其他实施例中,相邻的2’修饰的核苷酸的数量为2、3、4、5或6。本文描述的任意方面中的不同实施例中,切口酶是一个或多个Nt.BspD6I和Nt.BstNBI。本文描述的任意方面中的不同实施例中,第一区里的切口酶识别序列是5’-GAGTC-3’(切口酶识别序列的反向互补序列是5’-GAGTC-3’)。本文描述的任意方面中的不同实施例中,放置寡核苷酸(例如引物寡核苷酸,寡核苷酸单体)具有切口酶的识别序列以切割第一区和第二区之间的磷酸二酯键。上述方面的不同实施例中,聚合酶是杆菌属或嗜热脂肪芽孢杆菌DNA聚合酶I或活性片段及其衍生物。在特定实施例中,聚合酶是一个或多个Bst DNA聚合酶I,Gst DNA聚合酶I或Gka DNA聚合酶I。
本文描述的任意方面的不同实施例中,寡核苷酸(例如引物寡核苷酸,寡核苷酸单体)具有包含下述的核酸序列的第一区:
5’-GACTCN1N1’GAGTC-3’;
5’-GACTCN1N1’GAGTCN-3’;
5’-N2GACTCN1N1’GAGTCN2’-3’;
5’-N2GACTCN1N1’GAGTCN2’N-3’;
5’-N3N2GACTCN1N1’GAGTCN2’N3’-3’;
5’-N3N2GACTCN1N1’GAGTCN2’N3’N-3’;
5’-N4N3N2GACTCN1N1’GAGTCN2’N3’N4’-3’;
5’-N4N3N2GACTCN1N1’GAGTCN2’N3’N4’N-3’;
5’-N5N4N3N2GACTCN1N1’GAGTCN2’N3’N4’N5’-3’;
5’-GACTCN2N1N1’N2’GAGTC-3’;
5’-GACTCN2N1N1’N2’GAGTCN-3’;
5’-N3GACTCN2N1N1’N2’GAGTCN3’-3’;
5’-N3GACTCN2N1N1’N2’GAGTCN3’N-3’;
5’-N4N3GACTCN2N1N1’N2’GAGTCN3’N4’-3’;
5’-N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N-3’;
5’-N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’-3’;
5’-N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’N-3’;和
5’-N6N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’N6’-3’,
5’-GACTCN3N2N1N1’N2’N3’GAGTC-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNNN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNNNN-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’NN-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’NNN-3’;
5’-N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’-3’;
5’-N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N-3’;
5’-N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’-3’;
5’-N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’N-3’;以及
5’-N7N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’N7’-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补,N4和N4’互补,N5和N5’互补,N6和N6’互补,以及N7和N7’互补。在特定实施例中,寡核苷酸(例如引物寡核苷酸,寡核苷酸单体)包括含有本文提交的序列列表中列出的序列的5’端尾部区。
本文描述的任意方面的不同实施例中,检测目标核酸分子的寡核苷酸探针包括:寡核苷酸;荧光报道物;以及能从荧光报道物中吸收激发能的淬灭分子;其中荧光报道物和淬灭分子共价地附接于和所述寡核苷酸相对的5’端和3’端,其中寡核苷酸包括具有核酸序列并且大致互补于目标核酸序列的第一区和第一区上游的第二区5’端以及第一区下游并且具有互补于第二区的核酸序列的第三区3’端,其中当寡核苷酸未结合至目标核酸分子时,所述寡核苷酸能通过将第二区和第三区杂合形成茎环发夹结构。本文描述的任意方面的不同实施例中,目标序列和寡核苷酸探针的第一序列之间的双链杂合体的ΔG比涉及寡核苷酸探针或和寡核苷酸探针相互作用的任意交替结构的ΔG至少低15kcal/mol。在不同的方面,寡核苷酸探针的第二区和第三区的长度是4到8个核苷酸。
本文描述的任意方面的不同实施例中,提供了本发明引物寡核苷酸和/或寡核苷酸探针的使用说明。本文描述的任意方面的不同实施例中,为一起实施扩增和检测反应而设计和/或选择反应中的引物和探针。
通过详细描述以及权利要求书,本发明的其他特征和优势变得明显。
定义
“扩增子”意指扩增受关注的多核苷酸过程中生成的多核苷酸。在一个示例中,聚合酶链反应过程中生成了扩增子。
“扩增速率改良剂”意指可影响聚合酶扩展速率的试剂。
“碱基置换”意指将不会显著干扰互补核苷酸链之间杂合作用的核碱基聚合物置换。
在本公开中,“包括(comprises)”,“包括(comprising)”,“含有(containing)”和“具有(having)”及其类似表述具有美国专利法对其所描述的意义并且可意指“包含(comprises)”和“包含(comprising)”及其类似表述;“基本上由…….构成”或类似“基本上构成……”及其类似表述具有美国专利法所描述的意义并且术语是开放式的,可允许多于所引用表述(只要是基本或新颖的特征)的意义存在,可允许没有改变所引用表述的意义存在,可允许多于所引用表述的意义存在,但排除现有技术的实施例。
通过“互补”或“互补性”意指通过传统沃森-克里克或胡斯坦碱基配对核酸可和另一个核酸序列形成氢键。互补碱基配对不仅包括G-C和A-T碱基配对,也包括涉及普通碱基(例如肌苷)的碱基配对。以百分比表示的互补性显示核酸分子中相邻残基的百分数,所述核酸分子可和第二核酸序列(例如第一寡核苷酸里的全部10个核苷酸中的5、6、7、8、9或10个核苷酸分别呈现出50%、60%、70%、80%、90%和100%互补性,所述第一寡核苷酸的碱基和具有10个核苷酸的第二核酸序列配对)形成氢键(例如沃森-克里克碱基配对)。为了确定以百分比表示互补性至少是特定的百分数,计算核酸分子里可和第二核酸序列形成氢键(例如沃森-克里克碱基配对)的相邻残基的百分数并且取整到最近的整数(例如第一寡核苷酸里的全部23个核苷酸中的12、13、14、15、16或17个核苷酸可分别呈现52%、57%、61%、65%、70%和74%并且分别至少具有50%、50%、60%、60%、70%和70%的互补性,所述第一寡核苷酸的碱基和第二核酸序列配对)。如本文使用的,“大致互补”意指链之间的互补性,这样它们能在生物条件下杂合。大致互补序列具有60%、70%、80%、90%、95%或甚至100%的互补性。另外,通过检查它们的核苷酸序列来确定两条链是否能在生物条件下杂合的技术是所属领域所熟知的。
如本文使用的,“双螺旋”意指通过两个单链核酸相互作用形成的双螺旋结构。双螺旋通常在两个相互反向平行的单链核酸之间通过碱基的配对氢键结合,即“碱基配对”形成。双螺旋的碱基配对通常以沃森-克里克碱基配对呈现,例如DNA和RNA中鸟嘌呤(G)和胞嘧啶(C)形成碱基配对,DNA中腺嘌呤(A)和胸腺嘧啶(T)形成碱基配对,RNA中腺嘌呤(A)和尿嘧啶(U)形成碱基配对。形成碱基配对的条件包括生理或生物相关条件(例如细胞内:pH值:7.2,140mM钾离子;细胞外:pH值:7.4,145mM钠离子)。进一步地,双螺旋通过相邻核苷酸之间的堆积相互作用得以稳定。如本文使用的,通过碱基配对或堆积相互作用可建立或维持双螺旋。双螺旋通过互补的核酸链形成,它们可大致互补或完全互补。和若干碱基进行碱基配对的单链核酸就认为进行了“杂合”。
“探测”意指鉴定出现、缺失待测检测的分析物或其数量。
“可检测的一部分”意指当连接到受关注分子时,将靠后的可检测的分子经由光谱、光化学、生物化学、免疫化学或化学手段染色的组合物。例如,有用的标记物包括放射性同位素、磁珠、金属珠、胶体粒子、荧光染料、电子致密试剂、酶类(例如在ELISA中通常使用的那些)、生物素、洋地黄毒苷或半抗原。
“片段”意指核酸分子的一部分。优选地,这个部分至少包括参照核酸分子或多肽的全部长度的10%、20%、30%、40%、50%、60%、70%、80%或90%。片段可包括5、10、15、20、30、40、50、60、70、80、90或100个核苷酸。
“自由能(ΔG)”意指在公式ΔG=ΔH-TΔS描述的恒定温度和压力下,系统和其环境之间净交换的能量。自由能代表形成结构有多有利,其中具有更负ΔG(例如以kcal/mol表述)的形成结构在多种交替结构的动态平衡中热力学上更加有利。因此,ΔΔG可测量形成具有不同ΔG的两种结构之间倾向性的差异。一方面,ΔΔG提供了在动态平衡中测量形成需要的寡核苷酸结构而不形成其他可能不需要结构的倾向性的数值计分。在一个实施例中,第一结构是在一个寡核苷酸的第一区(5’端尾部区)和第二寡核苷酸(具有和第一寡核苷酸相同的核酸序列)的第一区(5’端尾部区)之间形成的双螺旋杂合体;并且第二结构是包括寡核苷酸的任意其他交替结构。
“杂合”意指在不同严格条件下,在互补性多核苷酸序列(例如,本文描述的基因),或其部分之间形成双链分子。(参见,例如Wahl,G.M.和S.L.Berger(1987)酶学方法.152:399;Kimmel,A.R.(1987)酶学方法.152:507)。杂合作用通过氢键结合呈现,它可为在互补核碱基之间的沃森-克里克,胡斯坦或反向胡斯坦氢键结合。例如,腺嘌呤和胸腺嘧啶是通过形成氢键而配对的互补性核碱基。
“核酸杂合体”意指通过将互补核酸分子结合而形成的大致双链的分子。在一个实施例中,双链的分子是部分或全部双链。
“分离的寡核苷酸”意指在脱除基因的核酸(例如DNA),它在从本发明的核酸分子衍生得到的有机体天然出现的基因组中从两侧保护基因。因此,这个术语包括,例如,并入载体、自主修复质粒或病毒、原核细胞或真核细胞的染色体DNA或作为独立于其他序列的独立分子(例如,cDNA或PCR或限制性内切酶核酸酶消化生成染色体的或cDNA片段)的重组DNA。另外,该术语包括DNA转录的RNA分子和重组DNA(一部分编码额外多肽序列的杂合体基因)。
术语“分离的”、“纯净的”或“生物学上纯合的”意指组分的变化程度恒定的物质,如在其天然态中发现的,所述组分通常伴随所述物质。“分离”表示一定程度上从原始来源或环境中分离。“纯化”表示一定程度上比隔离更强的分离。“纯净的”或“生物学上纯合的”蛋白质充分地脱除了其他物质,这样任何杂质都不会实质性影响蛋白质的生物性质或导致其他不利后果。换言之,如果大致不含微孔物质、病毒性物质、或利用重组DNA技术生成的培养基、或化学合成的化学前体或其他化学物质,本发明的核酸或肽类就是纯净的。纯度和同质性通常利用分析化学技术(例如凝胶电泳或高效液相色谱法)测定。术语“纯净的”可表示核酸或蛋白质实质上产生了在凝胶电泳上的一条带。对于可进行修饰(例如磷酸化或糖基化)的蛋白质而言,不同修饰可能会产生不同分离蛋白质,这可分别纯化。
“融化温度(Tm)”意指平衡中系统的温度,所述平衡中50%分子群体处于一个状态并且50%群体是处于另外的状态。对于本发明的核酸而言,Tm是50%群体为单链并且50%为双链(例如分子内或分子间的双链)的温度。
“监测反应”意指检测反应的进程。在一个实施例中,监测反应进程包括检测聚合酶扩展和/或检测扩增反应完成。
如本文使用的,“获得(obtaining)试剂”里的“获得”包括合成、购买或用其他方法获得试剂。
如本文使用的,术语“核酸”意指单链或双链形式的脱氧核苷酸、核糖核苷酸或修饰了的核苷酸及其聚合物。这个术语包括含有已知核酸类似物或修饰了的骨架残基或连接的核酸,它们是合成的、天然出现的以及非天然出现的,它们具有和参照核酸相似的结合性质,并且它们以和参照核苷酸相似的方式被新陈代谢。这种类似物的示例包括,但不限定为,2’端修饰的核苷酸(例如2’-O-甲基核糖核苷酸、2’-F核苷酸)。
如本文使用的,“修饰的核苷酸”意指对核苷、核碱基、戊糖环或磷酸基进行具有一种或更多修饰的核苷酸。例如,修饰的核苷酸排除包括单磷酸腺苷、单磷酸鸟苷、单磷酸尿苷和单磷酸胞苷的核糖核苷酸和包括单磷酸脱氧腺苷、单磷酸脱氧鸟苷、单磷酸脱氧尿苷和单磷酸脱氧胞苷的脱氧核苷酸。变体包括由使用修饰核苷酸的酶(例如甲基转移酶)的修饰生成的、天然出现的那些变体。修饰的核苷酸也包括合成或非天然出现的核苷酸。核苷酸中合成的或非天然出现的变体包括2’-O-甲基、2’-甲氧基乙氧基、2’-氟代、2’-羟基、2’-烷基、2’-O-[2-(甲氨基)-2-氧乙基]、4’-硫代、4’-CH2-O-2’-桥、4’-(CH2)2-O-2’-桥、2’-LNA和2’-O-(N-氨基甲酸甲酯)或包括碱基类似物的那些结构。
“核苷酸加合物”意指必然会共价地或以其他方式固定于标准核苷酸碱基的一部分。
“切口酶”意指能识别和连接到双链的核酸分子的特定结构并且一旦连接到其识别的特定结构,可破坏单链上相邻核苷酸之间的磷酸二酯键,由此在切断位点之前的终端核苷酸上生成3’-羟基的化学实体。在优选的实施例中,3’末端可通过缺少核酸外切酶的聚合酶而扩展。示例性的切断试剂包括切口酶、RNA酶、DNA酶和过渡金属螯合剂。
“回文”意指当从一条链上的5’端到3’端或互补链上的5’端到3’端读取时,核酸序列是相同的。完美的回文结构指的是具有相邻子序列的序列(例如当一个子序列从端到3’端的方向读取的序列),它和其他从5’端到3’端的方向读取子序列相同。
“聚合酶-捕捉分子”意指和阻止或显著减少多核苷酸模板上的聚合酶前进的多核苷酸模板或引物关联的一部分。优选地,这部分并入到多核苷酸。在一个优选的实施例中,这部分阻止聚合酶在模板上前进。
“聚合酶扩展”意指在模板多核苷酸上,将即将进入的单体和其结合对象进行匹配的聚合酶向前运动。
如本文使用的,“引物-二聚体”意指两个单体寡核苷酸引物的二聚体。本发明的寡核苷酸引物中,5’端尾部区的单体引物进行二聚。
“特定产物”意指将寡核苷酸杂合到互补目标序列和随后介导目标序列扩展的聚合酶而得到的多核苷酸产物。
“大致等温条件”意指单一温度或没有显著变化的狭窄温度范围。在一个实施例中,在大致等温条件下进行的反应在仅变化1℃到5℃(例如以1、2、3、4或5度变化)的温度下进行。在一个实施例中,反应在使用仪器的操作参数内的单一温度进行。
“参照”意指标准或对照条件。如所属领域技术人员显而易见的,合适的参照是为了测定元素效果而改变元素的条件。
“对象”意指哺乳动物,包括但不限制于,人类,非人类动物,例如牛、马、犬类、绵羊或猫。
“目标核酸分子”意指待分析的多核苷酸。这样的多核苷酸可为目标序列的正义或反义链。术语“目标核酸分子”也意指原始目标序列的扩增子。
本文提供的范围理解为速记范围内的所有数值。例如,1到50的范围理解为包括任何数字,数字的组合或包括1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50的组的子范围。
除非特别阐明或从上下文显而易见,如本文使用的,术语“或”理解为包含。除非特别阐明或从上下文显而易见,如本文使用的,术语“一个(a)”,“一个(an)”和“那/这些(the)”理解为单数或复数。
除非特别阐明或从上下文显而易见,如本文使用的,术语“大约”理解为在所属领域正常容忍范围之内,例如2个标准平均差之内。大约可理解为陈述数值的10%、9%、8%、7%、6%、5%、4%、3%、2%、1%、0.5%、0.1%、0.05%或0.01%之内。除非上下文另有澄清,本文所提供的所有数值通过术语大约修饰。
引用本文定义的任何变量中一系列化学基团包括定义可变型为任何单一基团或所列举的基团的组合。本文引用的变型或方面的实施例包括作为任何单一实施例或和任何其他实施例或其部分的组合的实施例。
本文提供的任何组合物或方法可和一个或多个本文提供的任何其他组合物或方法而结合使用。
附图说明
图1描述了表示可高效指数式扩增的目标核酸分子的链置换核酸扩增反应的机理。它显示了目标核酸分子(灰色)的3’末端和对应、序列特异性引物(具有3’端识别区(红色)和可进行二聚作用(黑色)的“5’端尾部”区)相互作用。对于目标特定扩增,3’端识别区(红色)和在序列里互补于并且能特异性杂合到目标核酸。活性构型的引物是通过两个单体引物的5’端尾部区二聚作用形成的稳定同源二聚体(术语称为“引物-二聚体”)。在一个特定实施例中,引物具有自身-互补的、对称翻转的序列。得到的引物-二聚体具有双链的或大致双链的二聚作用区(黑色),它相对于单链的识别区(红色)是5’端。换言之,引物(能对目标核酸分子退火)的目标特定部分在引物-二聚体暴露为3’端单链的区。反应开始时,引物-二聚体的3’端单链的部分将目标核酸分子退火并且启动目标核酸分子的复制。反应过程中,单体引物通过聚合酶链置换行为、以合成互补链从伸展的引物-二聚体中释放。为了增强扩增反应的特异性和/或效率,单体引物设计为具有(1)5’端尾部区(含有自身-互补、对称或大致对称并且能和自身碱基配对的序列)和(2)3’端识别区(在序列里完美地或大致互补于并且能特异性杂合到目标核酸分子)。当引物-二聚体形成的ΔG较低时,引物以具有展开构型的单体呈现的时间减少到最低。不需要单体引物,因为它们可在非目标特异性引物扩展反应中作为模板或引物,由此生成和/或扩增隐蔽物。优选地,单体到二聚体的过渡期“几乎是瞬间的”或可能像动力学那样短暂。动力学因素(例如形成引物-二聚体的较低ΔG,高的引物浓度,高二聚体Tm)用来支持形成引物-二聚体。
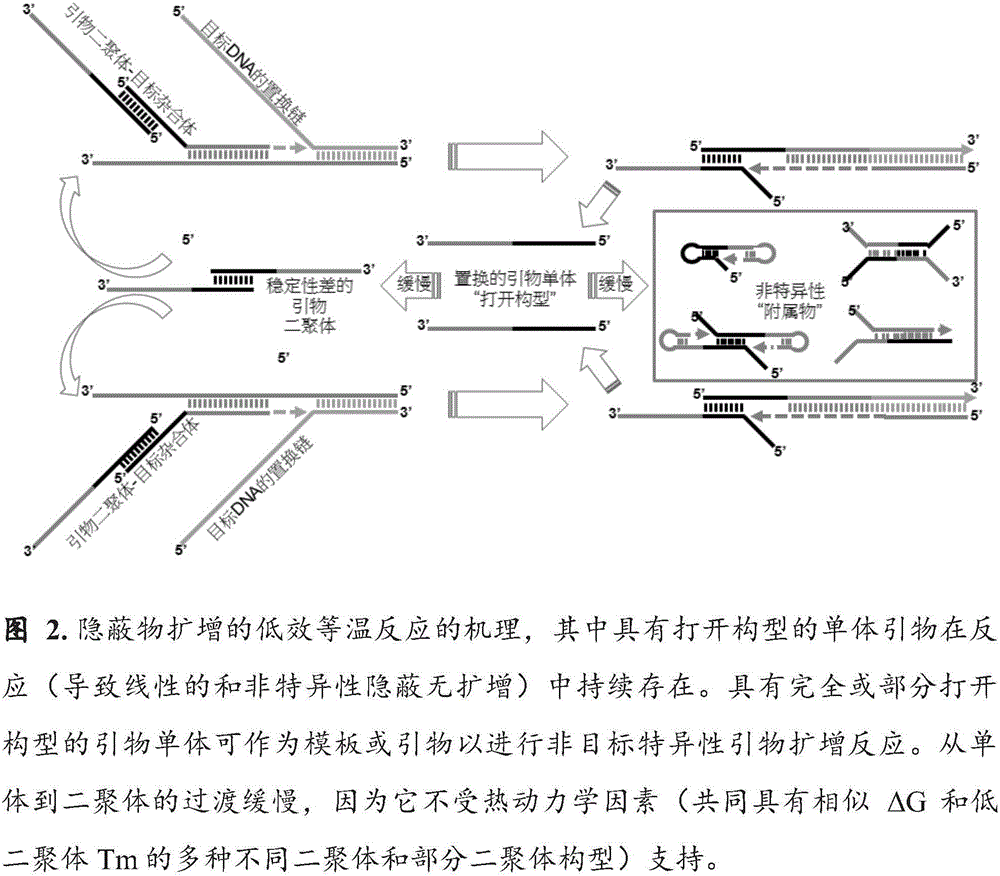
图2描述了表示可低效扩增的目标核酸的链置换核酸扩增反应的机理。它显示了目标核酸分子(灰色)的3’末端和对应的序列-特异性引物(红色和黑色)的相互作用。等温反应(展开构型的单体引物持续存在于其中)导致线性非特异性地扩增隐蔽物。不支持形成引物-二聚体的引物单体具有,例如,在单体引物(黑色)的5’端部位最少或非自身-互补的序列,这会导致形成引物-二聚体需要较高的ΔG。由于引物-二聚体和目标核酸分子的相互作用驱动退火和扩展反应,所以形成引物-二聚体可影响合成和/或扩增目标核酸的效率。在完全或部分展开的构型中,引物单体可作为非目标特异性引物扩展反应(参见插图)的模板或引物,这会导致额外的反应失效。当单体引物的展开构型没有最少化(例如通过序列设计),单体到二聚体过渡缓慢,因为它不受热力学因素(例如多种二聚体和同时具有相似ΔG和Tm的部分二聚体构型)的支持。
图3描述阻止形成引物-二聚体的引物结构,例如导致非特异性副产品扩增的结构(结构(H)到(J))的结构(A)到(C)或结构(D)到(K),它们不能进行目标杂合作用。它显示了引物(红色和黑色)核酸片段(灰色)之间的相互作用。结构(A)描述了在目标特异性区里具有非连续反向序列的引物单体,它能向后“成环”以形成可扩展的3’末端以进行“自身-复制”。结构(A)也具有在自身上向后成环的5’端区。结构(B)描述了在引物的目标特异性区具有非连续反向序列的引物-二聚体,它能向后“成环”以形成可扩展的3’末端以进行“自身-复制”。结构(C)描述了“展开”构型里的引物单体和单链的DNA片段(灰色)(以DNA聚合酶切断扩展反应以紧密放置的随机行为和/或模板DNA中的序列-特异性缺口而取代)之间的伪杂合体结构。结构(D)描述了部分双链的二聚体结构,其中目标特异性区的重要部分不易进行目标杂合作用。可通过引物单体的反向序列复制形成结构(D)。结构(E)描述了从结构(A)生成的,过渡的、伪引物扩展/链置换的反应产物。结构(G)描述了从结构(B)生成的,过渡的、伪引物扩展/链置换的反应产物。结构(H)描述了“切口&凹底”模式的成熟的、伪反应产物,导致出现连续性循环并且扩增单链副产品。结构(J)描述了“切口&凹底”模式的成熟的、伪反应产物,导致出现连续性循环并且进行扩增单链副产品。结构(K)描述了反应中结构(D)的部分双链的二聚体的持续性。因为目标特异性区的重要部分不易进行目标杂合作用,复制和/或扩增阻止或没有启动目标核酸。根据跟本发明的引物设计促进形成最佳的引物-二聚体,这就导致形成不需要引物结构并且将它们对目标特异性核酸扩增的抑制作用最低化。
图4显示了理想的(右边)和不理想的(左边)的引物结构。由于存在自身-互补序列,本发明的引物可选择对扩增反应有利的结构,包括引物-二聚体和/或发夹。不限于理论,引物二聚体更加稳定并且当引物在反应(例如反应开始时)中以高浓度存在时形成,当引物浓度降低时(例如反应进程开始时),形成发夹。
图5描述了非最佳引物的构型之间存在动力学平衡时的不理想的引物构型。当对应于形成每个结构的ΔG大约相同(即ΔG1≈ΔG2≈ΔG3≈ΔG4)时,不存在优选的引物构型或结构。当引物存在于这样的多种构型时,将其构造为促进核酸扩增反应并非最佳。
图6显示最佳引物是高度优选(即ΔG1>>ΔG2),特别是比下一个优选构型(例如当引物和自身分子内相互作用时)优选的二聚体构型的引物。这种构型和附图5形成对照,其中构型之间存在动态平衡。引物可设计为具有对核酸扩增反应有利的稳定构型和结构,同时减少或消除形成不理想的引物构型和结构。对于具有5’端尾部二聚作用区的引物而言,优选5’端尾部序列并且比其他结构(ΔG1≤-30到-62kcal/mol)更加稳定。对于切断反应中的引物,5’端尾部序列大致自身-互补并且对称性地反转。这样的引物可能具有形成分子内相互作用(例如发夹环)的潜力。但是,如引物-二聚体比发夹环结构(具有和ΔG2相比很低的ΔG1)更稳定所表明的,当对称性反向序列完全互补时,这样的构型减少到最低。因此,当引物的浓度足够高时,没有有效地形成发夹。
图7描述了在切断扩增反应中有用的引物中的稳定引物-二聚体结构序列。图7描述了具有5’端尾部区(具有顶链切口酶(Nt.BstNBI)的切口酶识别序列)的引物二聚体的同源二聚体。切断位点设计为放置在5’端尾部区上3’末端的核苷酸和3’端识别区的5’末端的核苷酸之间。不限于理论,当3’端识别区是单链时,切口酶没有在切断位点切割。但是,当3’端识别区是双链时(例如,核酸扩增反应过程中引物并入到双链目标核酸分子时),在切断位点出现切割。
图8A-8C描述了示例性5’端尾部区的序列。图8A描述了长度是24个核苷酸的5’端尾部区,它具有Nt.BstNBI识别序列并且基于下述公式:5’-NNNNGACTCNNNNNNGAGTCNNNN-3’。根据这个公式,有537,824个5’端尾部区,它们具有下述性质:ΔG=-34.2kcal/mole到-65kcal/mole;ΔΔG<-40kcal/mole;并且GC含量是68%到84%。当然,提供了1050个选择的序列,代表了全部序列空间(248,832)的0.2%。图8B描述了长度是22个核苷酸的示例性5’端尾部区序列,它具有Nt.BstNBI识别序列并且基于下述公式:5’-NNNNGACTCNNNNGAGTCNNNN-3’。根据这个公式,有248,832个5’端尾部序列,它们具有下述性质:ΔG=-47kcal/mole到-55kcal/mole;ΔΔG<-40kcal/mole;并且GC含量是72%到82%。当然,提供了200个选择的序列,代表了全部序列空间(248,832)的0.08%。图8C描述了具有6个核苷酸间隔区的示例性5’端尾部区序列。
图9是显示利用本发明引物进行引物特异性核酸扩增(具有如DNA扩增双通道检测所检测的5’端尾部和3’端识别区)的图表。目标特异性产品通过分子信标探针(顶面板)检测。非特异性核酸扩增利用SYBRGreen检测。如两个图表中所显示的,在大约6分钟时开始指数扩增,这表明扩增是目标特异性的。不具有输入的对照反应没有产生实质上的隐蔽物。
图10是表明利用本发明的引物(具有5’端尾部和3’端识别区)的核酸扩增具有对快速检测目标核酸有用的特征的图表。这样的反应的特征在于高信噪比([RFUMAX-RFUBL])、斜率([RFUMAX-RFUBL]/[TOSEA-TRFUmax]的高数值)、较早开始指数扩增阶段(TOSEA<10min)以及相同试样的复制试验反应之间的较低信号差异。
图11是根据它们相对稳定性描绘的生效和失效的试验引物的图表。观察到具有3’端识别序列(ΔΔG≤大约-16kcal/mole)的引物在切断扩增反应中生效,同时引物(ΔΔG>大约-16kcal/mole)易于失效。观察到具有3’端识别区(ΔΔG≤大约-16kcal/mole)和5’端尾部(ΔΔG≤大约-30kcal/mole)的引物生效了。
图12描述了对来自一对预测的最佳引物结构的大豆凝集素的等温DNA扩增试验,和单一预测而不用筛选性能不知的大量待选引物组合的最佳探针的设计。
图13是描述了大豆凝集素的等温DNA扩增试验的第一试验性尝试结果的图表,它经验性地确认了对试验性能的预测。在包含大豆基因组DNA的反应中观察到目标特异性扩增。在没有目标对照的反应中没有观察到扩增。
图14描述了对来自一对预测的最佳引物结构的致病性沙门氏菌invA基因的等温DNA扩增试验和单一预测而不用筛选性能不知的大量待选引物组合的最佳探针的设计。
图15是描述了致病性沙门氏菌invA基因的等温DNA扩增试验的第一试验性尝试结果的图表,它经验性地确认了对试验性能的预测。在包含大豆基因组DNA的反应中观察到目标特异性扩增。在无目标对照的反应中没有观察到扩增。
图16包括因沙门氏菌invA基因轻易地优化而显示等温DNA扩增试验的两个图表。
图17A到17I显示引物结构参数(Tm,%GC,bp长度,ΔG25℃,ΔΔG25℃)集群分析。图17A是描绘生效试验引物和失效试验引物的第一引物区(5’-尾部)自身-自身二聚体的ΔΔG(kcal/mol)对第二引物区/目标杂合双螺旋的ΔΔG(kcal/mol)的图表。生效试验引物和失效试验引物的集群显示了和功能/非功能的联系。图17B是描绘生效试验引物和失效试验引物的第二引物目标-互补区的碱基表示的长度对第二引物目标-互补区的%GC含量的图表。生效试验引物和失效试验引物显示出随机分布。图17C是描绘生效试验引物和失效试验引物的第二引物目标-互补区的碱基表示的长度对第二引物区/目标杂合双螺旋的ΔG(kcal/mol)的图表。生效试验引物和失效试验引物显示出随机分布。图17D是描绘生效试验引物和失效试验引物的第二引物区/目标杂合双螺旋的Tm(℃)对第二引物区/目标杂合双螺旋的图表。生效试验引物和失效试验引物显示其和功能/非功能没有关系。图17E是描绘生效试验引物和失效试验引物的最优选第二引物区/脱靶杂合双螺旋的ΔG(kcal/mol)对引物区/目标杂合双螺旋ΔG(kcal/mol)的图表。生效试验引物和失效试验引物显示出随机分布。图17F是描绘了生效试验引物和失效试验引物的第二引物区的%GC含量对第二引物区/目标杂合双螺旋的Tm(℃)的图表。生效试验引物和失效试验引物显示出随机分布。图17G是描绘生效试验引物和失效试验引物的第二引物区的%GC含量对第二引物区/目标杂合双螺旋的ΔG(kcal/mol)的图表。生效试验引物和失效试验引物显示出随机分布。图17H是描绘生效试验引物和失效试验引物的第二引物区的%GC含量对第二引物区/目标杂合双螺旋的Tm(℃)的图表。生效试验引物和失效试验引物显示出随机分布。图17I是描绘生效试验引物和失效试验引物的引物(3’端识别区)的碱基表示的长度对引物-目标杂合双螺旋的Tm(℃)的图表。生效试验引物和失效试验引物显示出随机分布。
具体实施方式
本发明涉及对引物的可预测设计有益的方法以及利用这样的引物在核酸扩增反应中的目标核酸分子进行扩增的方法。该组合物和方法对核酸扩增反应(包括切断扩增反应)中的目标核酸分子扩增和检测也有益。
本发明至少部分基于涉及核酸扩增反应中使用的寡核苷酸的若干发现,包括引物和探针以及它们增强或实现核酸扩增反应的效果。申请人首先理解的是这些发现的一个或多个组合可应用于设计核酸扩增反应和/或检测试验使用的引物和探针。
本发明至少部分基于在特定构型中寡核苷酸(例如引物和探针)具有增强核酸扩增反应性能的潜力以及能通过检查需要的特异性寡核苷酸-目标序列杂合体和不同非特异性分子内(部分双链的单体)和寡核苷酸的分子间络合物(引物-引物和引物-探针二聚体,脱靶杂合体)之间自由能变化(ΔG)差异的能力(寡核苷酸选择优选构型)的发现。迄今为止,设计引物和探针将目标特异性和非特异性引物和探针结构之间自由能的差异作为排名工具以鉴别对目标序列扩增试验最适合的引物。应用上述引物设计的考量需要设计可预测性发挥功能(减少或消除经验性测试的需要)的引物。因此,本发明提供了选择引物序列、引物修饰和/或探针设计(促进可操作性的核酸扩增和检测反应)的方法。
申请人发现含有3’端序列(形成引物-目标稳定(例如G25℃≤大约-20kcal/mol或更多))的引物具有增强核酸扩增反应性能。在特定实施例中,3’端目标识别序列包括12到24、12到17或12到14个碱基。在特定实施例中,形成引物-目标比形成自身二聚体(例如ΔΔG≤大约-15、-16、-17、-18、-19、-20kcal/mol)更加稳定。实际上,已经发现了生效和不生效试验之间的差异在ΔΔG<大约-15kcal/mol(参见,例如附图11)时出现。
另外,申请人发现具有5’端尾部区(能进行自身二聚作用)的引物会增强核酸扩增反应性能。不限于理论,在核酸扩增反应中,引物将将目标核酸退火成为引物-二聚体(参见,例如附图1)。令人惊奇并且意外的是,这种引物-二聚体构型没有可检测性地干扰聚合酶活性并且减少或阻止引物5’端部分和自身或其他核酸分子进行非特异性的相互作用。5’端尾部区包括完美的回文序列,它可通过单体引物二聚作用形成。例如,引物具有位于5’末端的切断试剂识别位点(和目标识别序列的引物结合特异性相关)。从非特异性引物相互作用得到非特异性隐蔽产品具有隔绝反应组分(本来是用在特定产品的扩增)的潜力。在不同实施例中,形成同源二聚体是稳定的(例如G25℃≤大约-30、-35、-40、-45、-50、-55、-60kcal/mol或更多)。在不同的实施例中,同源二聚体具有比扩展反应温度更高的融化温度。在特定实施例中,5’端尾部区具有回文的结构。在进一步的实施例中,5’端尾部区的长度是至少20个碱基(例如20、21、22、23、24个碱基)。在另外的实施例中,5’端尾部区的GC含量是80%到90%。在特定实施例中,形成同源二聚体比形成其他稳定性差一些的引物二聚体构型(ΔΔG≤大约-15、-20、-25、-30、-35、-40kcal/mol或更多)更加稳定。
进一步地,申请人发现在3’端识别区的3’末端上包括2’端修饰(例如2’-O-甲基,2’-氟,2’-烷基)的核苷酸的引物会减少或消除非特异性隐蔽产品。这就增加了核酸扩增反应中生成特定产品而不生成隐蔽产品的情况。在不同实施例中,3’端识别区的一个或多个核苷酸包括可动摇错配碱基对的修饰了的核碱基。在特定实施例中,当位置1位于3’终端的核苷酸时,修饰了的核碱基位于两个或更多连续核苷酸上(从3’终端,于位置1、2、3、4、5或6开始)。在特定实施例中,不少于8个以及不多于10个未修饰的核苷酸放置于3’端识别区的第一5’端核苷酸和最近3’端修饰的核苷酸之间。
在特定实施例中,引物包括3’端识别区和5’端尾部二聚作用区。在反应条件下,单体引物通过将他们的5’端尾部二聚作用区结合进行二聚以形成引物-二聚体。不限于理论,引物-二聚体的单链3’端识别区将目标核酸分子退火并且合成互补目标链。通过合成互补链进行聚合酶链置换,单体引物从扩展链中释放。释放的单体引物通过和5’端尾部区结合和另一个自由单体进行二聚作用。多个循环实现了指数目标核酸扩增。
引物设计
引物设计的常规方法集中于引物融化温度、引物退火温度、GC(鸟嘌呤和胞嘧啶)含量、引物长度以及最小化引物和目标核酸以外所有核酸(参见,例如www.premierbiosoft.com/tech_notes/PCR_Primer_Design.html)的相互作用。和这些方法相反,已经发现形成稳定引物/二聚体并以术语形成自由能(ΔG)表述的引物在核酸扩增反应中可预测性地发挥作用。虽然自由能(ΔG)和融化温度(Tm)具有相同主要成分焓(ΔH)和熵(ΔS),但是得到了不同ΔG和Tm数值并且它们没有相关联系,将给出ΔG和给出Tm关联的唯一方法是从得到它们的地方(曼迪,“mFold,Delta G,和融化温度”和2011整合DNA技术)明确了解ΔH和ΔS的数值。图1到11涉及最佳引物的设计。
可利用所属领域的公式计算分子间引物结构的形成自由能(ΔG)。大量的程序可用来确定形成了不同分子内和分子间引物结构和计算它们的ΔG,包括,例如mfold和UNAfold预测算法(参见,例如,Markham和Zucker.UNAFold:核酸折叠和杂合作用软件.生物信息学:第2卷,第1章,3到31页,Humana出版社.,2008;Zucker等。RNA次级结构预测的算法和热力学:RNA生物化学和生物技术的实用手册,11到43,NATO ASI系列,Kluwer学术出版社,1999;M,Zucker.利用能量最低化预测RNA次级结构.《分子生物学方法》,267到294,1994;Jaeger等。预测RNA最佳和次佳二级结构。分子进化:蛋白质和核酸序列的计算机分析,《酶学方法》183,281到306,1990;Zucker。关于发现所有次佳的RNA分子折叠。科学244,48到52,1989)。寡核苷酸分析器3.1利用mfold这样实施一个引物设计(www.idtdna.com/analyzer/Applications/OligoAnalyzer/)。例如,关于寡核苷酸分析器3.1,可利用下述参数计算ΔG:目标类型:DNA;寡核苷酸浓度0.25μM;Na+浓度:60mM;Mg++浓度:15mM;以及dNTPs浓度:0.3mM。
3’端识别区
本发明提供了具有3’端识别序列(其形成引物-目标是稳定的并且具有增强核酸扩增反应性能的潜力)的引物。3’端识别区特异性和目标核酸结合,例如目标核酸的互补序列。在特定实施例中,3’端识别区具有互补于目标核酸序列12、13、14、15、16、17、18、19或20或更多的碱基的序列。在不同实施例中,引物-目标融化温度等于或高于8℃或比反应或试验的扩展温度(Tm≥试验温度-8℃)低6℃。在特定实施例中,3’端识别序列包括12到20,12到17或12到14个核苷酸。在特定实施例中,引物-目标形成比自身二聚体形成(例如ΔΔG≤大约-15、-16、-17、-18、-19、-20kcal/mol或更多)更加稳定。实际上,已经发现了生效和不生效试验之间的差异存在于ΔΔG<大约-15kcal/mol之时(参见,例如附图11)。优选地,3’端识别序列不包括自身-互补序列,短的反向重复序列(例如,>4个碱基/重复序列),或本来会促进分子内相互作用的序列,它有干扰引物目标退火的潜力。
具体地,本发明具有3’端识别序列的引物对切断扩增试验有益。另外,目标特异性3’端识别区包括一个或多个2’端修饰的核苷酸(例如2’-O-甲基、2’-甲氧基乙氧基、2’-氟代、2’-羟基、2’-烷基、2’-O-[2-(甲氨基)-2-氧乙基]、4’-硫代、4’-CH2-O-2’-桥、4’-(CH2)2-O-2’-桥、2’-LNA和2’-O-(N-氨基甲酸甲酯))。不限于理论,假设一个或多个2’端修饰的核苷酸并入识别序列会减少或消除引物的分子间和/或分子间相互作用(例如引物-二聚体形成)以及由此减少或消除了等温扩增中的隐蔽信号。2’端修饰的核苷酸优选具有和目标序列碱基配对的碱基。在特定实施例中,目标特异性识别区的两个或更多2’端修饰的核苷酸(例如2、3、4、5或更多的2’端修饰的核苷酸)是连续的。在一些实施例中,在目标特异性识别区的3’末端上对2’端修饰的核苷酸进行封阻。在其他实施例中,在目标特异性识别区的5’末端上对2’端修饰的核苷酸进行封阻。当在目标特异性识别区的5’末端上对2’端修饰的核苷酸进行封阻,可利用一个会或更多未修饰的核苷酸(例如2、3、4、5或更多的2’端修饰的核苷酸)从切断位点上分离的2’端修饰的核苷酸。申请人发现定位一个或多个2’端修饰的核苷酸或对2’端修饰的核苷酸进行封阻改变了扩增的动力学。当一个或多个2’端修饰的核苷酸或对2’端修饰的核苷酸进行封阻定位于或接近于识别区的5’末端或邻近切断位点时,实时扩增反应显示检测的时间增加。另外,信号曲线缩短了并且曲线斜率改变了。
在相关实施例中,具有一个或多个2’端修饰的核苷酸的引物的比例可用来改变检测时间和/或调谐反应的效率,实现了对反应动力学的可预测性控制。增加在识别捕猎的3’末端具有一个或多个2’端修饰的核苷酸的引物和在识别捕猎的5’末端具有一个或多个2’端修饰的核苷酸的引物的比例缩短了信号曲线并且改变了曲线斜率。能调谐反应(提供控制检测时间和反应效率的手段)是有利的。调谐反应可用来在定量PCR(qPCR)中匹配目标核酸扩增和参照核酸扩增的效率。另外,目标核酸的扩增曲线和内标可改变,这样它们的扩增产物的检测时间可分离开,同时为目标核酸扩增和内标扩增提供相同的效率。通过使用特定组合和反应中的寡核苷酸结构的比例,可创造能实现能调谐反应性能的条件是有可能的。
5’端尾部二聚作用区
本发明提供了具有5’端尾部区(能自身二聚作用)的引物,它可增强核酸扩增反应性能。不受限于理论,在核酸扩增反应中,引物将目标核酸退火成为引物-二聚体(参见,例如附图1)。例如,切断扩增引物在5’末端具有切断试剂识别位点,它和目标识别序列的引物特异性结合无关。来自非特异性引物相互作用的非特异性隐蔽产品具有隔绝反应成分(原本是用作特定产品扩增)的潜力。在不同实施例中,形成同源二聚体稳定(例如ΔG≤大约-30、-35、-40、-45、-50、-55、-60kcal/mol或更多)。在不同实施例中,同源二聚体具有比扩展反应温度更高的融化温度。在特定实施例中,具有回文的序列。在进一步实施例中,5’端尾部区的长度是至少12个碱基(例如12、13、14、15、16、17、18、19、20、21、22、23、24个碱基)。在另外的实施例中,5’端尾部区的GC含量是80%到90%。在特定实施例中,同源二聚体形成比其他稳定性差一些的引物二聚体构型形成更加稳定(例如ΔΔG≤大约-12、-13、-14、-15、-16、-17、-18、-19、-20、-25、-30、-35、-40kcal/mol或更多)。
具体地,本发明具有5’端尾部序列的引物对切断扩增反应有益。为了在切断扩增反应中使用,5’端尾部区包括一个或多个切断试剂识别位点并且5’端尾部区具有对称翻转序列。在一些实施例中,切断位点设计为在5’端尾部区的3’末端上的核苷酸和3’端识别区的5’末端上的核苷酸之间。不受限于理论,当3’端识别是单链时,切口酶没有在切断位点进行切割。但是,当3’端识别区是单链时(例如当核酸扩增反应过程中引物并入双链目标核酸分子时),切断位点出现切割。
不同实施例中,5’端尾部序列从5’端到3’端包括反向切口酶识别序列,它可操作性地连接到回文序列(或自身-互补序列),也可操作性连接到切口酶识别序列。在特定实施例中,间隔区具有偶数个核苷酸(例如2、4、6个等等)。
基于Nt.BstNBI切口酶识别序列(5’-GAGTC-3’)并且具有2个核苷酸间隔区的示例性5’端尾部包括根据下述公式的核酸序列:
5’-GACTCN1N1’GAGTC-3’
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补。
这样2个碱基间隔尾部序列的示例性序列包括,例如,根据下述公式的核酸序列:
5’-GACTCN1N1’GAGTC-3’;
5’-GACTCN1N1’GAGTCN-3’;
5’-N2GACTCN1N1’GAGTCN2’-3’;
5’-N2GACTCN1N1’GAGTCN2’N-3’;
5’-N3N2GACTCN1N1’GAGTCN2’N3’-3’;
5’-N3N2GACTCN1N1’GAGTCN2’N3’N-3’;
5’-N4N3N2GACTCN1N1’GAGTCN2’N3’N4’-3’;
5’-N4N3N2GACTCN1N1’GAGTCN2’N3’N4’N-3’;and
5’-N5N4N3N2GACTCN1N1’GAGTCN2’N3’N4’N5’-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补,N4和N4’互补,N5和N5’互补等等。
在一些实施例中,2个碱基间隔尾部排除包括根据下述公式的核酸序列的那些核酸序列:
5’-TCGACTCN1N1’GAGTCGA-3’;
5’-TCGACTCN1N1’GAGTCGAN-3’;
5’-N2TCGACTCN1N1’GAGTCGAN2’-3’;
5’-N2TCGACTCN1N1’GAGTCGAN2’N-3’;
5’-GTCGACTCN1N1’GAGTCGAC-3’;
5’-GTCGACTCN1N1’GAGTCGACN-3’;
5’-N3N2TCGACTCN1N1’GAGTCGAN2’N3’-3’;
5’-N3GTCGACTCN1N1’GAGTCGACN3’-3’;and
5’-AGTCGACTCN1N1’GAGTCGACT-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补等等。
基于Nt.BstNBI切口酶识别序列(5’-GAGTC-3’)并且具有4个核苷酸间隔区的示例性5’端尾部包括根据下述公式的核酸序列:
5’-GACTCN2N1N1’N2’GAGTC-3’
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补。
这样4个碱基间隔尾部序列的示例性序列包括,例如,根据下述公式的核酸序列:
5’-GACTCN2N1N1’N2’GAGTC-3’;
5’-GACTCN2N1N1’N2’GAGTCN-3’;
5’-N3GACTCN2N1N1’N2’GAGTCN3’-3’;
5’-N3GACTCN2N1N1’N2’GAGTCN3’N-3’;
5’-N4N3GACTCN2N1N1’N2’GAGTCN3’N4’-3’;
5’-N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N-3’;
5’-N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’-3’;
5’-N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’N-3’;和
5’-N6N5N4N3GACTCN2N1N1’N2’GAGTCN3’N4’N5’N6’-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补,N4和N4’互补,N5和N5’互补和N6和N6’等等。
在一些实施例中,4个碱基间隔尾部排除包括根据下述公式的核酸序列的那些核酸序列:
5’-GACTCGATCGAGTC-3’;
5’-GACTCGATCGAGTCN-3’;
5’-N1GACTCGATCGAGTCN1’-3’;
5’-N1GACTCGATCGAGTCN1’N-3’;
5’-N2N1GACTCGATCGAGTCN1’N2’-3’;
5’-N2N1GACTCGATCGAGTCN1’N2’N-3’;
5’-TCGACTCN2N1N1’N2’GAGTCGA-3’;
5’-TCGACTCN2N1N1’N2’GAGTCGAN-3’;
5’-N3N2N1GACTCGATCGAGTCN1’N2’N3’-3’;
5’-N3N2N1GACTCGATCGAGTCN1’N2’N3’N-3’;
5’-N3TCGACTCN2N1N1’N2’GAGTCGAN3’-3’;
5’-N3TCGACTCN2N1N1’N2’GAGTCGAN3’N-3’;
5’-GTCGACTCN2N1N1’N2’GAGTCGAC-3’;
5’-GTCGACTCN2N1N1’N2’GAGTCGACN-3’;
5’-N4N3N2N1GACTCGATCGAGTCN1’N2’N3’N4’-3’;
5’-N4N3TCGACTCN2N1N1’N2’GAGTCGAN3’N4’-3’;
5’-N3GTCGACTCN2N1N1’N2’GAGTCGACN3’-3’;和
5’-AGTCGACTCN2N1N1’N2’GAGTCGACT-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补等等。
基于Nt.BstNBI切口酶识别序列(5’-GAGTC-3’)并且具有6个核苷酸间隔区的示例性5’端尾部包括根据下述公式的核酸序列:
5’-GACTCN3N2N1N1’N2’N3’GAGTC-3’
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补。
6个碱基间隔区尾部序列的示例性序列包括,例如,根据下述公式的核酸序列:
5’-GACTCN3N2N1N1’N2’N3’GAGTC-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNNN-3’;
5’-GACTCN3N2N1N1’N2’N3’GAGTCNNNN-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’NN-3’;
5’-N4GACTCN3N2N1N1’N2’N3’GAGTCN4’NNN-3’;
5’-N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’-3’;
5’-N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N-3’;
5’-N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’-3’;
5’-N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’N-3’;和
5’-N7N6N5N4GACTCN3N2N1N1’N2’N3’GAGTCN4’N5’N6’N7’-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补,N4和N4’互补,N5和N5’互补,N6和N6’互补,以及N7和N7’互补。
在一些实施例中,6个碱基间隔区尾部排除具有根据下述公式的核酸序列的那些核酸序列:
5’-GACTCGAN1N1’TCGAGTC-3’;
5’-GACTCGAN1N1’TCGAGTCN-3’;
5’-N2GACTCGAN1N1’TCGAGTCN2’-3’;
5’-N2GACTCGAN1N1’TCGAGTCN2’N-3’;
5’-N3N2GACTCGAN1N1’TCGAGTCN2’N3’-3’;
5’-N3N2GACTCGAN1N1’TCGAGTCN2’N3’N-3’;
5’-TCGACTCN3N2N1N1’N2’N3’GAGTCGA-3’;
5’-TCGACTCN3N2N1N1’N2’N3’GAGTCGAN-3’;
5’-N4N3N2GACTCGAN1N1’TCGAGTCN2’N3’N4’-3’;
5’-N4N3N2GACTCGAN1N1’TCGAGTCN2’N3’N4’N-3’;
5’-N4GTCGACTCN3N2N1N1’N2’N3’GAGTCGACN4’-3’;
5’-GTCGACTCN3N2N1N1’N2’N3’GAGTCGAC-3’;
5’-GTCGACTCN3N2N1N1’N2’N3’GAGTCGACN-3’;
5’-N5N4N3N2GACTCGAN1N1’TCGAGTCN2’N3’N4’N5’-3’;
5’-N5N4TCGACTCN3N2N1N1’N2’N3’GAGTCGAN4’N5’-3’;
5’-N4GTCGACTCN3N2N1N1’N2’N3’GAGTCGACN4’-3’;和
5’-AGTCGACTCN3N2N1N1’N2’N3’GAGTCGACT-3’,
其中,“N”是任意核苷酸(例如,具有腺嘌呤(A),胸腺嘧啶(T),胞嘧啶(C)或鸟嘌呤(G)核碱基),并且N1和N1’互补,N2和N2’互补,N3和N3’互补,N4和N4’互补,N5和N5’互补等等。
附图8E到8E提供了示例性5’端尾部区序列。长度是24个核苷酸并且具有Nt.BstNBI识别序列的示例性5’端尾部区序列的可根据下述模板5’-NNNNGACTCNNNNNNGAGTCNNNN-3’(附图8A)而生成。基于这种模板,存在具有下述性质的537,824个5’端尾部序列:ΔG=-48kcal/mole到-62kcal/mole;ΔΔG<-40kcal/mole;并且GC含量是68%到84%。当然,提供了1050个选择的序列,代表了全部序列空间(248,832)的0.2%。长度是22个核苷酸并且具有Nt.BstNBI识别序列示例性5’端尾部区序列基于下述模板5’-NNNNGACTCNNNNGAGTCNNNN-3’(附图8B)。基于这个模板,存在具有下述性质的248,832个5’尾部序列:ΔG=-47kcal/mole到-55kcal/mole;ΔΔG<-40kcal/mole;并且GC含量是72%到82%。当然,提供了200个选择的序列,代表了全部序列空间(248,832)的0.08%。
核酸扩增方法
核酸扩增技术提供了可理解的复杂生物工艺、检测和鉴别的手段以及致病和非致病生物体、法医犯罪分析、疾病相关研究、基因修饰有机体检测事项等的手段。聚合酶链反应(PCR)是常见的取决于热循环的核酸扩增技术,它用来利用DNA聚合酶扩增DNA,它包括重复加热和冷却反应(为DNA融化和DNA酶复制进行)的循环。实时定量PCR(qPCR)是在生物试样中用来量化给出核酸序列的复制品数量的技术。当前,qPCR在反应实始末时监测反应产品并且将扩增情况和对照试验扩增比较,它在每个反应开始时包括已知并且量化的核酸(或核酸和未知测试核酸的已知相对比例)。对照的结果用来构建标准曲线,而这通常基于标准反应扩增曲线的对数部分。基于它们的扩增曲线(和标准对照数量相比),这些数值用来插入未知物的数量。
除了PCR,取决于热力学循环的扩增系统或等温核酸扩增技术存在于,包括,但不限于:切断扩增反应、滚环扩增(RCA)、解旋酶-依赖性扩增(HDA)、环介导扩增(LAMP)、链置换扩增(SDA)、转录介导扩增(TMA)、自给序列复制(3SR)、基于核酸序列扩增(NASBA)、单一引物等温扩增(SPIA)、Q-β复制酶系统以及重组酶聚合酶扩增(RPA)。
等温切断扩增反应具有和PCR热循环类似之处。如PCR,切断扩增反应使用互补于目标序列(称为引物)的寡核苷酸序列。另外,目标序列的切断扩增反应导致目标序列对数增加,就像它在标准PCR中一样。不像标准PCR,切断扩增反应等温地行进。在标准PCR中,升高温度以使得DNA的两条链分离。在切断扩增反应中,目标核酸序列在存在于测试试样的特定切断位点上进行切割。聚合酶浸润切断位点并且开始合成切割目标核酸序列(加入的外源DNA)的互补链同时将存在的互补DNA链置换。链置换复制工艺不再需要热链分离。此时,引物分子将加入的外源DNA的置换互补序列退火。现在聚合酶从引物3’末端扩展,为先前的置换链生成了互补链。第二引物寡核苷酸随后将新合成的互补链退火并且扩展以生成DNA双螺旋,它包括切断试剂识别序列。这个链随后易于通过聚合酶利用利用后续链置换扩展而被切割,这就导致生成DNA(在原始目标DNA的两端上具有切断位点)双链的临时扩增子。一旦合成这种临时扩增子,通过利用线引物分子将置换链复制,分子继续指数扩增。另外,通过在引物模板的切断位点上重复切口平移合成行为,扩增也从每个产品分子线性前进。结果是快速增加目标信号的扩增;这比通过PCR热循环生成更加快速并且扩增时间少于10分钟。
切断试剂依赖性等温核酸扩增试验
本发明提供了检测目标核酸分子(在等温切断扩增试验扩增而得)。对本文描述方法有用的聚合酶能催化并入核苷酸用来协同链置换行为扩展寡核苷酸(例如引物)束缚于目标核酸分子中的3’羟基终端和/或双链DNA分子上的切断位点上的3’羟基终端。这样的聚合酶也缺少或实质减少了5’-3’外切酶行为并且可能包括嗜热性的这些聚合酶。对涉及引物(在引物区上具有2’端修饰的核苷酸(包括6个3’终端核苷酸))的方法有用的DNA聚合酶包括衍生物和DNA聚合酶I(从嗜热脂肪芽孢杆菌分离,也分类为嗜热脂肪芽孢杆菌并且来自密切联系的菌株,隔离群和种类(包括杆菌属))的变体,这缺少或实质上减少了5’-3’外切酶活性并且具有链置换活性。示例性聚合酶包括,但不限制于Bst DNA聚合酶I、Gst DNA聚合酶I、Gka DNA聚合酶I的大片段。
对本发明描述方法有用的切断试剂是能在双链核酸分子上识别和结合特定结构并且在顶链的相邻核苷酸之间切割磷酸二酯键(当结合到其识别的特定结构时,其速率实质上比切割底链上的结合核苷酸之间的磷酸二酯键的更快),由此,生成在切断位点(可利用缺少5’-3’外切酶的链置换聚合酶而被扩展)之前的终端核苷酸上的自由3’羟基。在本文公开的方法的优选实施例中,“切断试剂”切割顶链磷酸二酯键的速率接近100%同时切割底链磷酸二酯键的速率接近0%。对本文描述方法有利的切断试剂可为酶,即可翻转多种底物分子的自身-再生催化剂或以等摩尔比例只翻转单一底物分子的非再生催化剂。
切口酶和双链的DNA并且切割双链双螺旋的一条链。本发明的方法中,切口酶切割顶链(这条链包括切断试剂识别位点的5’-3’序列)。切口酶可切割结合位点或切口酶识别位点的上游或下游。本文中本发明公开的特定实施例中,切口酶仅切割顶链和识别位点的3’端下游。在示例性实施例中,反应包括使用可切割或切断结合位点的下游(这样产品序列不包括切断位点)的切口酶。使用可切割结合位点下游的酶使得聚合酶更加轻易地扩展而不必置换切口酶。理想地,在和聚合酶相同的反应条件下,切口酶生效。示例性切口酶包括,但不限于N.Bst9I、N.BstSEI、Nb.BbvCI(NEB),Nb.Bpu10I(Fermentas)、Nb.BsmI(NEB)、Nb.BsrDI(NEB)、Nb.BtsI(NEB)、Nt.AlwI(NEB)、Nt.BbvCI(NEB)、Nt.Bpu10I(Fermentas)、Nt.BsmAI、Nt.BspD6I、Nt.BspQI(NEB)、Nt.BstNBI(NEB)和Nt.CviPII(NEB)。表1提供了切口酶识别位点的序列。
表1.切口酶识别序列
切口酶也包括通过修饰限制酶(NEB公式,2006年7月,卷1.2)的切割活性而生成的设计的切口酶。当限制酶结合到它们DNA中的识别序列,用来水解每条链、位于每个酶之内的两个催化剂位点驱动可平行进行的两个独立水解反应。可设计变化的限制酶,它仅水解双螺旋的一条链以生成被“切断”(3’-羟基,5’-磷酸盐)而不被切割的DNA分子。切口酶也可包括修饰的CRISPR/Cas蛋白质、转录活化剂类似物效应因子核酸酶(TALENs)和具有切口酶活性的锌-指状结构核酸酶。
切断扩增反应通常包括核苷,例如双脱氧核苷三磷酸(dNTPs)。反应也可在包括可检测部分的dNTPs(包括但不限定于放射性同位素标记(例如32P,33P,125I,35S)、酶(例如碱性磷酸酶)、荧光标记(例如异硫氰酸荧光素(FITC))、生物素、卵白素、洋地黄毒、抗原、半抗原或荧光染料)存在时进行。反应还包括特定盐和缓冲液,它们可为切口酶和聚合酶提供活性。
有利的是,当扩增反应过程中反应温度大约恒定时,切断扩增反应在大致等温条件下进行。因为温度不需要在较高温度和较低温度之间循环,所以切断扩增反应可在难以进行常规PCR的条件下进行。通常,反应大约在35℃和90℃(例如大约35、37、42、55、60、65、70、75、80或85℃)之间进行。有利的是,以很大精确度维持温度是不必要的。温度有一些变化性能是可接受的。
选择ΔΔG≤-15、-16、17、-18、-19、-20、-25、-30kcal/mole或更多的扩增反应的引物组。可通过增加一个或多个寡核苷酸(例如一个或多个引物和/或探针)浓度改变扩增反应的性能特征。引物的高浓度也支持形成引物-二聚体。在不同实施例中,引物的浓度是100、200、300、400、500、600、700、800、900、1000nM或更多。融化温度(Tm)和反应速率改良剂也可用来降低寡核苷酸的融化温度,例如(但不限定于)乙二醇和甘油。另外,DNA聚合酶反应速率改良剂(例如dNTP和镁浓度)也可用来改变反应速率。在特定实施例中,正反向引物的5’端尾部序列具有相同的核酸序列。
本发明也提供了设计切断试剂依赖性的等温链置换扩增试验而不用试验性筛选大量待选正向引物和/或待选反向引物的组合的方法。长度是35到70bp位于目标序列之内的的区认为是具有在中部长度是12到20bp序列,其Tm≥试验温度(例如~55℃)。根据上述标准,识别了直接位于中部(长度是15到20bp)的下游和上游、长度是12到20bp的相邻序列。所选择双链的上游和下游相邻序列的Tm之间偏离少于±3℃。通过将稳定二聚体-形成引物的5’端尾部区附接到12到20个碱基上游处的相邻序列的5’终端和12到20个碱基下游处的相邻序列互补链的5’终端形成目标特异性的正向和反向引物对。当和正向引物、反向引物和探针结合,驱动合成互补于探针的链的引物以大约1.1:1到10:1的摩尔比多于其他引物而过量。试验中引物的组合浓度不高于1000nM。试验设计方法也可用来将扩增子≤70bp的预先确定的PCR试验转换为切断剂依赖性等温链-置换扩增试验。
目标核酸分子
本发明的方法和组分对测试试样的目标核酸分子的扩增和/或鉴别有用。目标序列从几乎任意试样(包括目标核酸分子)中扩增,包括但不限定于包括真菌、孢子、病毒或细胞(例如原核细胞,真核细胞)的试样。在特定实施例中,本发明的组分和方法检测了细菌性溃疡病菌属溃疡、细菌性溃疡病菌属马铃薯环腐病菌、丁香假单胞菌番茄病致病变、野油菜黄单胞菌辣椒斑点病致病变、链格孢属、枝孢属、头孢镰刀菌、轮枝孢属大丽花、假单胞菌薄片镜蛤、胡萝卜软腐欧文氏菌属和青枯病。示例性测试试样包括体液(例如血液、血清、血浆、羊水、痰液、尿液、脑脊液、淋巴、撕裂液、粪便或胃液体)、组织提取物、培养基(例如细胞,举个例子病原体细胞生长的液体)、环境试样、农产品或其他食品以及它们的提取物和DNA鉴别标签。如果有需要,试样在进行利用任何标准方法(通常用来从生物试样中分离核酸分子)的切断扩增反应之前进行纯化。
在一个实施例中,引物扩增了病原体的目标核酸以探测试样中存在病原体。示例性病原体包括真菌、细菌、病毒和酵母。可通过鉴别核酸分子(在测试试样中编码病原体蛋白质,例如毒素)检测这样的病原体。示例性毒素包括,但不限定于黄曲毒素霍乱毒素、白喉毒素、沙门氏菌毒素、志贺毒素、梭菌肉毒毒素、内毒素和霉菌毒素。对于环境应用,测试试样可包括水、空气过滤器的液体提取物、土壤样本、建筑材料(例如干壁、吊顶板、壁纸、面料、壁纸和底板覆盖物)、环境化验标本或任何其试样。在一个实施例中,引物寡核苷酸将用作分子育种试验(针对增强,例如,植物耐旱性、植物的耐除草剂性或耐害虫捕食性)里内控的植物的目标核酸扩增。
目标核酸分子包括双链和单链核酸分子(例如所属领域已知的能和本文描述核酸分子杂合的DNA和其他核碱基聚合物)。适合利用本发明的可检测的寡核苷酸探针或引物检测的DNA分子包括,但不限定于双链的DNA(例如基因组DNA、质粒DNA/线粒体DNA、病毒DNA和合成双链DNA)。单链DNA目标核酸分子包括,例如,病毒DNA、cDNA和合成单链的DNA或其他所属领域已知类型的DNA。
通常,检测的目标序列的长度在10到100之间(例如10、15、20、25、30、35、40、45、50、60、70、80、90、100个核苷酸)的核苷酸。选择目标核酸分子的GC含量少于45%、50%、55%或60%。令人满意的是,选择目标核酸和切口酶,这样目标序列不包含任何切口酶的切断位点,它会包含于反应混合物中。
应用
利用本发明的引物的目标核酸扩增具有对目标核酸快速检测有利的特征(附图10)。这样的反应的特征在于([RFUMAX-RFUBL])、斜率([RFUMAX-RFUBL]/[TOSEA-TRFUmax]的高数值)、较早开始指数扩增阶段(TOSEA<10分钟)以及相同试样的复制试验反应之间的较低信号差异。在特定实施例中,TOSEA-TRFUmax≈3分钟。
本发明提供了实时监测等温扩增反应。需要快速检测时(例如20、15、10、9、8、7、6、5分钟或更少的条件下进行可检测性的扩增),本发明的组分和方法对于人体诊断有利。在特定实施例中,本发明提供了切断扩增反应在临床情况下人类诊断中的用途。在其他实施例中,当不能利用热循环设备或其价格昂贵,本发明提供了切断扩增反应试验在诊断现场工作中的用途。进一步地,在其他实施例中,当需要快速核酸扩增和检测时,本发明提供了切断扩增反应试验在学术背景中的用途。
可检测的寡核苷酸探针
本发明提供了在切断扩增反应中利用非扩增性、可检测的寡核苷酸探针(包括至少一个聚合酶捕获分子)检测目标核酸分子或其扩增子(例如将寡核苷酸着色的核苷酸变体或其他部分,它能结合目标核酸分子,但不能利用可检测的寡核苷酸探针作为目标支持聚合酶扩增)。不希望受限于理论,存在一个或多个部分(不允许聚合酶前进)可能导致寡核苷酸和非核酸骨架捕获聚合酶或通过拖延复制的聚合酶而捕获聚合酶(即C3-间隔区、受损DNA碱基,其他间隔区部分,O-2-Me碱基)。因此,在切断扩增反应过程中,这些结构阻止或减少探针的非正规扩增。这就将它们和常规检测探针区分,必须在切断扩增反应的末端加入以阻止它们的扩增。
常规检测探针在实时检测切断扩增反应中证明是不可行的。如果常规检测探针并入切断扩增反应,这些扩增检测探针同时和目标扩增。归因于反应开始的检测探针的原始分子数量,扩增这些检测分子掩饰了对正规目标扩增子的检测。
本发明提供了非扩增性、可检测的多核苷酸探针,它们包括至少一种聚合酶捕获分子。本发明的聚合酶捕获分子包括,但不限定于,利用复制DNA聚合酶封阻扩增但能实现合适杂合作用或将核苷酸间隔到目标分子或目标分子的扩增复制体的核苷酸变体或其他部分(由此防止扩增检测分子)。在一个实施例中,本发明的可检测寡核苷酸包括3个碳间隔区(C3间隔区),它会阻止或减少非常规扩增检测分子。
在一个实施例中,可检测寡核苷酸探针包括一个或多个修饰的核苷酸碱基(具有增强的结合于互补核苷酸的亲和性)。修饰的碱基示例包括,但不限定于,2’氟酰胺和2’OMe RNA酰胺(也起聚合酶捕获分子到的作用)。本发明的可检测寡核苷酸探针可利用不同着色荧光素合成并且可设计为和任何目标序列杂合。鉴于他们显著的特异性,本发明的非扩增的可检测的多核苷酸探针用来检测试样中的单一目标核酸分子,或和可检测的寡核苷酸探针(每一个和不同目标核酸分子结合)一起使用。因此,本发明非扩增性、可检测的寡核苷酸可用来检测相同反应中的一个或多个目标核酸分子,使得这些目标同时检测。本发明包括协同本文描述的可检测的寡核苷酸探针使用这样的荧光素。
非扩增性、可检测的多核苷酸探针的用途
非扩增性、可检测的多核苷酸探针对切断扩增反应中扩增和检测目标核酸分子有利。该方法涉及在大致等温条件下和合适缓冲液和dNTPs存在时,将目标核酸分子和聚合酶、两个引物(每一个特异性连接于目标核苷酸分子上的互补序列)、切口酶和可检测寡核苷酸探针接触;生成包括至少部分所述目标核酸分子的扩增子;以及基于荧光强度的反应过程中通过从反应中探针分子中检测寡核苷酸探针(实时杂合目标核算分子)而检测存在于反应中的目标核酸分子。
通常,切断扩增反应包括本发明的非扩增性、可检测的寡核苷酸探针,所述切断扩增反应包括:(1)目标核酸分子:(2)包括若干数量的寡核苷酸的两个引物(互补与目标核酸分子)和可利用切口酶切割的位点;(3)dNTPs;(4)链置换聚合酶;以及(5)切口酶。因此,本发明提供了利用这些组分检测目标核算分子的方法。
在硬件和/或软件里执行
本文描述的方法可在一般用途或特殊编程的硬件或软件上执行。例如,该方法可通过计算机可读介质而执行。因此,本发明也提供了(设置为执行根据本发明任何实施例的算法和/或方法)软件和/或计算机程序产品。众所周知,所属领域的技术人员知道如何设置软件,它可执行根据本发明任何实施例的算法和/或方法。计算机可读介质可为永久和/或有形的。例如,计算机可读介质可为非永存储器(例如随机存取存储器及其类似物)或永久存储器(例如只读存储器、硬盘、软盘、磁带、光盘、纸台、打孔卡以及类似物)。计算机可执行的指令可写入合适计算机语言或几种语言的组合。基础计算生物学方法在,例如Setubal和Meidanis等人,计算生物学方法介绍(PWS出版社,波士顿,1997);Salzberg,Searles,Kasif,(Ed.),分子生物学计算机方法,(艾斯维尔,阿姆斯特丹,1998);Rashidi和Buehler,生物信息学基础;生物科学和医学应用(CRC出版社,伦敦,2000)和Ouelette和Bzevani,生物信息学:基因和蛋白质分析的实用向导(Wiley&Sons,Inc.,第二版,2001)中描述。
本发明也可为不同目的使用不同计算机程序产品和软件,这样的探针设计,数据管理,分析和仪器操作(参见号为5,593,839、5,795,716、5,733,729、5,974,164、6,066,454、6,090,555、6,185,561、6,188,783、6,223,127、6,229,911和6,308,170的美国专利)。另外,本发明就具有优选实施例,它们包括提供遍历诸如美国序列号10/197,621、10/063,559(美国公开号20020183936)、10/065,856、10/065,868、10/328,818、10/328,872、10/423,403和60/482,389显示的互联网的网络内的基因信息的方法。
试剂盒
本发明也提供了扩增目标核酸分子的试剂盒。这样的试剂盒对扩增和检测取自主体的生物试样中的目标核酸有效。如本文描述的,本发明的试剂盒可包括,例如,一个或多个聚合酶,正向和反向引物和一个或多个切口酶。当一个目标将要扩增,一个或两个切口酶可包含于试剂盒。当多个目标序列将要扩增,为这些目标序列设计的引物包括相同切口酶的切断位点,然后一个或两个切口酶可包括其中。当引物通过不同切口酶识别,更多切口酶可包括于试剂盒,例如,举个例子,3个或更多。
一方面,本发明提供了扩增核酸的试剂盒,所述试剂盒包括DNA聚合酶、一级引物、二级引物、对引物内的切口酶结合位点具有特异性的切口酶以及三磷酸及脱氧核苷酸(dNTP’s)(例如在包含足够扩增的组分的缓冲溶液)。在不同实施例中,一级引物和二级引物每个具有互补于或大致互补于目标序列的3’末端特异性区序列(当末端识别区包括一个或多个2’端修饰的核苷酸)和包括位于3’末端特异性识别区序列(能和自身进行二聚作用,即自身-互补)上游的切口酶结合位点的5’末端尾部区。在特定实施例中,一个或多个引物具有引物-二聚体构型(例如通过大约在Tm加热和缓慢冷却生成)。
本发明的试剂盒也可包括一个或多个任意数量的单独容器、包、导管(例如<0.2ml、0.2ml、0.6ml、1.5ml、5.0ml、>5.0ml)、小瓶、微量滴定板(例如<96孔、96孔、384孔、1536孔、>1536孔)、ArrayTape和类似物里的一个或多个组分,或者组分可和这样的容器中的不同组合物而结合。在不同实施例中,试剂盒还包括能结合并且扩增参照序列的一对引物。在特定实施例中,试剂盒包括一个或多个引物-二聚体构型的引物(例如通过大约在Tm加热和缓慢冷却生成)。在其他实施例中,试剂盒包括含有引物的无菌容器;这样的容器可为盒子、安瓿、瓶子、小瓶、软管、袋子、保护套、吸塑装或所属领域已知的其他合适的容器。这样的容器可由塑料、玻璃、复合层压纸、金属箔或适合容纳核酸的其他材料制造。
试剂盒的组分,例如,可在出现在一个或多个容器中,例如,所有组分可在一个容器中,或例如,酶可存在于单独容器中和引物分开。组份,举个例子,可干燥(例如粉末)或放置在稳定缓冲液中(例如化学稳定,热力学稳定)。干燥组分,例如,通过冻干法、真空和离心辅助干燥和/或常压干燥而制备。在不同实施例中,聚合酶和切口酶在单独容器中以冻干形式存在并且引物在不同容器中干燥、冷冻干燥或在缓冲液中。在一些实施例中,聚合酶、切口酶和引物以冻干的形式存在于单独容器中。在其他实施例中,聚合酶和切口酶可分离到不同容器中。
试剂盒还包括,例如,反应中使用的dNTPs,或修饰的核苷酸,比色皿或反应使用的其他容器,或再水合冻干组分的小瓶水或缓冲液。使用的缓冲液可,例如,适合于聚合酶和切口酶活性。
本发明的试剂盒也可包括执行本文描述一个或多个说明和描述本文的一个或多个组分或试剂。说明和/或描述可印刷并且可包括于试剂盒插入物。试剂盒也可包括对提供这样说明或描述的互联网位置进行书面描写。
试剂盒还包括检测方法(例如实时或端点)使用的试剂,例如,举个例子,杂合探针或DNA结合染料。试剂盒还包括检测方法使用的试剂,例如,举个例子,FRET使用的试剂、横流装置、量油计、荧光染料、胶体金粒子、乳胶粒子、分子信标或聚苯乙烯微珠。检测组分可并入横流装置。横流装置可用在临床检测。
除非另有所指,本发明的实施利用分子生物学、微生物学、细胞生物学、生物化学和免疫学的常规技术(包括重组技术),它们都在技术人员的能力范围之内。这样的技术在文献(例如,《分子克隆》:试验手册,第2版(Sambrook,1989);《寡核苷酸合成方法》(Gait,1984);《动物细胞培养》(Freshney,1987);酶学方法,《实验免疫学手册》(Weir,1996);《哺乳动物细胞的转基因载体》(Miller and Calos,1987);《分子生物学实验指南》(Ausubel,1987);PCR:《聚合酶链反应》(Mullis,1994);《免疫学实验手册》(Coligan,1991))中完整解释。这些技术可用于生产本发明的多核苷酸和多肽,并且同样地可考虑制造和实施本发明。对特定实施例特别有用的技术将在下述部分中讨论。
提出下述示例以向所属领域的技术人员提供完整公开和描述如何实施和使用本发明的试验、筛选和治疗方法,并且不旨在限制发明人视作他们发明的范围。
示例
示例1.通过确定引物目标结合稳定性设计大豆凝集素等温DNA扩增系统
仅利用根据本发明的设计原理并且不借助引物设计测试,设计成功生效的检测大豆凝集素的等温DNA扩增试验(附图12)。
基于30到60bp序列窗口:
5’-ccaaggttctcattacctatgatgcctccaccagcctcttggttgcttctttggtctacccttcacagagaa-3’
中缺乏单核苷酸多态性(SNP’s),选择大豆凝集素基因的试验目标序列。粗体显示的是分别选自正向和反向引物设计的序列区。
为了选择正向引物(5’-ATTACCTATGATGCC-3’)的目标结合序列,结合到目标的正向链的稳定性和正向引物自身二聚作用的稳定性做如下比较:
正向引物-目标杂合体(PrTH)的ΔG25℃=-25.99kcal/mole;
引物-目标结合区自身二聚体(PrTBRHD)的ΔG25℃=-3.14kcal/mole;
ΔΔG25℃=ΔGPTH-ΔGPTBRHD=-22.85kcal/mole.
低ΔΔG(≤大约-16kcal/mole)表明正向引物能将目标核酸分子的互补链退火并且启动对之的合成。
为了选择反向引物(5’-ACCAAAGAAGCAAC-3’)的目标结合序列,结合到目标的反向引物的稳定性和反向引物自身-二聚体作用的稳定性做如下比较:
稳定性(ΔG)和反向引物5’-ACCAAAGAAGCAAC-3’的目标结合区的最近(ΔΔG)的相对稳定性如下确定:
正向引物-目标杂合体(PrTH)的ΔG25℃=-25.35kcal/mole;
引物-目标结合区自身二聚体(PrTBRHD)的ΔG25℃=-3.14kcal/mole;
ΔΔG25℃=ΔGPTH-ΔGPTBRHD=-22.21kcal/mole.
低ΔΔG(≤大约-16kcal/mole)表明反向引物能将目标核酸分子的互补链退火并且启动对之的合成。
切断扩增反应(50μl)包括0.3mM dNTPs,0.38U/ml Bst 2.0WarmStart DNA聚合酶(新英格兰生物学实验),0.15单位Nt.BstNBI(新英格兰生物学实验),250nM正向链,250nM反向链,利用CalRed(BioSearch)标识于5’终端和利用BHQ2(BioSearch)标识于3’终端的200nM分子信标探针以及野生大豆基因组DNA(1000个复制品)。引物和探针序列(通过BioSearch Inc.,Novato,CA合成)如下:
正向引物(“m”=2’-甲氧基核苷酸)
5’-ACGCGACTCGTCGACGAGTCGCGTATTACCTATGAmUmGmCmC-3’
反向引物(“m”=2’-甲氧基核苷酸)
5’-ACGCGACTCGTCGACGAGTCGCGTACCAAAGAAmGmCmAmAmC-3’
分子信标探针(“I”代表通用肌苷核苷酸)
5’-CalRed610-CGCGCTCCACCAICCTCTTGCGCG-BHQ2-3’
在IQ5热循环机(BioRad)内、于56℃将反应孵化大约10分钟。荧光信号记录在ROX通道上(激发态:575nm;发射态:602nm)。包含大豆gDNA(n=3)的反应生成了s状的曲线(附图13)。相比之下,不包含信号DNA(n=3)对照反应没有生成信号。开始指数扩增的时间大约是3分钟并且开始最大相对荧光单位的时间是大约6分钟。反应的指数扩增阶段的斜率确定为660RFU/分钟。
示例2.通过确定引物目标结合的稳定性设计沙门氏菌invA的等温DNA扩增系统
仅利用根据本发明的设计原理并且不借助引物设计测试,设计容易的、可操作的检测沙门氏菌invA的等温DNA扩增试验。
基于30到60bp序列窗口:
5’-ATACTCATCTGTTTACCGGGCATACCATCCAGAGAAAA-3’
中缺乏单核苷酸多态性(SNP’s),选择沙门氏菌invA基因的试验目标序列。粗体显示的是分别选自正向和反向引物设计的序列区。
为了选择正向引物(5’-ATACTCATCTGTTTACC-3’)的目标结合序列,结合到目标的正向链的稳定性和正向引物自身二聚作用的稳定性做如下比较:
正向引物-目标杂合体(PrTH)的ΔG25℃=-26.11kcal/mole;
引物-目标结合区自身二聚体(PrTBRHD)的ΔG25℃=-1.95kcal/mole;
ΔΔG25℃=ΔGPTH-ΔGPTBRHD=-24.16kcal/mole.
低ΔΔG(≤大约-16kcal/mole)表明正向引物能将目标核酸分子的互补链退火并且启动对之的合成。
为了选择反向引物(5’-TTTTCTCTGGATGG-3’)的目标结合序列,结合到目标的反向引物的稳定性和反向引物自身-二聚体作用的稳定性做如下比较:
稳定性(ΔG)和反向链5’-ACCAAAGAAGCAAC-3’的目标结合区的最近(ΔΔG)的相对稳定性如下确定:
正向引物-目标杂合体(PrTH)的ΔG25℃=-25.28kcal/mole;
引物-目标结合区自身二聚体(PrTBRHD)的ΔG25℃=-1.57kcal/mole;
ΔΔG25℃=ΔGPTH-ΔGPTBRHD=-23.71kcal/mole.
低ΔΔG(≤大约-16kcal/mole)表明反向引物能将目标核酸分子的互补链退火并且启动对之的合成。
切断扩增反应(26μl)包括0.3mM dNTPs,0.38U/ml Bst 2.0WarmStart DNA聚合酶(新英格兰生物学实验),0.15单位Nt.BstNBI(新英格兰生物学实验),250nM正向链,250nM反向链,利用CalRed(BioSearch)标识于5’终端和利用BHQ2(BioSearch)标识于3’终端的300nM分子信标探针以及野生大豆基因组DNA(1000复制品)。引物和探针序列(通过BioSearch Inc.,Novato,CA合成)如下:
正向引物1(“m”=2’-甲氧基核苷酸)
5’-ACGCGACTCGTCGACGAGTCGCGTATTACCTATGAmUmGmCmC-3’
反向引物(“m”=2’-甲氧基核苷酸)
5’-GGCTGACTCCTGCAGGAGTCAGCCTTTTCTCTGmGmAmUmGmG-3’
分子信标探针(“I”代表通用肌苷核苷酸)
5’-ACCTGTTTACCGGGCATACAAACAGGT-BHQ2-3’
在IQ5热循环机(BioRad)内、于56℃将反应孵化大约10分钟。荧光信号记录在ROX通道上(激发态:575nm;发射态:602nm)。包含大豆gDNA(n=3)的反应生成了s状的曲线(附图15)。相比之下,不包含信号DNA(n=3)对照反应没有生成信号。开始指数扩增的时间大约是3分钟并且开始最大相对荧光单位的时间是大约6分钟。反应的指数扩增阶段的斜率确定为660RFU/分钟。
附图16A和16B显示了试验优化的结果。
示例3.鉴别作为相对热动力参数(和为等温扩增试验设计的待选引物/探针组的性能相关)的ΔΔG。确定预测设计于“硅片上”的引物/探针组里引物寡核苷酸生效或失效的阈值。
分析5’端-3’端方向上包含自身-互补的第一区(具有切口酶识别序列的5’-尾部)和互补于第二区的目标序列的一组34个寡核苷酸引物的通常用于引物设计算法的大量参数,例如杂合双螺旋的融化温度(Tm)、%GC含量、序列长度和ΔG。独立确定了第一和第二引物区各自的所有参数。25个引物的子集属于待选引物/探针组,它们没有在试验筛选实验中生成探针-可检测的扩增产品。
分别利用X轴和Y轴的设计参数不同组合生成若干二维基质点(附图17A-17H),目的是鉴别参数组合,其中失效试验引物的数据点可分别从功能性试验引物的数据点群聚得到。如附图17B-17H的点所显示的,没有现有技术(设计引物)使用的标准设计参数的组合从在二维点基质中的非功能性引物中生成可辨识的功能性分离。归因于功能性和非功能性寡核苷酸引物中的标准参数值的广泛重叠范围,两个引物群的数据点,如所期望的,广泛地重叠于这些点中。
令人惊奇的是,如本申请发明人定义的,仅仅新的相对热动力参数的ΔΔG生成了基质(其中关联于筛选测试的引物组实验效果,功能性和非功能性引物的数据点分别群聚)。附图17A的图显示了基质,它的X轴和Y轴分别提供了描绘互补第一引物区的ΔΔG值的比例和描绘目标-互补第二引物区的ΔΔG值的比例。所有失效试验引物具有第二区/目标双螺旋(多数情况下)或第一区自身-互补双螺旋(一种情况下)的少于-15kcal/mol的ΔΔG值。因此,大约-15kcal/mol的ΔΔG值变成这种区分功能性和非功能性引物的寡核苷酸数据组的实验性阈值。
ΔΔG是测量差异的相关参数,即,在室温和常压下于动态平衡中,形成需要的寡核苷酸结构(特定引物/目标杂合体和第一区自身二聚体)热动力学优选性相对形成大量预测的可选结构的优选性的优势。令人惊奇的是,待选引物寡核苷酸设计为硅片时,这种ΔG优势(ΔΔG)证明是可预测试验成功的参数。计算得到的ΔΔG作为功能性等温试验的登记评分和预测指标的用途减少实践下述描述和测试等温试验(为了检测大豆凝集素基因和沙门氏菌invA基因)的示例。第一次利用计算的ΔΔG值仅在硅片上筛选待选引物和探针。每中情况下,仅仅用试验方法选择和测试单引物/探针组。初次试验中进行两种功能性试验而不费时并且成本高昂的筛选大量待选引物/探针组。
其他实施例
从上述的描述中显而易见的是本文描述的发明的不同用法和条件可采用变型和变体。这样的实施例也在下述权利要求的范围中。
引用一系列本文对变量的任何定义里元素包括将变量定义为任意单一元素或所列元素的组合(或子组合)。引用本文实施例包括作为单一实施例或和任意其他实施例或其部分的组合的实施例。
本申请可涉及国际专利申请号PCT/US2013/035750,于2013年4月9日申请,其要求享有美国专利号61/621,975,于2012年4月9日申请的美国临时申请的权利,它的内容通过引用并入本文。
本申请可涉及国际专利申请号PCT/US2011/047049,于2011年8月9日申请,其要求享有美国专利号61/621,975,于2010年8月13日申请的美国临时申请的权利,它的内容通过引用并入本文。
和每个独立专利和公开特异性和单独地表明通过引用并入程度相同,本说明书提及的所有专利和公开通过引用并入本文。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种引物组及其在扩增siv/shiv基因组中的应用与试剂盒的制作方法
- 检测f8基因突变的扩增引物、试剂盒及方法
- 拟茎点霉rpb2基因扩增引物及其设计方法和应用
- 一种马来穿山甲线粒体Cox3基因序列的扩增引物及鉴定方法
- 拟茎点霉gpdh基因扩增引物及其设计方法和应用
- 甲型流感病毒全基因组扩增方法及使用的复合引物和试剂盒的制作方法
- 用于检测2型糖尿病视网膜病变的miR-2116-5p分子标记物及其扩增引物和应用
- 用于检测2型糖尿病视网膜病变的miR-3197分子标记物及其扩增引物和应用
- 一种用于鱼类线粒体全基因组扩增的引物、试剂盒及扩增方法
- 用Alu重复序列基因扩增引物且无需DNA抽提的检测血浆游离DNA的定量PCR方法