一种适用于土曲霉的表达载体及其制备方法与流程
本发明属于生物技术领域,尤其涉及一种适用于土曲霉的表达载体及其制备方法。
背景技术:
土曲霉属于散囊菌纲,散囊菌霉目,曲霉科,拉丁名为Aspergillus terreus。菌落为土黄色,具短绒毛,似细沙分布于培养基上;营养菌丝树根状,丛生密集,分叉,有隔,分生孢子梗较短;生长较快。土曲霉的这些特性便于基因在其中大量且稳定地表达。因此,土曲霉在用于基因表达的研究方面具有巨大的应用前景。
然而,现有的适用于土曲霉的表达载体多为真菌通用的载体,多采用的是构巢曲霉的3-磷酸甘油醛脱氢酶(Glyceraldehyde一3-phosphate dehydrogenase,gpd)基因的启动子,而非专门针对土曲霉,这些表达载体在土曲霉中表达能力较弱;此外,这些表达载体没有一个蛋白标记,不能用作信号通路的研究。
技术实现要素:
为解决上述技术问题,本发明提供了一种适用于土曲霉的表达载体及其制备方法。
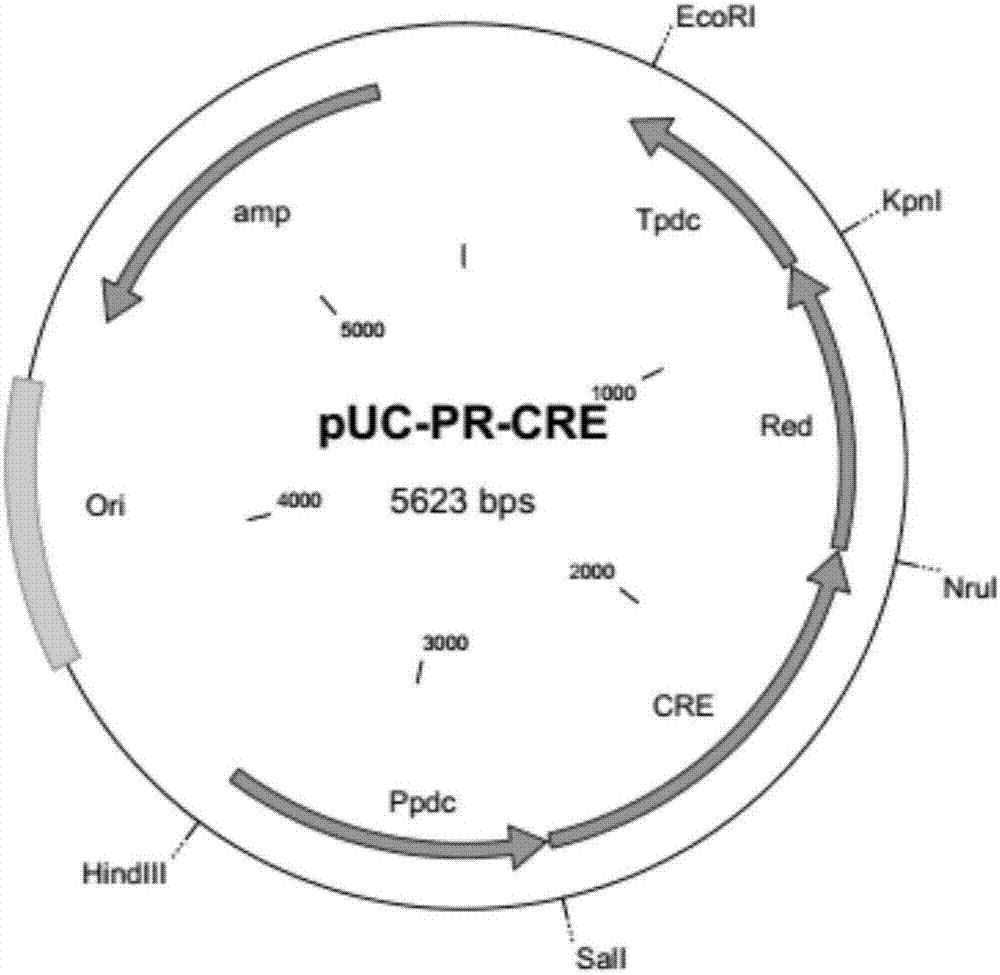
本发明是这样实现的,一种适用于土曲霉的表达载体,所述表达载体由在pUC19的多克隆位点处插入土曲霉基因中的丙酮酸脱羧酶基因的启动子和终止子而获得,其中启动子序列为SEQ ID NO.1中的第2241-2990位,终止子序列为SEQ ID NO.1中的第3721-4230位。
进一步地,所述启动子和终止子之前插入有一段红色荧光蛋白基因,所述红色荧光蛋白基因的序列为SEQ ID NO.1中的第3034-3715位。
进一步地,所述红色荧光蛋白基因产生的红色荧光由波长为500~560nm的绿光激发而得。
进一步地,所述载体在所述启动子序列与所述红色荧光蛋白序列之间存在Sal I、Nru I两个酶切位点。
进一步地,所述表达载体在所述启动子的序列的上游及所述终止子的序列的下游存在通用引物M13的结合位点。
进一步地,所述表达载体的基因序列如SEQ ID NO.1所示。
本发明还提供了一种上述所述的表达载体的制备方法,包括以下步骤:
以土曲霉基因组为模板,Ppdc-F、Ppdc-R为引物进行PCR扩增,得到土曲霉基因中的丙酮酸脱羧酶基因的pdc启动子序列;
将所述土曲霉基因中的丙酮酸脱羧酶基因的pdc启动子序列转化至JM109中,扩大培养,并提取质粒;
将提取的质粒与pUC19先后通过HindIII和Sse8387I分步酶切,得到有可互补的粘性末端的pdc启动子序列和pUC19;
将所述有可互补的粘性末端的pdc启动子序列和pUC19进行重组,得到含有启动子序列的重组载体;
按照上述步骤,依次将启动子序列、终止子序列、红色荧光蛋白基因导入所述重组载体中,获得所述表达载体。
进一步地,所述终止子序列导入所述重组载体的过程为:
以土曲霉基因组为模板,Tpdc-F、Tpdc-R为引物进行PCR扩增,得到土曲霉基因中的丙酮酸脱羧酶基因的pdc终止子序列;
将土曲霉基因中的丙酮酸脱羧酶基因的pdc终止子序列转化至JM109中,扩大培养,并提取质粒。
将提取的质粒与已插入了启动子的pUC19先后通过KpnI和EcoRI分步酶切,得到有可互补的粘性末端的pdc终止子序列和酶切载体pUC19;
将上一步得到的所述有可互补的粘性末端的pdc终止子和酶切载体pUC19进行重组,得到同时含有所述启动子和终止子序列的重组载体。
进一步地,所述红色荧光蛋白基因导入所述重组载体的过程为:
以红色荧光蛋白为模板,DsRed-F、DsRed-R为引物进行PCR扩增,得到所述红色荧光蛋白基因序列;
将所述红色荧光蛋白基因序列转化至JM109中,扩大培养,并提取质粒;
将提取的质粒与已插入启动子、终止子序列的pUC19先后通过SalI和Sse8387I分步酶切,得到有可互补的粘性末端的红色荧光蛋白基因序列和酶切载体pUC19;
将上一步得到的红色荧光蛋白基因序列、酶切载体pUC19进行重组,得到所述表达载体。
本发明与现有技术相比,有益效果在于:本发明实施例提供的适用于土曲霉的表达载体无需诱导,可稳定表达;解决了其他表达载体在土曲霉中表达能力弱的问题,且能够通过观察红色荧光来进行土曲霉中信号通路的研究。在大肠杆菌中稳定性复制和保持、便于DNA纯化分离操作的特质。
附图说明
图1是本发明实施例提供的适用于土曲霉的表达载体构建示意图;
图2是本发明实施例1提供的表达载体的构建示意图;
图3是本发明实施例3提供的重组的表达载体转化至土曲霉后的表达结果示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参见图1,本发明实施例提供了一种适用于土曲霉的表达载体,所述表达载体由在pUC19的多克隆位点处插入土曲霉(Aspergillus terreus)基因中的丙酮酸脱羧酶基因(pyruvate decarboxylase,pdc,GeneID:4320296)的启动子和终止子而获得,所述表达载体的基因序列如SEQ ID NO.1所示,其中启动子序列为SEQ ID NO.1中的第2241-2990位,终止子序列为SEQ ID NO.1中的第3721-4230位。
本发明实施例提供的适用于土曲霉的表达载体,无需诱导,可在土曲霉中稳定表达;解决了其他表达载体在土曲霉中表达能力弱的问题。本表达载体存在原核生物基因质粒的复制起始位点(原核生物基因质粒的复制起始位点为SEQ ID NO.1中的第1232-1820位),在大肠杆菌中可稳定复制、保持,便于质粒DNA的分离、纯化;存在氨苄青霉素的抗性基因(氨苄青霉素抗性基因为SEQ ID NO.1中的第201-1061位),便于挑取存在本载体的大肠杆菌。本发明所提供的表达载体用以插入需研究的目的基因,待其转化入土曲霉中,可表达生成融合蛋白。
所述启动子和终止子之前插入有一段红色荧光蛋白基因,所述红色荧光蛋白基因的序列为SEQ ID NO.1中的第3034-3715位。通过观察转化子的红色荧光,确定待研究的基因在土曲霉中的作用位置,从而研究该蛋白在土曲霉中的作用。
具体地,所述红色荧光蛋白基因产生的红色荧光有波长为500~560nm的绿光激发而得。
所述载体在所述启动子序列与所述红色荧光蛋白序列之间存在Sal I、Nru I两个酶切位点,可双酶切,以插入目的基因。所述载体在所述启动子的序列的上游及所述终止子的序列的下游存在通用引物M13的结合位点,便于重组载体构建过程中的测序验证。
所述载体主要用于土曲霉中基因的功能研究,亦可用于其他丝状真菌的研究。通过Sal I、Nru I酶切或者反向PCR(聚合酶链式反应,Polymerase Chain Reaction)的方法使载体线性化。目的基因通过相同酶切,使其带有对应的粘性末端。通过连接酶使目的基因重组到载体上,转化到大肠杆菌中,筛选后扩大培养并提取重组质粒。转化入土曲霉或者其他丝状真菌中,通过500~560nm波长的绿光激发,观察目的基因所表达的肽链在土曲霉中的位置(肽链将会产生红色荧光),从而发现该基因表达的肽链在土曲霉中的位置,进而研究其功能。
具体地,所述载体的全长为4631bp,GC含量为51.5%。
所述表达载体的基因序列如下:
GACGAAAGGGCCTCGTGATACGCCTATTTTTATAGGTTAATGTCATGATAATAATGGTTTCTTAGACGTCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTTAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGGCAAGAGCAACTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAACACTGCGGCCAACTTACTTCTGACAACGATCGGAGGACCGAAGGAGCTAACCGCTTTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCAACAACGTTGCGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTA ACTGTCAGACCAAGTTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTTCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGCTCGCCGCAGCCGAACGACCGAGCGCAGCGAGTCAGTGAGCGAGGAAGCGGAAGAGCGCCCAATACGCAAACCGCCTCTCCCCGCGCGTTGGCCGATTCATTAATGCAGCTGGCACGACAGGTTTCCCGACTGGAAAGCGGGCAGTGAGCGCAACGCAATTAATGTGAGTTAGCTCACTCATTAGGCACCCCAGGCTTTACACTTTATGCTTCCGGCTCGTATGTTGTGTGGAATTGTGAGCGGATAACAATTTCACACAGGAAACAGCTATGACCATGATTACGCCAAGCTTGTACAGACAAGAAACGCGTCAGATTAGCGCTGGTTGGTTCGGTCGATGATATGACCAGGATGGAGCAGAGACGGTAGTTCTCCGATGGTCTGTGGACAATCGCAGGTGGTGATGCTCCGCGGGCGGAAGAATCGATAAATTGCAGAGGAGCAGCTGTCCCGTTTGGGACTAGGGCGGGGCCATCATCCCACCCCGGCACATTAAGGATGATTTTCATCCATGCCACCATGAGCTGACAGTCATCCGATGATCATGGATCCAATATACCAGTGGCTGGCCCCATTGCCTTTAAACCAGAAGGCTCTAGGCCCGTCGTATTGGATTCC AGACATCTGATCTGCGGGTAGCTGTGATGATCGGCCTACGTCTACAGGTTCGGTCTCACCACGGCTTCTATTCCGGCCGAATCACTACGGGCCGAAGTTCTACGGAGTACATAGGATGGTCTTATTCGGGATGTCTTATCGTGGTAGGTAATTATAGCAGTTGCTCCAATCGTACGGTGTATACGCATGGTAACTCCCGAAGTATCACCTTGTTGATGGGAGAAGACACTCACCGGGGCATGACATCACGGTGTCTCCATGACGTACAACACAACAGAAAGCCCCTCCGAAAGCAGTATTATGGCTGACTTGCTATATATTCTCTCACTCACTCCCCTTCTCATATTCCTTCTCACTCAGGGGCAACTTTCCATCTGACCCAAAATCTCATTCCCCTTTCCCAACTTATTTAGAAACCTCGTGATCGCGACTCCAGAGCTCTGTCTTCTTCCCACCTGCAGGTCGACATGGTGCGCTCCTCCAAGAACGTCATCAAGGAGTTCATGCGCTTCAAGGTGCGCATGGAGGGCACCGTGAACGGCCACGAGTTCGAGATCGAGGGCGAGGGCGAGGGCCGCCCCTACGAGGGCCACAACACCGTGAAGCTGAAGGTGACCAAGGGCGGCCCCCTGCCCTTCGCCTGGGACATCCTGTCCCCCCAGTTCCAGTACGGCTCCAAGGTGTACGTGAAGCACCCCGCCGACATCCCCGACTACAAGAAGCTGTCCTTCCCCGAGGGCTTCAAGTGGGAGCGCGTGATGAACTTCGAGGACGGCGGCGTGGTGACCGTGACCCAGGACTCCTCCCTGCAGGACGGCTGCTTCATCTACAAGGTGAAGTTCATCGGCGTGAACTTCCCCTCCGACGGCCCCGTAATGCAGAAGAAGACCATGGGCTGGGAGGCCTCCACCGAGCGCCTGTACCCCCGCGACGGCGTGCTGAAGGGCGAGATCCACAAGGCCCTGAAGCTGAAGGACGGCGGCCACTACCTGGTGGAGTTCAAGTCCATCTACATGGCCAAGAAGCCCGTGCAGCTGCCCGGCTACTACTACGTGGACTCCAAGCTGGACATCACCTCCCACAACGAGGACTACACCATCGTGGAGCAGTACGAGCGCACCGAGGGCCGCCACCACCTGTTCCTGTAGGGTACCTCGGCGGAATAGTGTCGGACCCCCGGTGTTTTAAGAATCTTTTTTCTCTCCTCCTGTTTGTCTATCTTAATATGAAACGGAACACGGCCAGGGTATACGCCCGCATTGTCATAGAAAACGTCTCAATCAGAACATCATGACCACCATGGAGTACAGCTAAAATGGAGCCGAGTTGAAAGCTCAGCATGAGCATGTTTACAGCTACTGATTAAAATTCATACGAGTTGATGCATCCTTCTCTTCGCGTAGTGAAATAAACATATATATATATATACCTTATGCAACTGGGTTGTAAAGTTCCGATAGGAGATACAGGGACCTGAAGCCTTTTATCGCTTGTCCCGAGAAGCTC ACCACGGCTTGAAGAGTATCGTGACGGCTTATTGTGATAGATCTTATATTAACTCTTCCTTTGTTTCAGTTTTGCCTCACCACTGCATATACACAGGGGTTGCTTGGCATCTTGGGTAAATTTACGATTATTTTCTCCAGACTGTATATTAATCCAGAGAATTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCAACTTAATCGCCTTGCAGCACATCCCCCTTTCGCCAGCTGGCGTAATAGCGAAGAGGCCCGCACCGATCGCCCTTCCCAACAGTTGCGCAGCCTGAATGGCGAATGGCGCCTGATGCGGTATTTTCTCCTTACGCATCTGTGCGGTATTTCACACCGCATATGGTGCACTCTCAGTACAATCTGCTCTGATGCCGCATAGTTAAGCCAGCCCCGACACCCGCCAACACCCGCTGACGCGCCCTGACGGGCTTGTCTGCTCCCGGCATCCGCTTACAGACAAGCTGTGACCGTCTCCGGGAGCTGCATGTGTCAGAGGTTTTCACCGTCATCACCGAAACGCGCGA。
本发明实施例提供的适用于土曲霉的表达载体,可使需要研究的基因在土曲霉中大量且稳定的表达,并使其表达的肽链中存在一段红色荧光蛋白,易于观察研究基因的功能。重组载体构建简单且便于筛选、保存。
本发明实施例还提供了上述表达载体的制备方法,包括以下步骤:
以土曲霉基因组为模板,Ppdc-F、Ppdc-R为引物进行PCR扩增,得到土曲霉基因中的丙酮酸脱羧酶基因的pdc启动子序列;
将所述土曲霉基因中的丙酮酸脱羧酶基因的pdc启动子序列转化至JM109(感受态细胞)中,扩大培养,并提取质粒;
将提取的质粒与pUC19先后通过HindIII和Sse8387I分步酶切,得到有可互补的粘性末端的pdc启动子序列和pUC19;
将所述有可互补的粘性末端的pdc启动子序列和pUC19进行重组,得到含有启动子序列的重组载体;
按照上述步骤,依次将所述终止子序列、红色荧光蛋白基因导入所述重组载体中,获得所述表达载体。
所述制备方法具体包括以下步骤:
1、以土曲霉基因组为模板,Ppdc-F、Ppdc-R为引物进行PCR扩增,得到土曲霉基因中的丙酮酸脱羧酶基因的pdc启动子序列(Ppdc-F、Ppdc-R、土曲霉基因组各1μl,Premix Taq 10μl、ddH2O 7μl;92℃变性,55℃退火,72℃延伸,35循环);
2、将上述PCR扩增产物使用omega胶回收试剂盒进行回收,得到浓度约为50ng/μl的CRE溶液;
3、将pdc启动子溶液、pMD-19、DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min;
4、热激法将连接产物转化至JM109中,扩大培养,并提取质粒;
5、提取的质粒与pUC19先后通过HindIII和Sse8387I分步酶切,得到有可互补的粘性末端的pdc启动子序列和pUC19;
6、将第5步得到的pdc启动子、pUC19和DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min。重复第4步,得到重组的表达载体。
pdc终止子及红色荧光蛋白序列的插入同以上一步骤,使用引物和酶切位点见表1。
表格1 pUC-PR载体构建所用引物及酶切位点
具体地,所述终止子序列导入所述重组载体的过程为:
以土曲霉基因组为模板,Tpdc-F、Tpdc-R为引物进行PCR扩增,得到土曲霉基因中的丙酮酸脱羧酶基因的pdc终止子序列;
将土曲霉基因中的丙酮酸脱羧酶基因的pdc终止子序列转化至JM109中,扩大培养,并提取质粒;
将提取的质粒与已插入了启动子的pUC19先后通过KpnI和EcoRI分步酶切,得到有可互补的粘性末端的pdc终止子序列和酶切载体pUC19;
将上一步得到的所述有可互补的粘性末端的pdc终止子和酶切载体pUC19进行重组,得到同时含有所述启动子和终止子序列的重组载体。
上述过程具体为:
1、以土曲霉基因组为模板,Tpdc-F、Tpdc-R为引物进行PCR扩增,得到土曲霉中的丙酮酸脱羧酶基因的pdc终止子序列(Tpdc-F、Tpdc-R、土曲霉基因组各1μl,Premix Taq 10μl、ddH2O 7μl;92℃变性,55℃退火,72℃延伸,35循环);
2、将上述PCR扩增产物使用omega胶回收试剂盒进行回收,得到浓度约为50ng/μl的CRE溶液;
3、将pdc终止子溶液、pMD-19、DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min;
4、热激法将连接产物转化至JM109中,扩大培养,并提取质粒;
5、提取的质粒与已插入了启动子的pUC19先后通过KpnI和EcoRI分步酶切,得到有可互补的粘性末端的pdc终止子序列和pUC19;
6、将第5步得到的pdc终止子、上一步的酶切载体和DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min;重复第4步,得到重组的表达载体。
具体地,所述红色荧光蛋白基因导入所述重组载体的过程为:
以红色荧光蛋白为模板,DsRed-F、DsRed-R为引物进行PCR扩增,得到所述红色荧光蛋白基因序列;
将所述红色荧光蛋白基因序列转化至JM109中,扩大培养,并提取质粒;
将提取的质粒与已插入启动子、终止子序列的pUC19先后通过SalI和Sse8387I分步酶切,得到有可互补的粘性末端的红色荧光蛋白基因序列和酶切载体pUC19;
将上一步得到的红色荧光蛋白基因序列、酶切载体pUC19进行重组,得到所述表达载体。
上述过程具体为:
1、以红色荧光蛋白为模板,DsRed-F、DsRed-R为引物进行PCR扩增,得到所述红色荧光蛋白基因序列(DsRed-F、DsRed-R、土曲霉基因组各1μl,Premix Taq 10μl、ddH2O 7μl;92℃变性,55℃退火,72℃延伸,35循环);
2、将上述PCR扩增产物使用omega胶回收试剂盒进行回收,得到浓度约为50ng/μl的CRE溶液;
3、将所述CRE溶液、pMD-19、DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min;
4、热激法将连接产物转化至JM109中,扩大培养,并提取质粒;
5、提取的质粒与已插入启动子、终止子序列的pUC19先后通过SalI和Sse8387I分步酶切,得到有可互补的粘性末端的红色荧光蛋白基因序列和pUC19;
6、将第5步得到的红色荧光蛋白基因序列、酶切载体和DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min;重复第4步,得到所述表达载体。
本发明实施例提供的上述所述的适用于土曲霉的表达载体的制备方法,可以轻松获得本发明实施例提供的适用于土曲霉的表达载体,由此获得相应的功能。
本发明实施例还提供了一种将上述所述的表达载体转化至土曲霉的方法,包括以下步骤:
以目的基因引物序列为引物进行PCR扩增,得到目的基因序列;
将所述目的基因序列转化至JM109中,扩大培养,并提取质粒;
将提取的质粒与土曲霉基因先后通过SalI和NruI分步酶切,得到有可互补粘性末端的目的基因序列和pUC-PR;
将有可互补粘性末端的目的基因序列和pUC-PR进行重组。
以下结合具体实施例对本发明的技术方案进行详细说明。
实施例1将土曲霉cre基因插入到该表达载体中
材料:CRE-F(10μM/L),CRE-R(10μM/L),DNA聚合酶(Premix Taq,购自takara),土曲霉基因组溶液(约200ng/μL),核酸内切酶(NruI、SalI,购自takara),T载体(pMD19,购自takara),DNA连接酶(DNA Ligation Kit,购自takara),大肠杆菌感受态细胞JM109,omega胶回收试剂盒,omega质粒小提试剂盒。
过程如下:
1、以土曲霉基因组为模板,CRE-F、CRE-R为引物进行PCR扩增,得到土曲霉CRE基因序列(CRE-F、CRE-R、土曲霉基因组各1μl,Premix Taq 10μl、ddH2O 7μl;92℃变性,55℃退火,72℃延伸,35循环)
2、将PCR扩增产物使用omega胶回收试剂盒进行回收,得到浓度约为50ng/μl的CRE溶液。
3、将CRE溶液、pMD-19、DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min。
4、热激法将连接产物转化至JM109中,扩大培养,并提取质粒。
5、提取的质粒与本载体先后通过SalI和NruI分步酶切,得到有可互补的粘性末端的CRE基因序列和pUC-PR。
6、将第5步得到的CRE基因、pUC-PR和DNA Ligation Kit溶液I以4:1:5的比例混匀,于16℃反应30min。重复第4步,得到重组的表达载体(见附图2)。
附:CRE-F引物序列:5’-GTCGACATGCCGCCACCAGCCTCTGC-3’;
CRE-R引物序列:5’-TCGCGATCACTGGCACCCAGAGGCCG-3’。
实施例2重组载体转化至土曲霉
材料:土曲霉孢子培养基:葡萄糖20g/L、麦芽汁10g/L。蛋白胨1g/L、吐温80 2g/L。
STC溶液:山梨醇109.3g,1M Tris·HCL溶液5mL,1M CaCl2溶液25mL,去离子水定容至500mL,121℃高压灭菌20min。
1M MgSO4溶液:硫酸镁60g,用去离子水定容至500mL,121℃高压灭菌20min。
60%PEG4000溶液:1M氯化钙溶液1mL,1M Tris·HCL溶液200μl。
1、取约108个孢子接种于50mL孢子培养基中,于250mL锥形瓶中28℃,250r/min,培养8小时。
2、将培养液于50mL离心管中5000rpm离心10min,去上清液。
3、加入20mL的1M MgSO4溶液,并吹打均匀,5000rpm离心10min,取上清液。
4、重复上一步。
5、加入10mL溶壁酶(2g溶壁酶溶解于10mL 1M MgSO4溶液中),并吹打均匀,于250mL的锥形瓶中28℃,80r/min培养12h。
6、取培养液于50mL离心管中,加入20mL的STC,轻柔吹打均匀,于4℃,5000rpm离心10min,去上清。
7、加入30mL的STC,轻柔吹打均匀,再次离心。
8、弃上清液,加入700μl的STC,轻柔吹打均匀,取200μl加入已灭菌的1.5mL的离心管中。
9、加入质粒Ppdc-DsRed-Tpdc和pAN7-1各1μg后,于冰上静置30min。
10、48℃热激2min后,加入5μl 60%的PEG4000,混匀后静置20min。
11、将溶液转移至50mL离心管中,加入2mL 60%的PEG4000,混匀后静置5min。
12、加入30mL的STC,4℃,5000rpm离心10min,去上清液。
13、吹打均匀后加入10mL原生质体再生培养基(5mL的2倍浓度STC,1mL的10倍浓度葡萄糖,4mL的2.5倍浓度基本培养基)。于250mL的锥形瓶张红,28℃,70r/min培养12小时。
14、培养液加入20mL的STC溶液于50mL的离心管中,5000rpm离心10min。
15、加入1mL的STC溶液,吹打均匀,取200μl涂布于土曲霉抗性平板上,28℃培养2~3d后挑取单菌落,于土曲霉抗性平板再次筛选。
16、培养2~3d后挑取单菌落于土曲霉平板28℃培养7天后,用无菌水洗脱孢子保存。
实施例3重组的表达载体转化至土曲霉后观察
参见图3,其中,A为用可见光观察转化子,可见光下找到菌丝,作为实验组;B为可见光观察未转化土曲霉,可见光下找到菌丝,作为阴性对照;C为用绿光激发转化子,可观察到整个菌丝体表达红色荧光;D为用绿光激发未转化土曲霉,整个视野无法观察到红色荧光。从图3中可以看出:图B和D作为阴性对照说明土曲霉本身在绿光激发下不能被激发红光;图A和C作为实验组经pUC-PR-CRE转化入土曲霉中,土曲霉在绿光激发下激发红光,并在土曲霉菌丝体各个部位表达。由图3可得出结论,土曲霉基因CRE编码的表达产物可在土曲霉整个菌丝体中进行表达,pUC-PR可通过观察红色荧光来进行土曲霉中信号通路研究。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
SEQUENCE LISTING
<110> 深圳大学
<120> 一种适用于土曲霉的表达载体及其制备方法
<130> 9
<160> 9
<170> PatentIn version 3.5
<210> 1
<211> 4631
<212> DNA
<213> 人工序列
<223> 适用于土曲霉的表达载体的基因序列
<400> 1
gacgaaaggg cctcgtgata cgcctatttt tataggttaa tgtcatgata ataatggttt 60
cttagacgtc aggtggcact tttcggggaa atgtgcgcgg aacccctatt tgtttatttt 120
tctaaataca ttcaaatatg tatccgctca tgagacaata accctgataa atgcttcaat 180
aatattgaaa aaggaagagt atgagtattc aacatttccg tgtcgccctt attccctttt 240
ttgcggcatt ttgccttcct gtttttgctc acccagaaac gctggtgaaa gtaaaagatg 300
ctgaagatca gttgggtgca cgagtgggtt acatcgaact ggatctcaac agcggtaaga 360
tccttgagag ttttcgcccc gaagaacgtt ttccaatgat gagcactttt aaagttctgc 420
tatgtggcgc ggtattatcc cgtattgacg ccgggcaaga gcaactcggt cgccgcatac 480
actattctca gaatgacttg gttgagtact caccagtcac agaaaagcat cttacggatg 540
gcatgacagt aagagaatta tgcagtgctg ccataaccat gagtgataac actgcggcca 600
acttacttct gacaacgatc ggaggaccga aggagctaac cgcttttttg cacaacatgg 660
gggatcatgt aactcgcctt gatcgttggg aaccggagct gaatgaagcc ataccaaacg 720
acgagcgtga caccacgatg cctgtagcaa tggcaacaac gttgcgcaaa ctattaactg 780
gcgaactact tactctagct tcccggcaac aattaataga ctggatggag gcggataaag 840
ttgcaggacc acttctgcgc tcggcccttc cggctggctg gtttattgct gataaatctg 900
gagccggtga gcgtgggtct cgcggtatca ttgcagcact ggggccagat ggtaagccct 960
cccgtatcgt agttatctac acgacgggga gtcaggcaac tatggatgaa cgaaatagac 1020
agatcgctga gataggtgcc tcactgatta agcattggta actgtcagac caagtttact 1080
catatatact ttagattgat ttaaaacttc atttttaatt taaaaggatc taggtgaaga 1140
tcctttttga taatctcatg accaaaatcc cttaacgtga gttttcgttc cactgagcgt 1200
cagaccccgt agaaaagatc aaaggatctt cttgagatcc tttttttctg cgcgtaatct 1260
gctgcttgca aacaaaaaaa ccaccgctac cagcggtggt ttgtttgccg gatcaagagc 1320
taccaactct ttttccgaag gtaactggct tcagcagagc gcagatacca aatactgttc 1380
ttctagtgta gccgtagtta ggccaccact tcaagaactc tgtagcaccg cctacatacc 1440
tcgctctgct aatcctgtta ccagtggctg ctgccagtgg cgataagtcg tgtcttaccg 1500
ggttggactc aagacgatag ttaccggata aggcgcagcg gtcgggctga acggggggtt 1560
cgtgcacaca gcccagcttg gagcgaacga cctacaccga actgagatac ctacagcgtg 1620
agctatgaga aagcgccacg cttcccgaag ggagaaaggc ggacaggtat ccggtaagcg 1680
gcagggtcgg aacaggagag cgcacgaggg agcttccagg gggaaacgcc tggtatcttt 1740
atagtcctgt cgggtttcgc cacctctgac ttgagcgtcg atttttgtga tgctcgtcag 1800
gggggcggag cctatggaaa aacgccagca acgcggcctt tttacggttc ctggcctttt 1860
gctggccttt tgctcacatg ttctttcctg cgttatcccc tgattctgtg gataaccgta 1920
ttaccgcctt tgagtgagct gataccgctc gccgcagccg aacgaccgag cgcagcgagt 1980
cagtgagcga ggaagcggaa gagcgcccaa tacgcaaacc gcctctcccc gcgcgttggc 2040
cgattcatta atgcagctgg cacgacaggt ttcccgactg gaaagcgggc agtgagcgca 2100
acgcaattaa tgtgagttag ctcactcatt aggcacccca ggctttacac tttatgcttc 2160
cggctcgtat gttgtgtgga attgtgagcg gataacaatt tcacacagga aacagctatg 2220
accatgatta cgccaagctt gtacagacaa gaaacgcgtc agattagcgc tggttggttc 2280
ggtcgatgat atgaccagga tggagcagag acggtagttc tccgatggtc tgtggacaat 2340
cgcaggtggt gatgctccgc gggcggaaga atcgataaat tgcagaggag cagctgtccc 2400
gtttgggact agggcggggc catcatccca ccccggcaca ttaaggatga ttttcatcca 2460
tgccaccatg agctgacagt catccgatga tcatggatcc aatataccag tggctggccc 2520
cattgccttt aaaccagaag gctctaggcc cgtcgtattg gattccagac atctgatctg 2580
cgggtagctg tgatgatcgg cctacgtcta caggttcggt ctcaccacgg cttctattcc 2640
ggccgaatca ctacgggccg aagttctacg gagtacatag gatggtctta ttcgggatgt 2700
cttatcgtgg taggtaatta tagcagttgc tccaatcgta cggtgtatac gcatggtaac 2760
tcccgaagta tcaccttgtt gatgggagaa gacactcacc ggggcatgac atcacggtgt 2820
ctccatgacg tacaacacaa cagaaagccc ctccgaaagc agtattatgg ctgacttgct 2880
atatattctc tcactcactc cccttctcat attccttctc actcaggggc aactttccat 2940
ctgacccaaa atctcattcc cctttcccaa cttatttaga aacctcgtga tcgcgactcc 3000
agagctctgt cttcttccca cctgcaggtc gacatggtgc gctcctccaa gaacgtcatc 3060
aaggagttca tgcgcttcaa ggtgcgcatg gagggcaccg tgaacggcca cgagttcgag 3120
atcgagggcg agggcgaggg ccgcccctac gagggccaca acaccgtgaa gctgaaggtg 3180
accaagggcg gccccctgcc cttcgcctgg gacatcctgt ccccccagtt ccagtacggc 3240
tccaaggtgt acgtgaagca ccccgccgac atccccgact acaagaagct gtccttcccc 3300
gagggcttca agtgggagcg cgtgatgaac ttcgaggacg gcggcgtggt gaccgtgacc 3360
caggactcct ccctgcagga cggctgcttc atctacaagg tgaagttcat cggcgtgaac 3420
ttcccctccg acggccccgt aatgcagaag aagaccatgg gctgggaggc ctccaccgag 3480
cgcctgtacc cccgcgacgg cgtgctgaag ggcgagatcc acaaggccct gaagctgaag 3540
gacggcggcc actacctggt ggagttcaag tccatctaca tggccaagaa gcccgtgcag 3600
ctgcccggct actactacgt ggactccaag ctggacatca cctcccacaa cgaggactac 3660
accatcgtgg agcagtacga gcgcaccgag ggccgccacc acctgttcct gtagggtacc 3720
tcggcggaat agtgtcggac ccccggtgtt ttaagaatct tttttctctc ctcctgtttg 3780
tctatcttaa tatgaaacgg aacacggcca gggtatacgc ccgcattgtc atagaaaacg 3840
tctcaatcag aacatcatga ccaccatgga gtacagctaa aatggagccg agttgaaagc 3900
tcagcatgag catgtttaca gctactgatt aaaattcata cgagttgatg catccttctc 3960
ttcgcgtagt gaaataaaca tatatatata tataccttat gcaactgggt tgtaaagttc 4020
cgataggaga tacagggacc tgaagccttt tatcgcttgt cccgagaagc tcaccacggc 4080
ttgaagagta tcgtgacggc ttattgtgat agatcttata ttaactcttc ctttgtttca 4140
gttttgcctc accactgcat atacacaggg gttgcttggc atcttgggta aatttacgat 4200
tattttctcc agactgtata ttaatccaga gaattcactg gccgtcgttt tacaacgtcg 4260
tgactgggaa aaccctggcg ttacccaact taatcgcctt gcagcacatc cccctttcgc 4320
cagctggcgt aatagcgaag aggcccgcac cgatcgccct tcccaacagt tgcgcagcct 4380
gaatggcgaa tggcgcctga tgcggtattt tctccttacg catctgtgcg gtatttcaca 4440
ccgcatatgg tgcactctca gtacaatctg ctctgatgcc gcatagttaa gccagccccg 4500
acacccgcca acacccgctg acgcgccctg acgggcttgt ctgctcccgg catccgctta 4560
cagacaagct gtgaccgtct ccgggagctg catgtgtcag aggttttcac cgtcatcacc 4620
gaaacgcgcg a 4631
<210> 2
<211> 27
<212> DNA
<213> 人工序列
<223> Ppdc-F引物序列
<400> 2
aagcttgtac agacaagaaa cgcgtca 27
<210> 3
<211> 29
<212> DNA
<213> 人工序列
<223> Ppdc-R引物序列
<400> 3
cctgcaggtg ggaagaagac agagctctg 29
<210> 4
<211> 23
<212> DNA
<213> 人工序列
<223> Tpdc-F引物序列
<400> 4
ggtacctcgg cggaatagtg tcg 23
<210> 5
<211> 33
<212> DNA
<213> 人工序列
<223> Tpdc-R引物序列
<400> 5
gaattctctg gattaatata cagtctggag aaa 33
<210> 6
<211> 21
<212> DNA
<213> 人工序列
<223> DsRed-F引物序列
<400> 6
gtcgacatgg tgcgctcctc c 21
<210> 7
<211> 25
<212> DNA
<213> 人工序列
<223> DsRed-R引物序列
<400> 7
ggtaccctac aggaacaggt ggtgg 25
<210> 8
<211> 26
<212> DNA
<213> 人工序列
<223> CRE-F引物序列
<400> 8
gtcgacatgc cgccaccagc ctctgc 26
<210> 9
<211> 26
<212> DNA
<213> 人工序列
<223> CRE-R引物序列
<400> 9
tcgcgatcac tggcacccag aggccg 26
- 还没有人留言评论。精彩留言会获得点赞!