双拷贝EIP表达载体及其构建方法和应用与流程
本发明涉及生物
技术领域:
,尤其是涉及一种双拷贝eip表达载体及其构建方法和应用。
背景技术:
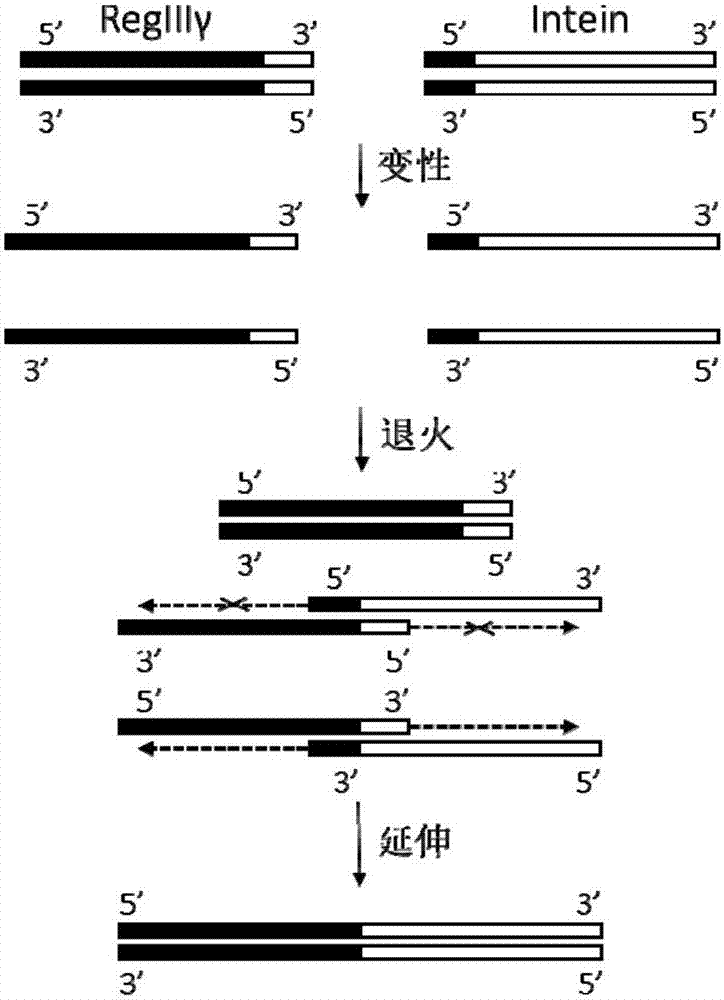
:表达载体的构建是目前分子生物学和细胞生物学等实验中最常用的实验手段。目前常用的方法在进行重组蛋白纯化时,常发生亲和层析,严重影响蛋白收率。利用eip(elastin-likepolypeptide-intein-protein)表达载体进行原核重组表达,可以在重组蛋白纯化时避免亲和层析,成本降低,时间缩短,其中:elp(elastin-likepolypeptide):弹性蛋白样多肽,由重复序列vpgxg组成(>100):x是除脯氨酸以外的任意氨基酸;室温下高度可溶,高温下容易沉淀,转变温度(tt)为30-40℃(具体tt取决于链的长度、蛋白浓度和x氨基酸的种类);i(internalprotein,intein):内含肽,是指存在于前体蛋白当中的一段序列,在前体蛋白转化为成熟蛋白质的过程中,依靠自剪接功能将内含肽两端的外显肽以肽键连接,同时将自身从前体蛋白中释放出来。内含肽从结构和功能上可以分割为n端和c端,当n端或c端单独存在时不能发生剪接反应,而只有当n端和c端在适合剪接的条件下接触时才能发生剪接反应。内含肽的特点主要为1)切割位点保守;2)具有自我催化酶切的能力;3)蛋白质内含子片段具有核酸内切酶活性。p:目标蛋白。现有的eip表达载体为单拷贝eip表达载体,eip表达系统中由于elp的分子量较大,一般为60kda以上,当目标蛋白分子量较小时,重组表达获得的目标蛋白相对于elp来说产量较低,同样会存在成本浪费的问题。因此,如何开发一种能够提高目标蛋白产量的eip表达载体,尤其是提高分子量较小的目标蛋白产量的eip表达载体尤为重要。有鉴于此,特提出本发明。技术实现要素:本发明的第一个目的在于提供一种双拷贝eip表达载体的构建方法,本发明的第二个目的在于提供应用上述构建方法构建得到的双拷贝eip表达载体,本发明的第三个目的在于提供上述双拷贝eip表达载体的应用,以缓解现有技术中存在的单拷贝eip表达载体的目标蛋白产量较低的技术问题。本发明提供了一种双拷贝eip表达载体的构建方法,所述构建方法包括:将目标蛋白基因连接到内含肽基因的n端,得到目标蛋白-内含肽基因片段,将所述目标蛋白-内含肽基因片段连接到单拷贝eip表达载体中的弹性蛋白多样肽的n端,得到所述双拷贝eip表达载体。进一步地,将所述目标蛋白基因和所述内含肽基因扩增后回收,并混合处理,得到所述目标蛋白-内含肽基因片段。进一步地,所述混合处理为将目标蛋白基因片段和内含肽基因片段混合后升温,使其变性,然后退火,得到退火产物,在所述退火产物中选取内含肽基因和目标蛋白基因的杂合子片段,加入dna聚合酶,使单链结构互补为双链结构。进一步地,所述扩增所用的引物为分别根据目标蛋白基因和内含肽基因设计的含有内切酶位点的特异性引物;所述扩增所用的模板为所述单拷贝eip表达载体。进一步地,所述内含肽基因片段的5’端引物含有17-23bp的延伸,所述17-23bp的延伸的序列与所述目标蛋白基因的3’端的序列相同。进一步地,所述目标蛋白基因片段的3’端引物含有17-23bp的延伸,所述17-23bp的延伸的序列与所述内含肽基因的5’端的序列相同。进一步地,在所述目标蛋白基因的5’端引物和所述内含肽基因的3’端引物中分别含有一个内切酶位点。进一步地,还包括通过限制性内切酶,将所述杂合子片段和所述单拷贝eip表达载体消化,回收消化产物,混合后进行连接反应,构建双拷贝eip表达载体,将所述双拷贝eip表达载体转化大肠杆菌,筛选阳性克隆。本发明还提供了一种双拷贝eip表达载体,应用上述的构建方法构建得到。另外,本发明还提供了上述双拷贝eip表达载体在扩增目标蛋白中的应用。本发明提供的双拷贝eip表达载体的构建方法,在单拷贝eip表达载体中弹性蛋白多样肽的n端连接上目标蛋白-内含肽基因片段,操作简单,实用性强。应用本发明提供的eip表达载体的构建方法构建得到的eip表达载体,与单拷贝eip表达载体相比,增加了一个拷贝的目标蛋白,达到在一个eip表达系统中含有两个拷贝的目标蛋白的目的,表达时每产生一个双拷贝eip融合蛋白分子,裂解后可产生2个目标蛋白分子,使目标蛋白的产量得到大幅提高,增加了一倍。与传统的单拷贝eip表达载体相比,在得到等量目标蛋白时,本发明提供的双拷贝eip表达载体具有节约生产成本和时间成本的优点。附图说明图1为本发明提供的双拷贝eip表达载体的示意图。图2为本发明实施例2提供的regiiiγ-intein杂合片段生成示意图。具体实施方式下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明提供了一种双拷贝eip表达载体的构建方法,包括:将目标蛋白(targetprotein)基因连接到内含肽(intein)基因的n端,得到目标蛋白-内含肽基因片段,将目标蛋白-内含肽基因片段连接到单拷贝eip表达载体中的弹性蛋白多样肽(elp)的n端,得到双拷贝eip表达载体。利用内含肽的n端和c端都具有酶切活性的特点,在elp的n端加入一个内含肽拷贝,然后在内含肽的n端再加入一个目标蛋白基因的拷贝,这样构建了双拷贝eip表达载体,表达时每产生一个eip融合蛋白分子,裂解后可产生2个目标蛋白分子,使表达量增加1倍。在本发明中,将目标蛋白基因和内含肽基因扩增后回收,混合并升温,使其变性,然后退火,得到退火产物,在退火产物中选取内含肽基因和目标蛋白基因的杂合子片段,加入dna聚合酶,使单链结构互补为双链结构,得到目标蛋白-内含肽基因片段。其中,回收为通过凝胶回收;升温的温度为94℃,退火的温度为室温。在本发明中,扩增所用的引物为分别根据目标蛋白基因和内含肽基因设计的含有内切酶位点的特异性引物;扩增所用的模板为单拷贝eip表达载体。在本发明中,内含肽基因片段的5’端引物含有17~23bp的延伸,该17~23bp的延伸序列与目标蛋白基因的3’端的序列相同,同样,目标蛋白基因片段的3’端引物含有17~23bp的延伸,该17~23bp的延伸的序列与上述内含肽基因的5’端的序列相同。这样使扩增的目标蛋白基因的3’端和内含肽基因的5’端具有34~46bp的重叠区域,这一重叠区域可用于将目标蛋白基因扩增片段与内含肽扩增片段连接起来。其中,内含肽基因片段的5’端引物的延伸长度例如可以为,但不限于17bp、18bp、19bp、20bp、21bp、22bp或23bp;目标蛋白基因片段的3’端引物的延伸长度例如可以为,但不限于17bp、18bp、19bp、20bp、21bp、22bp或23bp。扩增的目标蛋白基因的3’端和内含肽基因的5’端具有的重叠区域的长度例如可以为,但不限于34bp、35bp、36bp、37bp、38bp、39bp、40bp、41bp、42bp、43bp、44bp、45bp或46bp。在一个优选的实施方式中,内含肽基因片段的5’端引物的延伸长度为20bp;目标蛋白基因片段的3’端引物的延伸长度为20bp。扩增的目标蛋白基因的3’端和内含肽基因的5’端具有的重叠区域的长度为40bp。在本发明中,在目标蛋白基因的5’端引物前面一部分来自于peip表达载体序列,其中含有一个bamhi内切酶位点,后一部分来自于目标蛋白的5’序列,和内含肽基因的3’端引物中分别含有一个ndei内切酶位点。在内含肽基因5’端的引物将编码内含肽的第一个密码子进行突变,使其回复到编码半胱氨酸的密码子,而在内含肽基因3’端的引物中则对编码最后一个氨基酸残基的密码子进行突变,使其由原来编码天冬酰胺变成编码丙氨酸的密码子,这样得到的内含肽的n端就恢复到半胱氨酸,具有酶切活性,而c端就变为丙氨酸,失去酶切活性,如图1所示(其中,n为天冬氨酸,c为半胱氨酸,a为丙氨酸)。在本发明中,双拷贝eip表达载体的构建还包括通过限制性内切酶,将杂合子片段和单拷贝eip表达载体消化,回收消化产物,混合后进行连接反应,构建双拷贝eip表达载体,将双拷贝eip表达载体转化大肠杆菌,筛选阳性克隆。本发明还提供了一种应用上述的构建方法构建得到双拷贝eip表达载体。另外,本发明还提供了上述的双拷贝eip表达载体在扩增目标蛋白中的应用。将上述构建好的双拷贝eip表达载体转化大肠杆菌表达菌株,诱导其表达,回收细菌,裂解后收集细菌蛋白,升温的同时加盐,使融合蛋白沉淀,弃上清,将沉淀重新溶解到ph6.2左右的含有巯基的缓冲液中。其中,反应体系中的巯基能诱导eip融合蛋白n端的内含肽n端的酶切活性,ph6.2的条件则诱导eip融合蛋白c端的内含肽c端的酶切活性,将目标蛋白从融合蛋白上酶切下来,获得纯化的目标蛋白。本发明提供的双拷贝eip表达载体的构建方法,操作简单,实用性强。应用本发明提供的eip表达载体的构建方法构建得到的eip表达载体,使目标蛋白的产量得到大幅提高,增加了一倍。与传统的单拷贝eip表达载体相比,在得到等量目标蛋白时,本发明提供的双拷贝eip表达载体具有节约生产成本和时间成本的优点。为了有助于更好的理解本发明,现通过具体的实施例详细介绍如下。本发明实施例以regiiiγ蛋白为目标蛋白进行举例说明。实施例1引物设计设计两组特异性的引物,在这两组引物中,内含肽基因片段的5’端引物含有一个20bp的延伸,这20bp延伸的序列与regiiiγ基因的3’端的序列完全相同,同时,在regiiiγ基因的3’端引物也含有一个20bp的延伸,其序列与内含肽基因5’端的序列完全一样,这样使扩增的regiiiγ基因的3’端和内含肽基因的5’端具有40bp的重叠区域;在扩增regiiiγ基因的5’引物和内含肽基因的3’引物中分别含有bamhi和ndei内切酶位点。regiiiγ5’引物为:5’-gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataacgaagatag-3’(seqidno.1);其中,粗体部分来自于载体序列,后面部分来自于regiiiγ,下划线部分为bamhi内切酶。regiiiγ3’引物为:5’-cgagtgccctctgcgaggcagcctttgaatttgcaaacgt-3’(seqidno.2);其中,粗体部分来自于内含肽序列。intein5’引物为:5’-acgtttgcaaattcaaaggctgcctcgcagagggcactcg-3’(seqidno.3);其中,粗体部分来自于regiiiγ序列。intein3’引物为:5’-gcccatatgattatgtacaacaaccccttc-3’(seqidno.4);其中,下划线部分为ndei内切酶。在内含肽基因5’引物将编码内含肽的第一个密码子进行突变,使其回复到编码半胱氨酸的密码子,而在内含肽基因3’引物中则对编码最后一个氨基酸残基的密码子进行突变,使其由原来编码天冬酰胺变成编码丙氨酸的密码子,这样得到的内含肽的n端就恢复到半胱氨酸,具有酶切活性,而c端就变为丙氨酸,失去酶切活性。实施例2pcr扩增和连接①通过本发明实施例1设计的引物,以单拷贝eip载体为模板,通过pcr分步扩增内含肽和regiiiγ基因片段。其中,pcr反应体系为:试剂体积(μl)pcr反应混合物22模板1上游引物1下游引物1pcr反应条件为:②将pcr产物进行琼脂糖凝胶电泳后,确认目的扩增条带分子量准确,采用dna凝胶回收试剂盒回收pcr扩增片段,测定a260/280并进行定量;其中,regiiiγ的扩增序列(527bp)为:5’-gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataacgaagatagtccggcagataccccgtctgcacgtattagctgtccgaaaggtagcatggcgtacgcgtcttattgctatgcgctgttcattaccccgaaaacctggatgggcgcagatatggcttgccaaaaacgtccgtctggtcatctggcgagcgtgctgtctggtgcagaagcgagctttgttagcagcctgattaaaaacaacctgaacgcgctgagcgacgtttggattggtctgcacgatccgaccgaaggtctggaaccgaacgctggcggttgggagtggagtagctccgacgttctgaattacgttgcctgggaacgtaacccgagtacctctagctatccgggttattgcggttctctgtctcgtaacaccggctatctgaaatggcgcgattacaactgctacgtcaacctgccgtacgtttgcaaattcaaaggctgcctcgcagagggcactcg-3’(seqidno.5);其中,下划线部分为bamhi内切酶。内含肽的扩增序列(533bp)为:5’-acgtttgcaaattcaaaggctgcctcgcagagggcactcggatcttcgatccggtcaccggtacaacgcatcgcatcgaggatgttgtcggtgggcgcaagcctattcatgtcgtggctgctgccaaggacggaacgctgcatgcgcggcccgtggtgtcctggttcgaccagggaacgcgggatgtgatcgggttgcggatcgccggtggcgccatcctgtgggcgacacccgatcacaaggtgctgacagagtacggctggcgtgccgccggggaactccgcaagggagacagggtggcgcaaccgcgacgcttcgatggattcggtgacagtgcgccgattccggcgcgcgtgcaggcgctcgcggatgccctggatgacaaattcctgcacgacatgctggcggaagaactccgctattccgtgatccgagaagtgctgccaacgcggcgggcacgaacgttcggcctcgaggtcgaggaactgcacaccctcgtcgccgaaggggttgttgtacataatcatatgggc-3’(seqidno.6);其中,下划线部分为ndei内切酶。上述seqidno.5及seqidno.6所示的序列中粗体部分为重叠区域。③将两个扩增片段按分子比1:1混合后升温至94℃,使其变性成单链,然后置于室温退火,在退火产物中加入dna聚合酶,72℃处理1min,由于dna合成时只能从5’向3’方向延伸,只有内含肽和regiiiγ基因的杂合子片段才能延伸,产生1020bp的双链杂合子,得到连接在一起的目标蛋白-内含肽(regiiiγ-intein)基因片段,如图2所示。其中,regiiiγ-intein序列(1020bp)为:gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataacgaagatagtccggcagataccccgtctgcacgtattagctgtccgaaaggtagcatggcgtacgcgtcttattgctatgcgctgttcattaccccgaaaacctggatgggcgcagatatggcttgccaaaaacgtccgtctggtcatctggcgagcgtgctgtctggtgcagaagcgagctttgttagcagcctgattaaaaacaacctgaacgcgctgagcgacgtttggattggtctgcacgatccgaccgaaggtctggaaccgaacgctggcggttgggagtggagtagctccgacgttctgaattacgttgcctgggaacgtaacccgagtacctctagctatccgggttattgcggttctctgtctcgtaacaccggctatctgaaatggcgcgattacaactgctacgtcaacctgccgtacgtttgcaaattcaaaggctgcctcgcagagggcactcggatcttcgatccggtcaccggtacaacgcatcgcatcgaggatgttgtcggtgggcgcaagcctattcatgtcgtggctgctgccaaggacggaacgctgcatgcgcggcccgtggtgtcctggttcgaccagggaacgcgggatgtgatcgggttgcggatcgccggtggcgccatcctgtgggcgacacccgatcacaaggtgctgacagagtacggctggcgtgccgccggggaactccgcaagggagacagggtggcgcaaccgcgacgcttcgatggattcggtgacagtgcgccgattccggcgcgcgtgcaggcgctcgcggatgccctggatgacaaattcctgcacgacatgctggcggaagaactccgctattccgtgatccgagaagtgctgccaacgcggcgggcacgaacgttcggcctcgaggtcgaggaactgcacaccctcgtcgccgaaggggttgttgtacataatcatatgggc(seqidno.7)。其中,下划线部分为bamhi内切酶。④将产物进行dna琼脂糖凝胶电泳,采用同样的方法回收目的片段。实施例3载体构建①将本发明实施例2提供的杂合子(regiiiγ-intein)片段和单拷贝eip表达载体分别用bamhi和ndei限制性内切酶进行双酶切(37℃,1小时),暴露两端的bamhi和ndei粘性末端;②通过琼脂糖凝胶电泳,采用天根公司的dna凝胶回收试剂盒回收目的片段,将其按杂合子片段分子数:单拷贝eip载体片段分子数(5:1)混合后加入dnat4连接酶(4℃,1小时),进行连接反应。③取100μl大肠杆菌dh5α的感受细胞加入到一个1.5ml离心管中,置于冰上,然后加入10μl连接反应物,置于冰上40min;④将离心管置于42℃水浴42s热激处理后置于冰上5min;⑤加入预热到37℃的900μllb培养基,将离心管转移到摇床培养(37℃,200rpm,60min);⑥取上述100μl培养物涂布到预热到37℃的含有氨苄青霉素(50mg/ml)lb琼脂平板上,于37℃培养过夜;⑦通过pcr筛选含有regiiiγ-intein插入片段的阳性克隆;⑧利用天根公司的质粒提取试剂盒从阳性克隆中提取重组质粒表达载体,测序鉴定序列准确后采用同样的方法转化大肠杆菌表达菌株de3。实施例4重组表达与纯化①将本发明实施例3提供的构建好的载体转化大肠杆菌表达菌株de3在含氨苄青霉素(100mg/ml)的lb平板上划线后37℃培养过夜;②挑取单菌落,加入到含氨苄青霉素(100mg/ml)5mllb液体培养基中,37℃摇床培养过夜(200rpm);③取50μl上述过夜培养物加入到含氨苄青霉素(100mg/ml)的5mllb液体培养基中,37℃摇床培养(200rpm)3~4小时至od600约为0.6左右,冷却到18~22℃;④加入iptg(1mg/ml),于18~22℃培养24小时,诱导重组蛋白的表达。⑤取1ml细菌培养物加入到1.5ml离心管中,离心收集细菌(4℃,12,000rpm,2min),去掉培养基后将收集到的细菌置于-80℃长期保存。⑥加入细菌裂解缓冲液(10mmtris-hcl,ph8.5,2mmedta,0.1mgml/l溶菌酶),冰上处理50min,-20℃冻藏处理过夜;⑦将冻藏处理的细菌进行超声处理,裂解细菌后离心收集蛋白(14,000rpm,4℃,6min),后收集上清,内含重组融合蛋白;⑧将上清加入nacl至终浓度0.4mol/l,加热至37℃,使重组融合蛋白沉淀,离心(14,000rpm,37℃,6min)后弃上清;⑨将沉淀重新溶解到pbs缓冲液(pbs缓冲液,40mmol/lbis-tris,ph6.2,10mmol/ldtt)中,20℃放置过夜,inteinn端巯基诱导和c端ph诱导的酶切活性将regiiiγ蛋白从融合蛋白中切除下来;⑩离心(14,000rpm,4℃,6min)弃沉淀,纯化的重组蛋白regiiiγ存在于上清中。最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。sequencelisting<110>湖南农业大学<120>双拷贝eip表达载体及其构建方法和应用<160>7<170>patentinversion3.5<210>1<211>68<212>dna<213>人工序列<400>1gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataac60gaagatag68<210>2<211>40<212>dna<213>人工序列<400>2cgagtgccctctgcgaggcagcctttgaatttgcaaacgt40<210>3<211>40<212>dna<213>人工序列<400>3acgtttgcaaattcaaaggctgcctcgcagagggcactcg40<210>4<211>30<212>dna<213>人工序列<400>4gcccatatgattatgtacaacaaccccttc30<210>5<211>527<212>dna<213>regiiiγ蛋白<400>5gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataac60gaagatagtccggcagataccccgtctgcacgtattagctgtccgaaaggtagcatggcg120tacgcgtcttattgctatgcgctgttcattaccccgaaaacctggatgggcgcagatatg180gcttgccaaaaacgtccgtctggtcatctggcgagcgtgctgtctggtgcagaagcgagc240tttgttagcagcctgattaaaaacaacctgaacgcgctgagcgacgtttggattggtctg300cacgatccgaccgaaggtctggaaccgaacgctggcggttgggagtggagtagctccgac360gttctgaattacgttgcctgggaacgtaacccgagtacctctagctatccgggttattgc420ggttctctgtctcgtaacaccggctatctgaaatggcgcgattacaactgctacgtcaac480ctgccgtacgtttgcaaattcaaaggctgcctcgcagagggcactcg527<210>6<211>533<212>dna<213>内含肽(intein)<400>6acgtttgcaaattcaaaggctgcctcgcagagggcactcggatcttcgatccggtcaccg60gtacaacgcatcgcatcgaggatgttgtcggtgggcgcaagcctattcatgtcgtggctg120ctgccaaggacggaacgctgcatgcgcggcccgtggtgtcctggttcgaccagggaacgc180gggatgtgatcgggttgcggatcgccggtggcgccatcctgtgggcgacacccgatcaca240aggtgctgacagagtacggctggcgtgccgccggggaactccgcaagggagacagggtgg300cgcaaccgcgacgcttcgatggattcggtgacagtgcgccgattccggcgcgcgtgcagg360cgctcgcggatgccctggatgacaaattcctgcacgacatgctggcggaagaactccgct420attccgtgatccgagaagtgctgccaacgcggcgggcacgaacgttcggcctcgaggtcg480aggaactgcacaccctcgtcgccgaaggggttgttgtacataatcatatgggc533<210>7<211>1020<212>dna<213>人工序列<400>7gtaggatccaataattttgtttaactttaagaaggagatatagatatggtggtgcataac60gaagatagtccggcagataccccgtctgcacgtattagctgtccgaaaggtagcatggcg120tacgcgtcttattgctatgcgctgttcattaccccgaaaacctggatgggcgcagatatg180gcttgccaaaaacgtccgtctggtcatctggcgagcgtgctgtctggtgcagaagcgagc240tttgttagcagcctgattaaaaacaacctgaacgcgctgagcgacgtttggattggtctg300cacgatccgaccgaaggtctggaaccgaacgctggcggttgggagtggagtagctccgac360gttctgaattacgttgcctgggaacgtaacccgagtacctctagctatccgggttattgc420ggttctctgtctcgtaacaccggctatctgaaatggcgcgattacaactgctacgtcaac480ctgccgtacgtttgcaaattcaaaggctgcctcgcagagggcactcggatcttcgatccg540gtcaccggtacaacgcatcgcatcgaggatgttgtcggtgggcgcaagcctattcatgtc600gtggctgctgccaaggacggaacgctgcatgcgcggcccgtggtgtcctggttcgaccag660ggaacgcgggatgtgatcgggttgcggatcgccggtggcgccatcctgtgggcgacaccc720gatcacaaggtgctgacagagtacggctggcgtgccgccggggaactccgcaagggagac780agggtggcgcaaccgcgacgcttcgatggattcggtgacagtgcgccgattccggcgcgc840gtgcaggcgctcgcggatgccctggatgacaaattcctgcacgacatgctggcggaagaa900ctccgctattccgtgatccgagaagtgctgccaacgcggcgggcacgaacgttcggcctc960gaggtcgaggaactgcacaccctcgtcgccgaaggggttgttgtacataatcatatgggc1020当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 带Flag标签的LAMP1真核表达载体及其在溶酶体分离中的应用
- 带ha标签的lamp1真核表达载体及其在溶酶体分离中的应用
- 重组人cc16基因、其真核表达载体的构建及重组蛋白的纯化的制作方法
- pVAX-PTX3真核表达载体、构建方法及所表达的PTX3蛋白对猪链球菌2型的抗菌应用
- 作为体外检测试剂的真核通用表达载体系统及其构建方法
- 人胱抑素c真核表达载体的构建及其表达、纯化的制作方法
- 一种标记细胞骨架蛋白的多肽及其真核表达载体的制作方法
- hALR基因微环真核表达载体在降低肝脏胶原蛋白合成方面的应用的制作方法
- 重组肿瘤抑素-肿瘤坏死因子分泌型真核表达载体及其制备方法和用途的制作方法
- 人ski基因真核表达载体、制备方法及其应用的制作方法